







Hi there! This webpage covers the space and time Big-O complexities of common algorithmsused in Computer Science. When preparing for technical interviews in the past, I found myself spending hours crawling the internet putting together thebest, average, and worst case complexities for search and sorting algorithms sothat I wouldn't be stumped when asked about them. Over the last fewyears, I've interviewed at several Silicon Valley startups, and also somebigger companies, like Yahoo, eBay, LinkedIn, and Google, and each time that Iprepared for an interview, I thought to myself "Why oh why hasn't someonecreated a nice Big-O cheat sheet?". So, to save all of you finefolks a ton of time, I went ahead and created one. Enjoy!
| Good | Fair | Poor |
Searching
| Algorithm | Data Structure | Time Complexity | Space Complexity | |
|
|
| Average | Worst | Worst |
| Graph of |V| vertices and |E| edges | - | O(|E| + |V|) | O(|V|) | |
| Graph of |V| vertices and |E| edges | - | O(|E| + |V|) | O(|V|) | |
| Sorted array of n elements | O(log(n)) | O(log(n)) | O(1) | |
| Array | O(n) | O(n) | O(1) | |
| Shortest path by Dijkstra, | Graph with |V| vertices and |E| edges | O((|V| + |E|) log |V|) | O((|V| + |E|) log |V|) | O(|V|) |
| Shortest path by Dijkstra, | Graph with |V| vertices and |E| edges | O(|V|^2) | O(|V|^2) | O(|V|) |
| Graph with |V| vertices and |E| edges | O(|V||E|) | O(|V||E|) | O(|V|) | |
Sorting
| Algorithm | Data Structure | Time Complexity | Worst Case Auxiliary Space Complexity | ||
|
|
| Best | Average | Worst | Worst |
| Array | O(n log(n)) | O(n log(n)) | O(n^2) | O(n) | |
| Array | O(n log(n)) | O(n log(n)) | O(n log(n)) | O(n) | |
| Array | O(n log(n)) | O(n log(n)) | O(n log(n)) | O(1) | |
| Array | O(n) | O(n^2) | O(n^2) | O(1) | |
| Array | O(n) | O(n^2) | O(n^2) | O(1) | |
| Array | O(n^2) | O(n^2) | O(n^2) | O(1) | |
| Array | O(n+k) | O(n+k) | O(n^2) | O(nk) | |
| Array | O(nk) | O(nk) | O(nk) | O(n+k) | |
Data Structures
| Data Structure | Time Complexity | Space Complexity | |||||||
|
| Average | Worst | Worst | ||||||
|
| Indexing | Search | Insertion | Deletion | Indexing | Search | Insertion | Deletion |
|
| O(1) | O(n) | - | - | O(1) | O(n) | - | - | O(n) | |
| O(1) | O(n) | O(n) | O(n) | O(1) | O(n) | O(n) | O(n) | O(n) | |
| O(n) | O(n) | O(1) | O(1) | O(n) | O(n) | O(1) | O(1) | O(n) | |
| O(n) | O(n) | O(1) | O(1) | O(n) | O(n) | O(1) | O(1) | O(n) | |
| O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) | O(n) | O(n) | O(n) | O(n log(n)) | |
| - | O(1) | O(1) | O(1) | - | O(n) | O(n) | O(n) | O(n) | |
| O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) | O(n) | O(n) | O(n) | O(n) | |
| - | O(log(n)) | O(log(n)) | O(log(n)) | - | O(n) | O(n) | O(n) | O(n) | |
| O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) | |
| O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) | |
| - | O(log(n)) | O(log(n)) | O(log(n)) | - | O(log(n)) | O(log(n)) | O(log(n)) | O(n) | |
| O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) | |
Heaps
| Heaps | Time Complexity |
| ||||||
|
| Heapify | Find Max | Extract Max | Increase Key | Insert | Delete | Merge |
|
| - | O(1) | O(1) | O(n) | O(n) | O(1) | O(m+n) | ||
| - | O(n) | O(n) | O(1) | O(1) | O(1) | O(1) | ||
| O(n) | O(1) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(m+n) | ||
| - | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | ||
| - | O(1) | O(log(n))* | O(1)* | O(1) | O(log(n))* | O(1) | ||
Graphs
| Node / Edge Management | Storage | Add Vertex | Add Edge | Remove Vertex | Remove Edge | Query |
| O(|V|+|E|) | O(1) | O(1) | O(|V| + |E|) | O(|E|) | O(|V|) | |
| O(|V|+|E|) | O(1) | O(1) | O(|E|) | O(|E|) | O(|E|) | |
| O(|V|^2) | O(|V|^2) | O(1) | O(|V|^2) | O(1) | O(1) | |
| O(|V| ⋅ |E|) | O(|V| ⋅ |E|) | O(|V| ⋅ |E|) | O(|V| ⋅ |E|) | O(|V| ⋅ |E|) | O(|E|) |
Notation forasymptotic growth
| letter | bound | growth |
| (theta) Θ | upper and lower, tight[1] | equal[2] |
| (big-oh) O | upper, tightness unknown | less than or equal[3] |
| (small-oh) o | upper, not tight | less than |
| (big omega) Ω | lower, tightness unknown | greater than or equal |
| (small omega) ω | lower, not tight | greater than |
[1] Big O is theupper bound, while Omega is the lower bound. Theta requires both Big O andOmega, so that's why it's referred to as a tight bound (it must be both theupper and lower bound). For example, an algorithm taking Omega(n log n) takesat least n log n time but has no upper limit. An algorithm taking Theta(n logn) is far preferential since it takes AT LEAST n log n (Omega n log n) and NOMORE THAN n log n (Big O n log n).SO
[2] f(x)=Θ(g(n))means f (the running time of the algorithm) grows exactly like g when n (inputsize) gets larger. In other words, the growth rate of f(x) is asymptoticallyproportional to g(n).
[3] Same thing.Here the growth rate is no faster than g(n). big-oh is the most useful becauserepresents the worst-case behavior.
In short, if algorithm is __ then its performance is __
| algorithm | performance |
| o(n) | < n |
| O(n) | ≤ n |
| Θ(n) | = n |
| Ω(n) | ≥ n |
| ω(n) | > n |
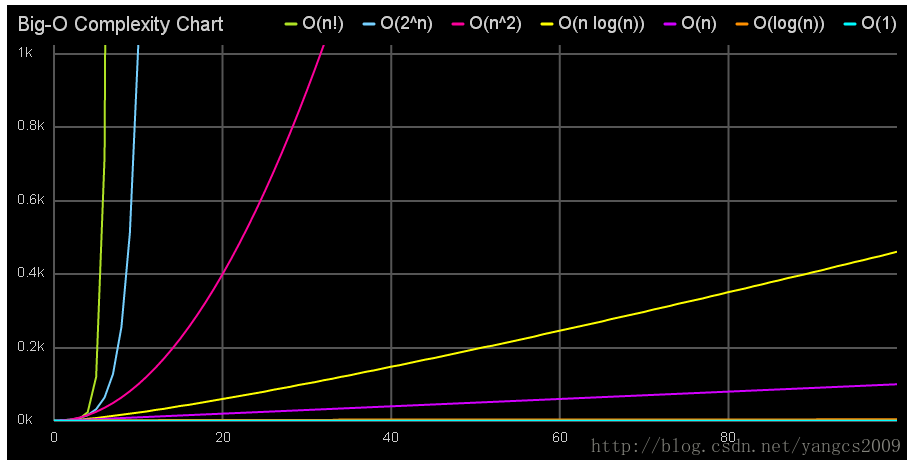
Big-O Complexity Chart
This interactive chart, created by our friends over at MeteorCharts, shows the number of operations (y axis) required to obtain a result as the number of elements (x axis) increase. O(n!) is the worst complexity which requires 720 operations for just 6 elements, while O(1) is the best complexity, which only requires a constant number of operations for any number of elements.
转 http://bigocheatsheet.com/
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









