










最近接手维护一个日志系统,它用于对应用服务器上的日志进行收集然后提供实时分析、处理并最后将日志存储到目标存储引擎。针对这三个环节,业界已经有一套组件来应对各自的需求需求,它们是flume+kafka+hdfs/hbase。我们在实时分析、存储这两个环节,选择跟业界的实践相同,但agent是团队自己写的,出于对多种数据源的扩展需求以及原来收集日志的方式存在的一些不足,于是调研了一下flume的agent。结果是flume非常契合我们的实际需求,并且拥有良好的扩展性与稳定性。于是打算采用flume的agent替换我们原先的实现。
本文介绍我们如何使用flume agent以及为了满足我们的需求进行了哪些扩展。备注:全文所指的flume均指flume-ng,版本基于1.6.0。
flume简介
flume 通过Agent对各个服务器上的日志进行收集,它依赖三大核心组件,它们分别是:source,channel,sink。它们之间的串联关系如下图:
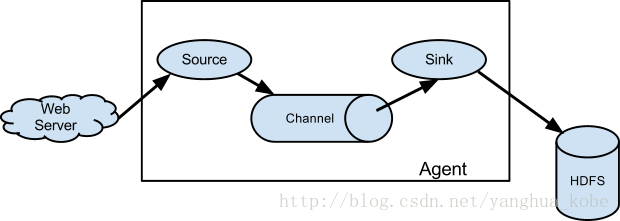
之间的关系也比较简单:source负责应对各种数据源进行日志收集;channel负责日志的中间暂存,将日志收集跟日志发送解耦;sink负责日志的发送,将日志发送到目的地。更详细的讲解,请移步官网。下面谈谈,我们对flume的使用与扩展。
Source的扩展
Flume提供了一个基于跟踪文件夹内“文件个数”变动的source称之为Spool Directory Source。它跟踪目标日志文件夹,当有新的日志文件产生时就会触发对新日志文件的收集,但它不支持日志文件的追加。也就是说一旦它开始收集某个日志文件,那么这个日志文件就不能再被编辑,如果在读取日志文件的时候,日志文件产生了变动那么它将会抛出异常。也就是说,当收集到当日日志文件时,同时又有新的日志在往里面写入时,该source是不适合这种需求的。
如果你的需求是接近“准实时”的日志收集并且你非要用这个souce,应对的方案是:你只能选择将应用程序的日志框架(比如常用的log4j)的appender的“滚动机制”设置为按分钟滚动(也就是每分钟产生一个新日志文件)。这种机制不是不可行,但有些不足的地方,比如日志文件过多:当日志除了要被日志系统收集,还需要本地保留时,这种机制将非常难以接受。
我们希望日志文件按天滚动产生新的日志文件,当天的日志以追加的方式写入当天的日志文件并且Agent还要能够以接近实时的速度收集新产生的日志(追加)的。如果agent挂掉或者服务器宕机,日志文件不能丢失,agent能够自动跨日期收集。其实,spooling directory source已经为我们的实现提供了模板,但要进行一些改造,主要是以下几点:
(1)原先的Spooling Directory Source不支持对收集的日志文件的内容进行追加:
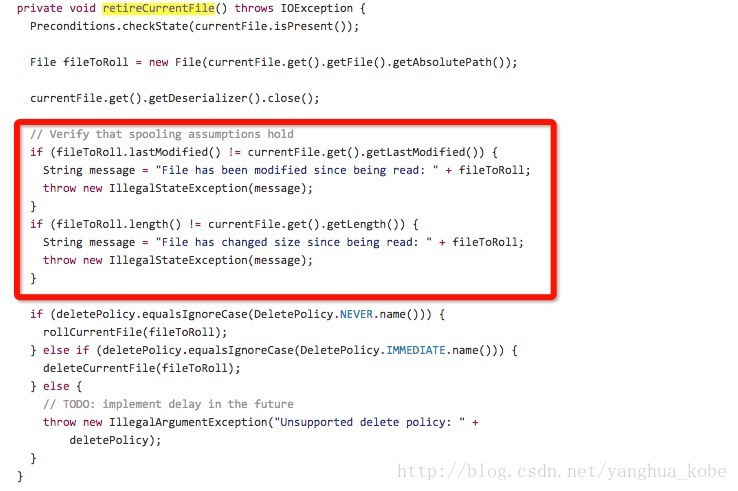
如果文件有任何改动,将以异常的形式抛出。此处需要移除异常
(2)对当日日志文件进行持续监控
原先的实现,当获取不到event直接删除或者重命名当前文件,并自动混动到下一个文件:
/* It's possible that the last read took us just up to a file boundary.
* If so, try to roll to the next file, if there is one. */
if (events.isEmpty()) {
retireCurrentFile();
currentFile = getNextFile();
if (!currentFile.isPresent()) {
return Collections.emptyList();
}
events = currentFile.get().getDeserializer().readEvents(numEvents);
}修改后的实现,当当前文件不是当天的日志文件时才处理当前文件并自动滚动到下一个文件,如果是当日文件,则继续跟踪:
if(!isTargetFile(currentFile) // Only CurrentFile is no longer the target, at the meanwhile, next file exists.
&& (isExistNextFile()) ){ // Then deal with the history file(ever target file)
logger.info("File:{} is no longer a TARGET File, which will no longer be monitored.", currentFile.get().getFile().getName());
retireCurrentFile();
currentFile = getNextFile();
}flume 该source的源码见: github。
另外此处,我们判断是否是目标文件(当日日志文件)的处理方式是比对服务器日期跟文件名中包含的日期是否一致:
private boolean isTargetFile(Optional<FileInfo> currentFile2) {
String inputFilename = currentFile2.get().getFile().getName();
SimpleDateFormat dateFormat = new SimpleDateFormat(targetFilename);
String substringOfTargetFile = dateFormat.format(new Date());
if(inputFilename.toLowerCase().contains(substringOfTargetFile.toLowerCase())){
return true;
}
return false;
}所以在新的配置里还需要加入日期格式的配置,通常是:yyyy-MM-dd。
Sink 的扩展
Sink在Flume的agent组件中充当数据输出的作用。在flume之前的版本(1.5.2)中已经对多个数据持久化系统提供了内置支持(比如hdfs/HBase等),但默认是没有kafka的。如果我们想将日志消息发送到kafka,就需要自己扩展一个kafkaSink。后来通过搜索发现在最新的stable release版本:1.6.0中,官方已经集成了kafkaSink。不过1.6.0是5月20号刚刚发布,官方的Download页面以及User Guide还没有进行更新,所以请在版本列表页面下载1.6.0版本。在下载到的安装包内有最新的KafkaSink介绍。
核心的配置有:brokerList(为了高可用性,flume建议至少填写两个broker配置)、topic。详见列表:

出于好奇心,在github上大概浏览了官方实现kafkaSink的源码,发现Event的Header部分并没有被打包进消息发送走:
byte[] eventBody = event.getBody();
Map<String, String> headers = event.getHeaders();
if ((eventTopic = headers.get(TOPIC_HDR)) == null) {
eventTopic = topic;
}
eventKey = headers.get(KEY_HDR);
if (logger.isDebugEnabled()) {
logger.debug("{Event} " + eventTopic + " : " + eventKey + " : "
+ new String(eventBody, "UTF-8"));
logger.debug("event #{}", processedEvents);
}
// create a message and add to buffer
KeyedMessage<String, byte[]> data = new KeyedMessage<String, byte[]>
(eventTopic, eventKey, eventBody);
messageList.add(data);这一点,可能并不满足我们的需求:我们需要消息头里的信息成为消息的一部分,然后在storm里针对header信息进行一些处理。比如:
(1)我们会默认在头里加入产生日志的服务器的Host,以便对日志进行分流或对没有存储host的日志进行“补偿”
(2)我们会默认在头里加入日志类型的标识,以便区分不同的日志并分流到不同的解析器进行解析
因为日志的来源以及形式是多样的,所以header里这些携带的信息是必要的。而flume官方的KafkaSink却过滤掉了header中的信息。因此,我们选择对其进行简单的扩张,将Event的header跟body打包成一个完整的json对象。具体的实现:
private byte[] generateCompleteMsg(Map<String, String> header, byte[] body) {
LogMsg msg = new LogMsg();
msg.setHeader(header);
msg.setBody(new String(body, Charset.forName("UTF-8")));
String tmp = gson.toJson(msg, LogMsg.class);
logger.info(" complete message is : " + tmp);
return tmp.getBytes(Charset.forName("UTF-8"));
} // create a message and add to buffer
KeyedMessage<String, byte[]> data = new KeyedMessage<String, byte[]>
(eventTopic, eventKey, generateCompleteMsg(headers, eventBody));
messageList.add(data);Interceptor使用
上面提到日志的源以及格式多种多样,我们不可能将所有工具、组件的日志格式按照我们想要的方式作格式化,特别是一些封闭的组件或线上的系统。很显然source跟sink只负责日志的收集和发送,并不会区分日志内容。而flume提供的Interceptor这一功能,给flume提供了更强大的扩展性。而我们拦击日志,并给其添加特定的header就是通过flume内置的几个interceptor实现的。我们应用了这么几个interceptor:
(1)host:往header中设置当前主机的Host信息;
(2)static:往header中设置一个预先配好的key-value对,我们用它来鉴别不同的日志源
(3)regex:通过将Event的body转换成一个UTF-8的字符串,然后匹配正则表达式,如果匹配成功,则可以选择放行或者选择删除
前两个interceptor我们之前已经提及过它的用途,而第三个我们用它来匹配日志中是否存在“DEGUG”字样的tag,如此存在,则删除该日志(这个是可选的)。
Selector 的使用
目前没有使用Selector的需求,不过它的用途也很常见:它可以用来选择Channel,如果你有多个Channel,并且是有条件得选择性发送的情况下,可以使用Selector来提高日志收集的灵活性。比如:如果你需要将不同不同日志源的日志发往不同的目的地可以建立多个channel然后按一定的规则来匹配,这里主要用到Multiplexing Channel Selector。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









