






以下是我学习的几个博文:
http://www.cnblogs.com/wengzilin/p/3849118.html
http://www.cnblogs.com/wengzilin/p/3845271.html
http://www.cnblogs.com/tornadomeet/archive/2012/03/28/2420936.html
http://blog.csdn.net/u010603823/article/details/52557760
1.准备训练样本图片
1.1样本的采集:
样本图片最好使用灰度图,且最好根据实际情况做一定的预处理;样本数量越多越好,尽量高于1000,样本间差异性越大越好
正负样本比例为1:3最佳;尺寸为20x20最佳。
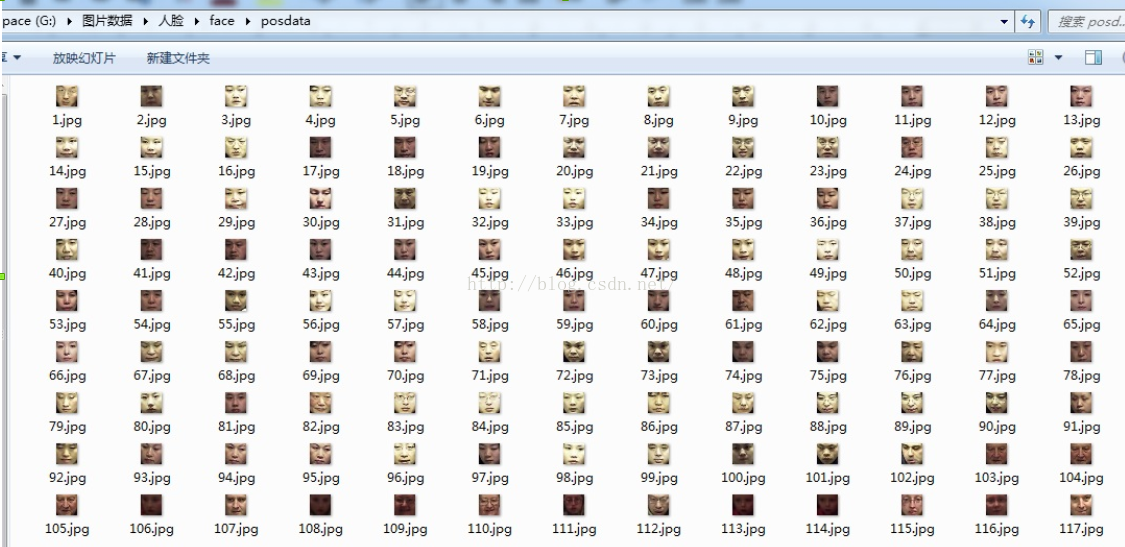
1.1.1正样本
训练样本的尺寸为20*20(opencv推荐的最佳尺寸),且所有样本的尺寸必须一致。如果不一致的或者尺寸较大的,可以先将所有样本统一缩放到20*20。
以下就是我用来训练的正样本:
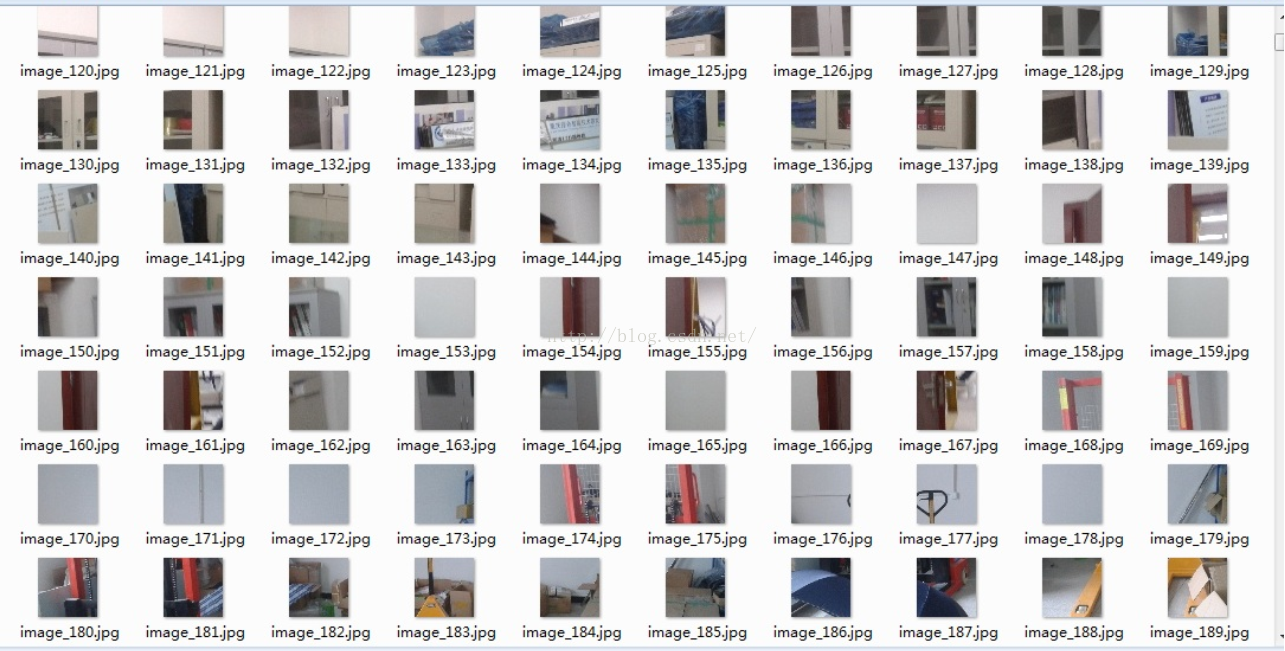
这里要提醒一下,虽然负样本就是样本中不存在正样本的内容。但也不能随意的找些图片来作为负样本,比如什么天空,大海,森林等等。最好是根据不同的项目选择不同的负样本,比如一个项目是做机场的人脸检测,那么就最好从现场拍摄一些图片数据回来,从中采集负样本。其实正样本的采集也应该这样。不同的项目,就采集不同的正样本和负样本。因为项目不同,往往相机的安装规范不同,场景的拍摄角度就不同。
关于负样本的尺寸,只要不小于正样本的尺寸就好。至于为什么,我没有深究,知道原因的也可以讲讲。
以下就是我用来训练的负样本:
1.1.3 准备好工作目录
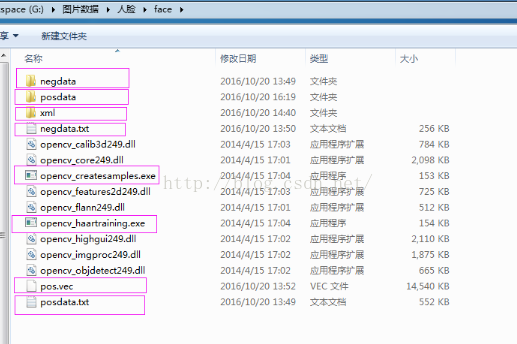
negdata目录: 放负样本的目录
posdata目录: 放正样本的目录
xml目录: 新建的一个目录,为之后存放分类器文件使用
negdata.txt: 负样本路径列表
posdata.txt: 正样本路径列表
pos.vec: 后续自动生成的样本描述文件
opencv_createsamples.exe: 生成样本描述文件的可执行程序(opencv自带)
opencv_haartraining.exe: 样本训练的可执行程序(opencv自带)
1.1.4获取样本路径列表
接下来就需要或者正负样本的路径列表,方便训练的时候能够找到每一个样本。
先进入正样本数据的目录下(posdata目录),新建一个文本文档,然后把文件扩展名修改为bat,然后编辑文本如下:
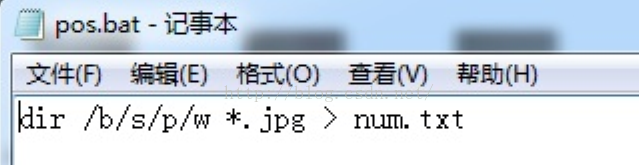
编辑完成后,双击该文件。就会在该目录下生成一个num.txt,如下:

打开num.txt,使用文本编辑器的替换功能,做一些替换工作
替换1:将绝对路径替换成相对路径
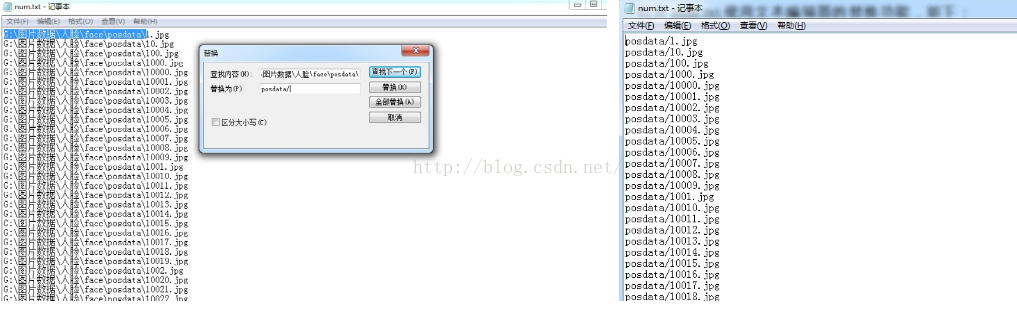
替换2:1代表个数,后四个分别对应left top width height
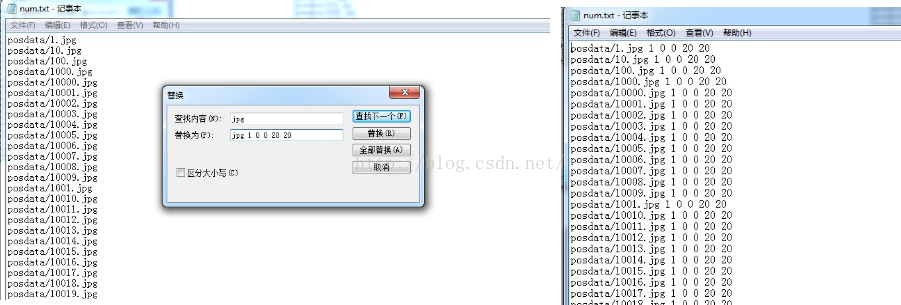
将替换好的num.txt复制到posdata目录的同级目录下,重命名为posdata.txt
同理,负样本的路径列表按照上述方法进行。在negdata目录下准备好num.txt后,复制到negdata目录的同级目录下,重命令为negdata.txt
2.准备样本描述文件
样本描述文件就是一个.vec文件,为opencv训练准备的,只有正样本需要,负样本不需要。
打开cmd.exe,进入到工作目录下,执行以下命令:
|
|
| -info,指样本说明文件 -vec,样本描述文件的名字及路径 -num,总共几个样本,要注意,这里的样本数是指标定后的20x20的样本数,而不是大图的数目,其实就是样本说明文件第2列的所有数字累加 -w-h指明想让样本缩放到什么尺寸。这里的奥妙在于你不必另外去处理第1步中被矩形框出的图片的尺寸,因为这个参数帮你统一缩放!(我们这里准备的样本都是20*20) |
执行结束后,会在工作目录下自动生成一个pos.vec文件
3.样本训练
样本训练需要用到的工具:(1)opencv_haartraining.exe,opencv自带的一个工具,该工具封装了haar特征提取以及adaboost分类器训练过程 (2)convert_casade.exe,用于合并各级分类器成为最终的xml文件.
打开cmd.exe,进入工作目录,执行以下命令
| opcnv_haartraining.exe–data xml –vec pos.vec –bg negdata.txt –nsplits 1 –sym –w24 –h 24 –mode all –mem 1280 |
| -data: 指定生成的文件目录(将来存放各级分类的地方) -vec: 样本描述文件
-bg 负样本描述文件名称,就是负样本的路径列表
-nstage 20 指定训练层数,推荐15~20,层数越高,耗时越长。
-nsplits 分裂子节点数目,选取默认值 2 , 1表示使用简单的stump classfier分类
-minhitrate 最小命中率,即训练目标准确度。
-maxfalsealarm 最大虚警(误检率),每一层训练到这个值小于0.5时训练结束,进入下一层训练
-npos 在每个阶段用来训练的正样本数目
-nneg 在每个阶段用来训练的负样本数目
-mode: all指定haar特征的种类,basic仅仅使用垂直特征,all表示使用垂直以及45度旋转特征
-sym或者-nonsym:后面不用跟其他参数,用于指定目标对象是否垂直对称,若你的对象是垂直对称的,比如脸,则垂直对称有利于提高训练速度 -mem: 表示允许使用计算机的1280M内存 |
3.1训练过程
在训练过程中可能会遇到很多问题,大家如果遇到什么问题,就直接到网搜,肯定是搜得到的,我这里把我遇到的问题贴出来,我开始训练后,大约过了20几分钟,程序就卡住了,感觉进入死循环,出不来了。如下图所示。
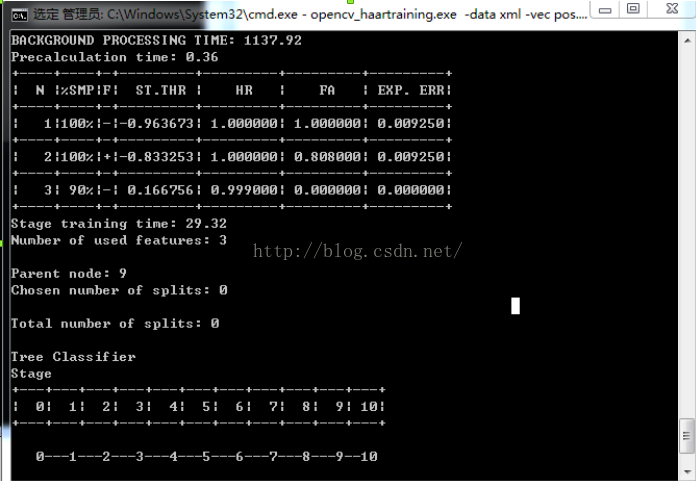
但是进入xml目录下,已经生成了10个目录(这10个就是弱分类器),通过网上查找,解决如下:
训练到第10层后再也没有反应,这是由于FA值已经达到0,没有负样本能够进入下一层进行训练了。
解决方案之一是增加负样本的数量。
解决方案之二是用convert_cascade.exe生成xml文件。因为此时各层的训练信息已经有了,FA值达到0也说明训练结果可用。同样 适用于FA值已经很低,而下一层的训练时间过长不想等待的情况。
因为没有找到convert_cascade.exe这个可执行文件,在网上搜到了这个源代码,将其写成一个函数,然后直接调用即可,代码如下
| intcascade() { char*haartraining_ouput_dir ="G://图片数据//人脸//face//xml"; //根据实际情况修改 char*ouput_file ="G://图片数据//人脸//face//xml//haar_adaboost.xml";//根据实际情况修改
constchar*size_opt = "--size="; charcomment[1024]; CvHaarClassifierCascade*cascade = 0; CvSizesize;
size.width= 20; //根据实际情况修改 size.height= 20; //根据实际情况修改
cascade= cvLoadHaarClassifierCascade(haartraining_ouput_dir,size); if(!cascade ){ fprintf(stderr,"Inputcascade could not be found/opened\n"); return-1; } sprintf(comment, "Automaticallyconverted from %s, window size = %dx%d",ouput_file, size.width, size.height ); cvSave(ouput_file, cascade, 0, comment, cvAttrList(0,0) ); return0; } |
4.开始测试
| inthaarDection() { Matimage; CascadeClassifiercascade, nestedCascade;//创建级联分类器对象 doublescale = 1.3; // image = imread("obama_gray.bmp",1); image= imread("D://haarcascade_frontalface_alt.jpg",1); namedWindow("result",1 );//opencv2.0以后用namedWindow函数会自动销毁窗口
if(!cascade.load( cascadeName ) )//从指定的文件目录中加载级联分类器 { cerr<< "ERROR:Could not load classifier cascade"<< endl; return0; }
if(!image.empty() )//读取图片数据不能为空 { detectAndDraw(image, cascade, scale );
IplImageqImg; qImg= IplImage(image); cvSaveImage("D://aaa.jpg",&qImg);
waitKey(0); }
return0; }
voiddetectAndDraw( Mat&img, CascadeClassifier&cascade, doublescale) { inti = 0; doublet = 0; vector<Rect>faces; conststaticScalarcolors[] = { CV_RGB(0,0,255), CV_RGB(0,128,255), CV_RGB(0,255,255), CV_RGB(0,255,0), CV_RGB(255,128,0), CV_RGB(255,255,0), CV_RGB(255,0,0), CV_RGB(255,0,255)};//用不同的颜色表示不同的人脸
Matgray, smallImg( cvRound (img.rows/scale),cvRound(img.cols/scale),CV_8UC1);//将图片缩小,加快检测速度
cvtColor(img,gray, CV_BGR2GRAY);//因为用的是类haar特征,所以都是基于灰度图像的,这里要转换成灰度图像 resize(gray, smallImg, smallImg.size(), 0, 0, INTER_LINEAR);//将尺寸缩小到1/scale,用线性插值 equalizeHist(smallImg, smallImg );//直方图均衡
t= (double)cvGetTickCount();//用来计算算法执行时间
//检测人脸 //detectMultiScale函数中smallImg表示的是要检测的输入图像为smallImg,faces表示检测到的人脸目标序列,1.1表示 //每次图像尺寸减小的比例为1.1,2表示每一个候选矩形需要记录2个邻居,CV_HAAR_SCALE_IMAGE表示使用haar特征,Size(30,30) //为目标的最小最大尺寸 cascade.detectMultiScale(smallImg, faces, 1.1,2, 0 //|CV_HAAR_FIND_BIGGEST_OBJECT //|CV_HAAR_DO_ROUGH_SEARCH |CV_HAAR_SCALE_IMAGE , Size(30,30) );
t= (double)cvGetTickCount()- t;//相减为算法执行的时间 printf("detectiontime = %g ms\n",t/((double)cvGetTickFrequency()*1000.)); /* for(vector<Rect>::const_iterator r = faces.begin(); r !=faces.end(); r++, i++ ) { MatsmallImgROI; vector<Rect>nestedObjects; Pointcenter; Scalarcolor = colors[i%8]; intradius; center.x= cvRound((r->x + r->width*0.5)*scale);//还原成原来的大小 center.y= cvRound((r->y + r->height*0.5)*scale); radius= cvRound((r->width + r->height)*0.25*scale); circle(img, center, radius, color, 3, 8, 0 ); smallImgROI= smallImg(*r); }*/ cv::imshow("result",img); } |
效果如下:人脸都检测到了,但还是有误检情况,需要继续优化



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









