







 本文介绍了如何使用C++实现决策树ID3算法,通过实例展示了算法的运用,构建了一个根据气候条件判断是否去游泳的决策树。代码包含详细注释,并探讨了数据结构的选择和遍历策略。
本文介绍了如何使用C++实现决策树ID3算法,通过实例展示了算法的运用,构建了一个根据气候条件判断是否去游泳的决策树。代码包含详细注释,并探讨了数据结构的选择和遍历策略。
数据挖掘课上面老师介绍了下决策树ID3算法,我抽空余时间把这个算法用C++实现了一遍。
决策树算法是非常常用的分类算法,是逼近离散目标函数的方法,学习得到的函数以决策树的形式表示。其基本思路是不断选取产生信息增益最大的属性来划分样例集和,构造决策树。信息增益定义为结点与其子结点的信息熵之差。信息熵是香农提出的,用于描述信息不纯度(不稳定性),其计算公式是
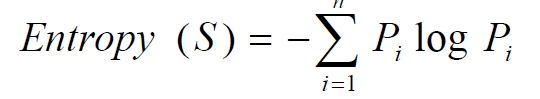
Pi为子集合中不同性(而二元分类即正样例和负样例)的样例的比例。这样信息收益可以定义为样本按照某属性划分时造成熵减少的期望,可以区分训练样本中正负样本的能力,其计算公司是

我实现该算法针对的样例集合如下
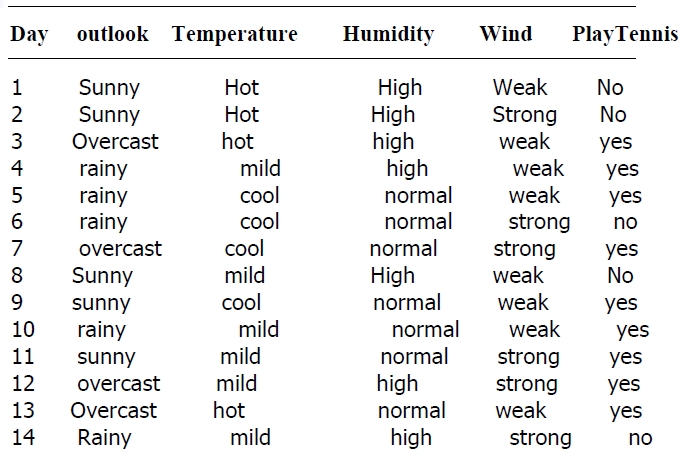
该表记录了在不同气候条件下是否去打球的情况,要求根据该表用程序输出决策树
C++代码如下,程序中有详细注释
#include <iostream>
#include <string>
#include <vector>
#include <map>
#include <algorithm>
#include <cmath>
using namespace std;
#define MAXLEN 6//输入每行的数据个数
//多叉树的实现
//1 广义表
//2 父指针表示法,适于经常找父结点的应用
//3 子女链表示法,适于经常找子结点的应用
//4 左长子,右兄弟表示法,实现比较麻烦
//5 每个结点的所有孩子用vector保存
//教训:数据结构的设计很重要,本算法采用5比较合适,同时
//注意维护剩余样例和剩余属性信息,建树时横向遍历考循环属性的值,
//纵向遍历靠递归调用
vector <vector <string> > state;//实例集
vector <string> item(MAXLEN);//对应一行实例集
vector <string> attribute_row;//保存首行即属性行数据
string end("end");//输入结束
string yes("yes");
string no("no");
string blank("");
map<string,vector < string > > map_attribute_values;//存储属性对应的所有的值
int tree_size = 0;
struct Node{//决策树节点
string attribute;//属性值
string arrived_value;//到达的属性值
vector<Node *> childs;//所有的孩子
Node(){
attribute = blank;
arrived_value = blank;
}
};
Node * root;
//根据数据实例计算属性与值组成的map
void ComputeMapFrom2DVector(){
unsigned int i,j,k;
bool exited = false;
vector<string> values;
for(i = 1; i < MAXLEN-1; i++){//按照列遍历
for (j = 1; j < state.size(); j++){
for (k = 0; k < values.size(); k++){
if(!values[k].compare(state[j][i])) exited = true;
}
if(!exited){
values.p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









