







这段时间,打算好好写写博客,希望将自己前段时间的开发经历梳理一遍,看看能不能沉淀一些东西,也希望能够和有共同兴趣的同学一起探讨学习。
有兴趣的同学可以看看前两篇文章:
“创业梦”的破碎
布板的前世今生
我开发的就是一个类似于Zaker和鲜果等新闻订阅服务的APP;接下来的一个系列,我都将是围绕这一个主题,按照一定的逻辑,介绍如何一步步地开发出一个新闻订阅APP。
首先,将会是第一部分:爬虫篇。
爬虫是我工作量最少,但是代码写的最有意思的一部分。
好了,言归正传,学习爬虫,不得不先提到通用搜索引擎的爬虫是如何工作的,先来看一张图:
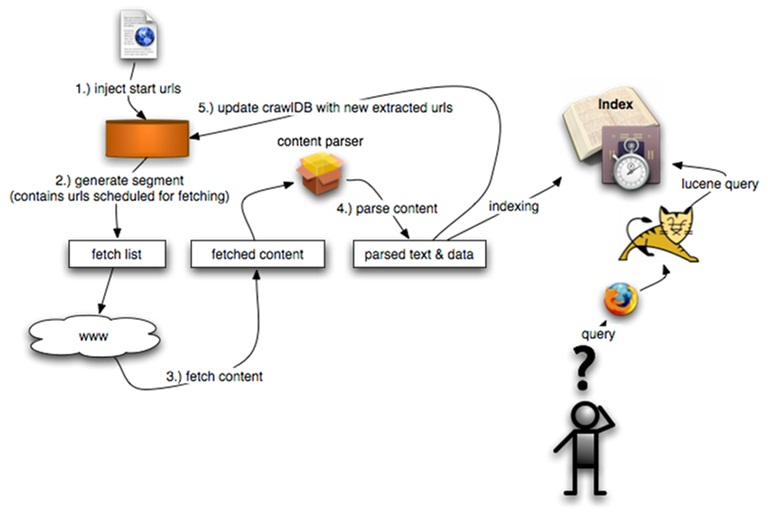
注:nutch原理图
这大概是网上流传最广的一张关于爬虫的介绍图,左半部分即是爬虫的工作流程了。
它的工作步骤简单的概括大致分为以下几步:
- 指定需要搜索的页面集的url正则表达式;
- 注入urls种子,(通常是root url),并更新到待抓取集合中;
- 抓取当前待抓取集合中的urls所对应的页面;
- 解析抓取到的页面,包括: 提取超链接,去重,合并到待抓取集合中;
- 重复3,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1578
1578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









