









前言
一、主从复制过程
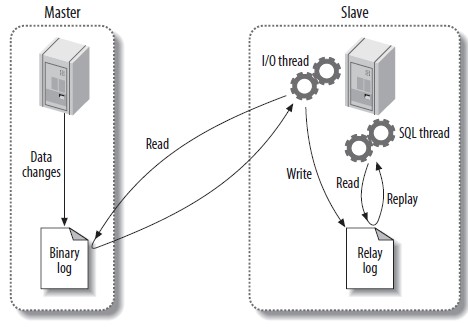
MySQL的主从复制能力是通过三个线程来实现的,两个在Slave端的I/O和SQL两个线程,还有一个在Master端I/O线程:
- Binlog dump thread:Master端创建该线程来响应Slave端I/O线程的请求,向Slave端发送二进制内容。Binlog dump线程读取主服务器二进制内容前会对其加锁,读取结束后无论内容是否被发送到Slave端,锁都会被即刻释放。在一主多从架构中,Master端会为每个连接的I/O线程创建一个Binlog dump线程。
- Slave I/O thread:当Slave端执行START SLAVE命令时,Slave端随即创建一个I/O线程,并连接Master端请求更新。Slave端的I/O线程从Master端的Binlog dump线程读取更新并拷贝到本地Relay log(中继日志)中。
- Slave SQL thread:Slave创建的第二个线程是SQL线程,该线程从Relay log中读取和执行语句。
复制过程中涉及的三个核心线程介绍完了,我们来总结下完整的复制过程:
1)、Slave创建I/O线程并连接Master,请求日志文件的指定位置(或者从最开始的日志)之后的日志内容。
2)、Master服务器接收到来自Slave服务器的I/O线程请求后,会随之创建Binlog Dump线程来响应这个线程。然后,Binlog Dump线程根据请求信息读取指定日志位置之后的日志信息,返回给Slave端的I/O线程。
3)、Slave的I/O线程接收到信息后,将日志内容依次写入Slave端的Relay Log(中继日志)文件中,并将读取到的Master端的二进制文件名和位置记录到master-info文件中。
4)、Slave的SQL线程检测到Relay Log中新内容后,会马上解析并执行这些语句。
我们可以看出Slave服务器上的I/O和SQL两个线程使得读取和执行语句被分成两个独立的任务。因此,即使某条语句在Slave服务器上执行缓慢,但语句读取任务并不会慢下来。
MySQL semi-sync replication(半同步复制)在之前的基础上做了加强完善,整个流程变成了下面这样:
- 首先,master和至少一个slave都要启用semi-sync replication模式;
- 某个slave连接到master时,会主动告知当前自己是否处于semi-sync模式;
- 在master上提交事务后,写入binlog后,还需要通知至少一个slave收到该事务,等待写入relay log并成功刷新到磁盘后,向master发送“slave节点已完成该事务”确认通知;
- master收到上述通知后,才可以真正完成该事务提交,返回事务成功标记;
- 在上述步骤中,当slave向master发送通知时间超过rpl_semi_sync_master_timeout设定值时,主从关系会从semi-sync模式自动调整成为传统的异步复制模式。
半同步复制看起来似乎可以异步复制的痛点,但如果网络质量不高,是不是出现抖动,触发上述第5条的情况,会从半同步复制降级为异步复制;此外,采用半同步复制,会导致master上的tps性能下降非常严重,最严重的情况下可能会损失50%以上。
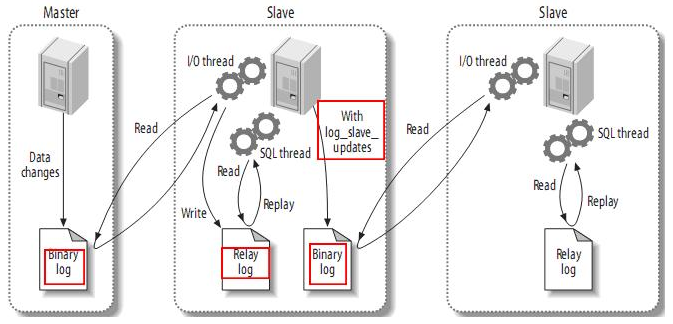
二、数据一致性
我们看到主从复制的过程简单清晰,但是会存在如下情况影响主从数据的一致性:
- 数据丢失
- 数据重复
1、MySQL主从复制又是怎么解决数据丢失和数据重复,进而保障主从数据的一致性哪?
- 从库的重传检查点
我们知道从库的 I/O Thread 是通过网络读取主库的 binlog 的,如果出现网络故障,有可能产生数据丢失。为避免网络故障导致的数据丢失,网络恢复后从库重新连接上来需要知道从主库 binlog 的哪个位置重新传输数据。从库需要记住中断发生时 binlog 的位置,并从该断点处重新读取,这个断点我们称为从库的重传检查点。一个可靠的重传检查点必须是在从库读到数据并写入到本地 Relay log 持久化之后才可建立,否则都有丢失数据的可能。
- 防重策略
我们知道分布式特征具有幂等性,也就是重复复制同一条数据最终不会产生重复的数据。
因此需要保证主从复制过程的幂等性,一般符合范式特征的数据库表设计通过主键来防重,而无主键表数据可以通过所有字段联合唯一索引来防重。有了防重策略就可以任意回溯复制过程,而不必考虑从库产生重复数据。
我们知道binlog 的事件日志反应了主库并发事务的操作序列,最终这种序列也要原样反应到从库上。
MySQL主从复制架构为了保证主从数据一致性,复制过程不仅要保证不丢失、不重复,还需要保证操作顺序一致。采用了单线程模型的串行化操作。因为在数据库层面是无法知道不同数据之间的因果和依赖关系,因此无法并行入库。
2、MySQL主从复制架构做到了无丢失、无重复和顺序一致性,但也存在一些不足:
- 可监控性、可管理性相对较弱。
- 对于异构数据无能为力。
- 通用的单线程模型可能成为性能瓶颈,导致复制延时过高。
- 一对多场景下对主库形成过大复制压力,影响主库可用性。
3、一些特殊场景下的分布式数据库架构中,使用这种复制架构则不一定合适,场景如:
- 大型库,数据量大,写入量大,还需要跨地域、跨机房的复制,而且对复制延时长短比较敏感,比如交易类数据库、订单类数据库。
三、数据复制延迟
数据复制延迟主要原因:主库多线程更新,从库单线程更新。
Master产生二进制日志由于buffer和顺序IO的关系,效率非常高。Slave的I/O线程到Master端取日志的过程效率也比较高,但Slave的SQL线程在应用Relay Log中的操作时产生IO操作是随机的而不是顺序的,所以时间成本会高非常多,不仅如此,甚至还可能同Slave上的其他查询产生锁争用。由于Slave的SQL线程是单线程的,Relay Log中的语句只能一个个的被执行,所以所有的语句只能等待它之前的语句被执行完才会执行,这就导致了延时。
我们可以通过vmstat之类的命令来进行验证。观察”r”和”b”两列数值,如果r列值很大,说明服务器CPU达到瓶颈,如果b列值很大,说明服务器IO达到瓶颈。
1)、如果复制过程受磁盘IO限制,可以尝试以下解决方法:
-
- 优化Mysql参数(增大innodb_buffer_pool_size) 和 增加内存,让更多操作在Mysql内存中完成,减少磁盘操作。
- 使用SSD磁盘,提升IO性能。
- 尝试对二进制日志内容进行压缩传输
- 业务代码优化,将实时性要求高的某些操作,使用主库做读操作。
2)、如果问题发生在SQL线程
多线程同步:使用淘宝的Transfer解决方案,是一个基于MySQL+patch后得到的主从同步工具。该工具的原理是以多线程的方式来读取relaylog更新SlAVE的方式。。
3)、如果复制过程受CPU限制,使用高性能CPU主机或者参考Peter Zaitsev写的Fighting MySQL Replication Lag。
4)、采用MariaDB发行版,它实现了相对真正意义上的并行复制,其效果远比ORACLE MySQL好的很多。在我的场景中,采用MariaDB作为slave的实例,几乎总是能及时跟上master。如果不想用这个版本的话,那就老实等待官方5.7大版本发布吧;
关于MariaDB的Parallel Replication具体请参考:Replication and Binary Log Server System Variables#slave_parallel_threads – MariaDB Knowledge Base
5)、每个表都要显式指定主键,如果没有指定主键的话,会导致在row模式下,每次修改都要全表扫描,尤其是大表就非常可怕了,延迟会更严重,甚至导致整个slave库都被挂起,可参考案例:mysql主键的缺少导致备库hang。
6)、应用程序端多做些事,让MySQL端少做事,尤其是和IO相关的活动,例如:前端通过内存CACHE或者本地写队列等,合并多次读写为一次,甚至消除一些写请求。
7)、进行合适的分库、分表策略,减小单库单表复制压力,避免由于单库单表的的压力导致整个实例的复制延迟。
四、延迟检测
1、Seconds_Behind_Master,并不能表示主从数据一致
表示slave上SQL thread与IO thread之间的延迟,我们都知道在MySQL的复制环境中,slave先从master上将binlog拉取到本地(通过IO thread),然后通过SQL thread将binlog重放,而Seconds_Behind_Master表示本地relaylog中未被执行完的那部分的差值。
手册上的定义:In essence, this field measures the time difference in seconds between the slave SQL thread and the slave I/O thread.
所以如果slave拉取到本地的relaylog都执行完,此时通过show slave status看到的会是0。
- 那么Seconds_Behind_Master的值为0是否表示主从已经处于一致了呢?答案几乎是否定的!
因为绝大部分的情况下复制都是异步的(MySQL5.5级以后版本中支持了半同步复制),异步就意味着master上的binlog不是实时的发送到slave上,所以即使Seconds_Behind_Master的值为0依然不能肯定主从处于一致。所以我们只能在一个比较好的网络环境中以这个参数来估计主从延迟。
- Seconds_Behind_Master的值到底是怎么计算出来的呢?
实际上在binlog中每个binlog events都会附上执行时的timestamp,所以在在确定Seconds_Behind_Master的值时MySQL是通过比较当前系统的时间戳与当前SQL thread正在执行的binlog event的上的时间戳做比较,这个差值就是Seconds_Behind_Master的值。也许你会有疑问那要是两台服务器之间的时钟不一致怎么办?确实会存在这种情况,那么此时这个值的可靠性就不大了,手册上对此也进行了说明:
This time difference computation works even if the master and slave do not have identical clock times, provided that the difference,
computed when the slave I/O thread starts, remains constant from then on. Any changes—including NTP updates—can lead to clock
skews that can make calculation of Seconds_Behind_Master less reliable
Seconds_Behind_Master的值除了是非负数之外还可能是NULL,它是由如下几种情况导致的:SQL thread没运行/IO thread没运行/slave没有连接到master。
异步复制,master上的操作记录binlog的同时不关心binlog是否已经被slave接收。
半同步复制,master上的操作记录binlog的同时会关心binlog是否被slave接受。
2、Master_Log_File/Read_Master_Log_Pos、Relay_Log_File/Relay_Log_Pos、Relay_Master_Log_File/Exec_Master_Log_Pos
1)、The position, ON THE MASTER, from which the I/O thread is reading:Master_Log_File/Read_Master_Log_Pos.
相对于主库,从库读取主库的二进制日志的位置,是IO线程
2)、The position, IN THE RELAY LOGS, at which the SQL thread is executing:Relay_Log_File/Relay_Log_Pos
相对于从库,是从库的sql线程执行到的位置
3)、The position, ON THE MASTER, at which the SQL thread is executing:Relay_Master_Log_File/Exec_Master_Log_Pos
相对于主库,是从库的sql线程执行到的位置
2) 和 3) are the same thing, but one is on the slave and the other is on the master.
mysql > show slave status \G
Master_Log_File: mysql-bin-m.000329
Read_Master_Log_Pos: 863952156 ----上面二行代表IO线程,相对于主库的二进制文件
Relay_Log_File: mysql-relay.003990
Relay_Log_Pos: 25077069 ----上面二行代表了sql线程,相对于从库的中继日志文件
Relay_Master_Log_File: mysql-bin-m.000329
.....
Exec_Master_Log_Pos: 863936961---上面二行代表了sql线程,相对主库
Relay_Log_Space: 25092264---当前relay-log文件的大小
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
从上面可以看到,read_master_log_pos 始终会大于exec_master_log_pos的值(也有可能相等)。因为一个值是代表io线程,一个值代表sql线程;sql线程肯定在io线程之后.(当然,io线程和sql线程要读写同一个文件,否则比较就失去意义了) .
3、percona-toolkit工具对mysql主从数据库的同步状态进行检查和重新同步
pt-heartbeat: 监控MySQL从服务器的延时时间。
pt-slave-restart: 管理MySQL从服务器重启。
pt-table-checksum: 检查主从同步数据的一致性,比如遇到复制错误,我们执行了skip error操作之后,检查一下数据还是很有必要的。不过这个工具需要提前设置一下,安装相应的checksum表。
五、主从数据不同步解决
http://ylw6006.blog.51cto.com/470441/1616570














 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









