









二叉树
Keyword
二叉树的概念,特性及二叉树的前序(pre-order traversal),中序(in-order traversal),后序(post-order traversal)遍历以及广度优先遍历(Breadth First Search),深度优先遍历(Depth First Search),二叉树的Morris遍历。
二叉树的基本概念
二叉树就是每个节点最多有两个子树的树结构,其两个子树通常被称为左子树(left subtree)和右子树(right subtree)。
二叉树的每个节点最多可能存在两棵子树(既不可能存在度大于2的节点),两个子树有左右之分且次序不能颠倒。
二叉树的第i层至多有2^(i-1)个结点,深度为k的二叉树至多有2^k-1个结点。
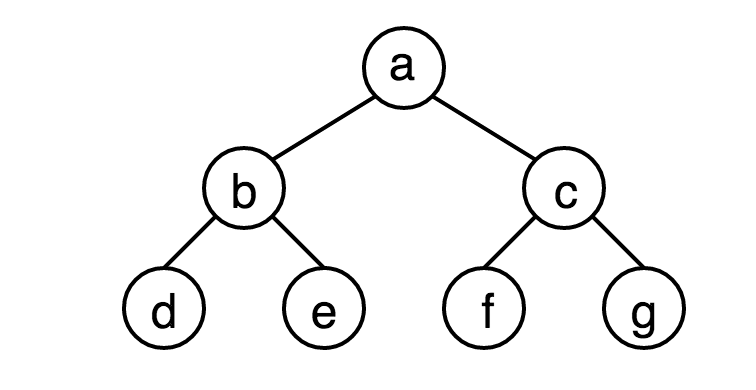
满二叉树(Full Binary Tree)指的是深度为k且有2^k-1个结点的二叉树。既除去叶子结点外其余结点均具有左右孩子。下图为满二叉树。
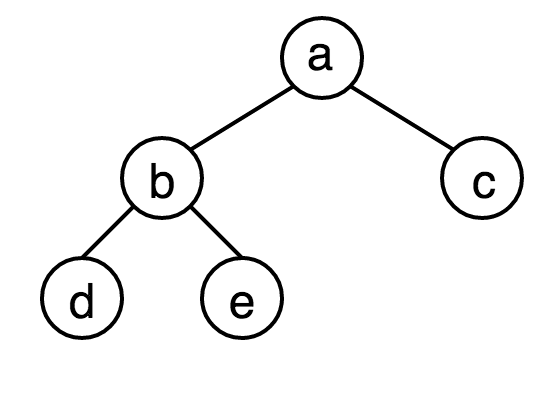
完全二叉树(Complete Binary Tree)指的是除最深一层层外其余层既构成一个满二叉树的树,最大层的叶子结点全部靠左分布。具有n个结点的完全二叉树的结点与满二叉树中前n个结点一一对应。下图为完全二叉树。
对于完全二叉树,若以一个数组array来表示其按层从高到低,从左到右遍历的结果,设一个结点为i,则其父结点为i/2,其左子结点为2*i,其右子结点为2*i+1。
二叉树的存储结构
二叉树的链式存储结构定义如下:
/**
* Definition of Binary Tree
*/
public class BinaryTreeNode{
int data;
BinaryTreeNode leftchild;
BinaryTreeNode rightchild;
BinaryTreeNode (int x){
data = x;
}
/**
* construct binary tree with an array
* recursive method
* @param: an array contains the value for the binary tree
* @param: an index indicating which value should be the root
* if no index provided, array[0] should be the root
*/
public static BinaryTreeNode makeBinaryTree (int[] array){
return makeBinaryTree(array, 0);
}
private static BinaryTreeNode makeBinaryTree (int[] array, int index){
if (index >= array.length) {
return null;
}
BinaryTreeNode root = new BinaryTreeNode(array[index]);
root.left = makeBinaryTree(array, 2 * index);
root.right = makeBinaryTree(array, 2 * index + 1);
return root;
}
}
二叉树的遍历
遍历即按给某种顺序访问所有的二叉树中的结点1次。
按访问结点的顺序可以分为:
- 前序遍历:根结点–>左子树–>右子树
- 中序遍历:左子树–>根结点–>右子树
- 后续遍历:左子树–>右子树–>根节点
例如求以下这棵树的几种遍历:
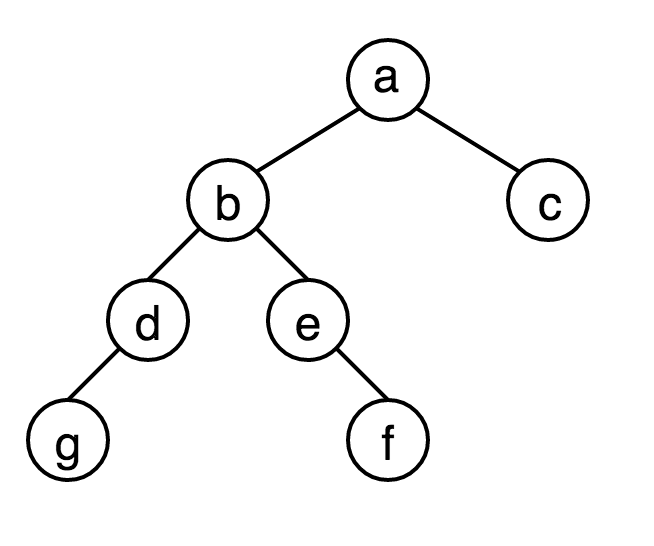
前序遍历:abdgefc
中序遍历:gdbefac
后序遍历:gdfebca
广度优先遍历:abcdegf
深度优先遍历:abdgefc
遍历的实现
递归实现
前序遍历
/**
* Pre-order traversal of a binary tree recursively
*/
public void preOrderTrav(BinaryTreeNode root) {
if (root != null) {
System.out.println(root.data);
preOrderTrav(root.leftchild);
preOrderTrav(root.rightchild);
}
}
中序遍历
/**
* In-order traversal of a binary tree recursively
*/
public void inOrderTrav(BinaryTreeNode root) {
if (root != null) {
inorderTrav(root.leftchild);
System.out.println(root.data);
inorderTrav(root.rightchild);
}
}
后序遍历
/*
* Post-order traversal of a binary tree recursively
*/
public void postOrderTrav(BinaryTreeNode root) {
if (root != null) {
postOrderTrav(root.leftchild);
postOrderTrav(root.rightchild);
System.out.println(root.data);
}
}
非递归实现
当采用非递归实现的时候,我们考虑到遍历过根结点的子结点之后还要再回来访问根结点,所以我们需要将访问过的根结点存起来。考虑到其后进先出的特性,我们需要用栈(stack)来存储
前序遍历
import java.util.Stack;
public void preorderTrav(BinaryTreeNode root){
Stack<BinaryTreeNode> stack = new Stack<BinaryTreeNode>();
if (root == null){
System.out.println("Empty Tree!");
}
else{
while (root != null || !stack.empty()) {
while (root != null){
System.out.println(root.data);
stack.push(root);
root = root.leftchild;
}
root = stack.pop();
root = root.rightchild;
}
}
}
中序遍历
import java.util.Stack;
public void inorderTrav(BinaryTreeNode root){
Stack<BinaryTreeNode> stack = new Stack<BinaryTreeNode>();
if (root == null){
System.out.println("Empty Tree!");
}
else {
while (root != null || !stack.empty()){
while (root != null){
stack.push();
root = root.leftchild;
}
root = stack.pop();
System.out.println(root.data);
root = root.rightchild;
}
}
}
后序遍历
在后序遍历中,给定一个根结点,我们需要先访问根结点的左子树,然后访问根结点的右子树,最后访问根结点。因此在迭代过程中我们需要保存一个prev 变量来存储前一步中访问过的结点,从而判断这一步应该继续向下访问还是向上访问根结点。遍历的过程有如下三种情况:
从栈顶peek一个元素为curr:
- 如果
prev == null或者prev.left == curr或者prev.right == curr,则有如下情况。根据后序遍历的顺序,所有这几种情况下,如果当前结点的左子树不为空,则我们将当前节点的左孩子放入栈中并继续这个循环。如果当前结点的左孩子为空且右孩子不为空,则将当前结点的右孩子放入栈中并继续循环。如果当前结点的左右孩子均为空,则当前节点为一个叶子结点,我们应当将当前结点从栈中删除并记录其值。- 如果
prev == null,则我们之前并未访问任何结点,当前curr所在结点为二叉树的根结点。 - 如果
prev.left == curr,则我们之前访问了curr的父节点。 - 如果
prev.right == curr,则我们之前访问了curr的父节点。
- 如果
- 如果
prev == curr.left,则代表我们前一步访问了当前结点的左孩子。如果当前结点的右孩子不为空,则我们将当前结点的右孩子放入栈中,并继续循环。反之,如果当前结点的右孩子为空,我们应当记录当前结点的值并将其从栈中删除。 - 如果
prev == curr.right,则代表我们前一步中访问了当前结点的右孩子。根据后序遍历的顺序,我们应当记录当前结点的值并从栈中将其删除。
import java.util.*;
public class IterativePostOrder {
public List<Integer> postOrderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
postOrderTraversal(root, list);
return list;
}
private void postOrderTraversal(TreeNode root, List<Integer> list) {
Deque<TreeNode> deque = new ArrayDeque<>();
if (root == null) {
return;
}
deque.push(root);
TreeNode prev = null;
while (!deque.isEmpty()) {
TreeNode curr = deque.peek();
if (prev == null || prev.left == curr || prev.right == curr) {
if (curr.left != null) {
deque.push(curr.left);
} else if (curr.right != null) {
deque.push(curr.right);
} else {
deque.pop();
list.add(curr.val);
}
} else if (prev == curr.left) {
// previously visited current's left child
if (curr.right != null) {
deque.push(curr.right);
} else {
deque.pop();
list.add(curr.val);
}
} else if (prev == curr.right) {
// previously visited current's right child
// hence we should visit the current node based on post order
deque.pop();
list.add(curr.val);
}
prev = curr;
}
}
}
广度优先遍历(BFS)
广度优先遍历也就是按层次遍历二叉树,依次遍历其根结点,左孩子和右孩子。在这种遍历方式下,左右子树按顺序输出,所以需要采用先进先出的队列来存储。
其算法如下:
- 访问初始结点root并标记其为已访问
- 将root存入队列
- 当队列非空时,继续执行算法,否则算法结束
- 取得对列头部的结点u,出队列
- 查找结点u的第一个子结点w
- 如果结点u的子结点不存在,则转到步骤3。否则循环执行以下步骤:
- 若结点w尚未被访问,则访问结点w并标记为已访问
- 将结点w存入队列
- 查找结点u的下一个子结点,转到步骤6
以下是广度优先遍历的代码:
import java.util.Queue;
import java.util.LinkedList;
public void BFS(BinaryTreeNode root){
if (root == null){
System.out.println("Empty Tree!");
return;
}
Queue<BinaryTreeNode> queue = new LinkedList<BinaryTreeNode>();
queue.add(root);
while (!queue.isEmpty()){
BinaryTreeNode node = queue.remove();
System.out.println(node.data);
if (node.leftchild != null){
queue.add(node.leftchild);
}
if (node.rightchild != null){
queue.add(node.rightchild);
}
}
}
深度优先遍历(DFS)
与广度优先遍历中的按层次遍历不同,深度优先遍历是沿着每一个树的分支走到底然后再返回遍历其余分支。其策略就是先访问一个结点,然后以这个结点为根访问其子结点,既优先纵向挖掘深入。由于二叉树不存在环,所以我们不需要标记每一个结点是否已被访问过。又由于其遍历特点,我们需要后进先出的访问存储的结点。所以我们使用栈来存储。
其算法如下(非递归):
- 访问初始结点root,并标记其为已访问
- 查找结点root的子结点并将这些子结点存入栈中
- 判断栈是否为空,如果为空结束循环,如果不为空则继续执行算法
- 取出栈顶结点,标记为已访问并查找其子结点
- 若子结点不存在则转到步骤3,否则循环执行以下步骤:
- 若结点尚未被访问,则将其存入栈中
- 查找下一个子结点并回到步骤6
对应的代码如下:
import java.util.Stack;
public void DFS(BinaryTreeNode root){
if (root == null){
System.out.println("Empty Tree!");
return;
}
Stack<BinaryTreeNode> stack = new Stack<BinaryTreeNode>();
stack.push(root);
while (!stack.isEmpty()){
BinaryTreeNode node = stack.pop();
System.out.println(node.data);
if (node.leftchild != null){
stack.push(node.leftchild);
}
if (node.rightchild != null){
stack.push(node.rightchild);
}
}
}
深度优先遍历也可以用递归解决,运用递归的深度优先遍历算法如下:
- 访问初始结点root并标记为已访问
- 查找该结点的子结点
- 若子结点存在,则执行步骤4,否则算法结束
- 若子结点未被访问,则以子结点为初始结点进行递归深度优先遍历
- 查找下一个子结点,转到步骤3
public void recursiveDFS(BinaryTreeNode root){
if (root == null){
System.out.println("Empty Tree!");
return;
}
System.out.println(root.data);
if (root.leftchild != null){
recursiveDFS(root.leftchild);
}
if (root.rightchild != null){
recursiveDFS(root.rightchild);
}
}
二叉树的Morris遍历
以上的递归算法或者栈迭代算法遍历二叉树所需的时间和空间复杂度均为O(n)。但还存在一种更为巧妙的Morris遍历算法(Morris Traversal),其时间复杂度为O(n),但空间复杂度为O(1)。
Morris算法只需常数空间且不会改变二叉树的形状(中间过程会改变)。
要使用O(1)空间进行遍历,最大的难度在于怎样返回父节点(假设结点中没有指向父节点的指针)。为了解决这个问题,Morris算法用到了线索二叉树的概念(threaded binary tree)。在Morris算法中不需要额外为每个二叉树分配指针指向其前驱(predecessor)和后继结点(successor),只需要用结点中的左右空指针指向某种顺序遍历下的前驱或者后继结点即可。
中序遍历的Morris算法
- 如果当前结点的左孩子为空,则输出当前结点并将其右孩子作为当前结点。
- 如果当前结点的左孩子不为空,则在当前结点的左子树中找到当前结点在中序遍历下的前驱结点。
- 如果前驱结点的右孩子为空,则将前驱结点的右孩子设为当前节点,当前结点更新为当前结点的左孩子。
- 如果前驱结点的右孩子为当前结点,则将其右孩子重新设为空(恢复树的形状)。输出当前节点,当前结点更新为当前结点的右孩子。
- 重复以上1,2步骤直到当前结点为空。
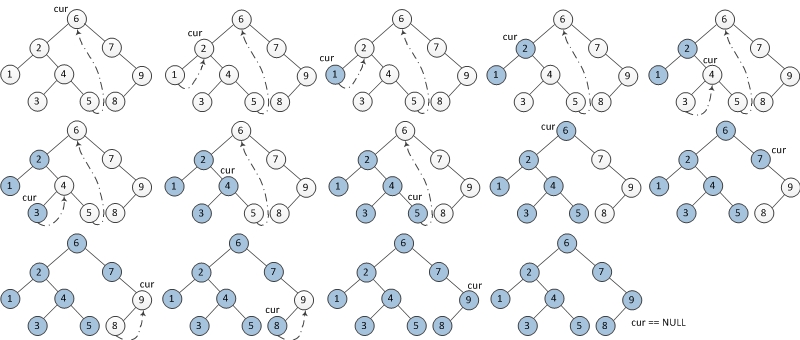
下图表示了每一步迭代的结果,从左到右,从上到下。其中cur代表当前结点,蓝色结点代表已输出的结点。
中序Morris遍历的代码如下:
public void InorderMorrisTraversal(BinaryTreeNode root){
BinaryTreeNode prev = null;
BinaryTreeNode cur = root;
if (cur == null){
System.out.println("Empty Tree!");
return;
}
while (cur != null){
if (cur.left == null){ //1
System.out.println(cur.data);
cur = cur.right;
}
else {
//find predecessor
prev = cur.left;
while (prev.right != null && prev.right != cur){
prev = prev.right;
}
if (prev.right == null){ //2a
prev.right = cur;
cur = cur.left;
}
else { //2b
System.out.println(cur.data);
prev.right = null;
cur = cur.right;
}
}
}
}
复杂度分析:
空间复杂度:只使用了cur和prev两个变量。所以空间复杂度是O(1)
时间复杂度:解决时间复杂度的关键是寻找前驱结点的代码
while (prev.right != null && prev.right != cur){
prev = prev.right;
}
直觉上看,这段代码和二叉树的深度有关。二叉树深为logn,所以需要O(nlogn)时间。实际上,考虑到n个结点的二叉树中共有n-1条边,而每条边最多只走两次(一次遍历到达cur结点进过该边,一次寻找前驱结点prev经过该边),所以实际运行时间为O(n)。
前序遍历的Morris算法
前序遍历与中序遍历类似,只不过输出结点值得位置不同。算法如下:
- 如果当前结点的左孩子为空,则输出当前结点值并将其右孩子作为当前结点
- 如果当前结点的左孩子不为空,则在当前结点的左子树中找到当前节点在中序遍历下的前驱结点
- 如果前驱结点的右孩子为空,则将前驱结点的右孩子设置为当前结点,并输出当前结点(在此处输出,是与中序遍历的唯一不同)。当前结点设置为当前结点的右孩子。
- 如果前驱结点的右孩子为当前结点,则将其右孩子设置为空。当前结点更新为当前结点的右孩子
- 重复1,2两个步骤知道当前结点为空
图示:
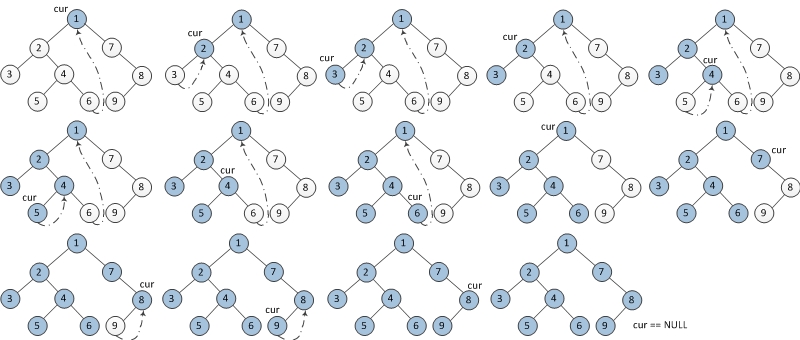
二叉树的前序Morris遍历Java代码如下:
public void preorderMorrisTraversal(BinaryTreeNode root){
BinaryTreeNode prev;
BinaryTreeNode cur = root;
if (root == null){
System.out.println("Empty Tree!");
return;
}
while (cur != null){
if (cur.left == null){ //1
System.out.println(cur.data);
cur = cur.right;
}
else {
prev = cur.left;
while (prev.right != null && prev.right != cur){ //find the predecessor of the current node
prev = prev.right;
}
if (prev.right == null){ //2a
prev.right = cur;
System.out.println(cur.data); //the only difference with inorder traversal
cur = cur.left;
}
else { //2b
prev.right = null;
cur = cur.right;
}
}
}
}
复杂度分析:
与中序遍历类似,空间复杂度为O(1),时间复杂度为O(n)。
















 5240
5240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











