







ArrayList,Vector,LinkedList的区别
| ArrayList | Vector | LinkedList |
实现原理 | 数组 | 数组 | 双向链表 |
线程安全 | 否 | 是 | 否 |
优点 | 1.数组实现优于遍历 | 1.数组实现优于遍历 | 1.节点的增删无需对象的重建 |
缺点 | 1.非线程安全 | 1.数组中未使用的元素造成空间的浪费 | 1.遍历效率较低 |
扩容 | 0.5倍增量 | 1倍增量 | 按需增删 |
使用场景 | 1.无线程的要求。 | 1.有线程安全的要求 | 增删场景较多的时候 |
|
|
|
|
- int与Integer的区别
| int | Integer |
类型 | 基本类型 | 复合类型 |
默认值 | 0 | null |
存储 | 栈(局部变量) | 堆上(只能通过new创建) |
方法 | 基本类型无方法 | 有 |
速度 | 快(栈上 的操作相对快) | 慢 |
泛型支持 | 否(java中的泛型不支持,C++中的模板支持) | 支持 |
容器类支持 | 否(直接使用通常会进行装箱操作) | 支持 |
存在意义 | 1.历史原因(顺延C/C++中存在) | 基本类型int的包装类 |
2.RuntimeException与普通异常,error的区别。
Checked Exception:在编译时就能够被Java编译器所检测到的。
UncheckedException:则是编译时,java编译器不能检查到。
| RuntimeException | 普通Exception | Error |
受控异常 | 否 | 是 | 否 |
产生原因 | 开发者的编程错误 | 由于外界环境所限, | Java运行时的系统错误,资源耗尽,是一种严重的, |
例子 | NullPointerException | ClassNotFoundException | VirtualMachineError |
4.final,finalize,finally的区别
final:关键字,表不变
修饰:
- 方法:方法不可Override
- 类:不可被继承
- 基本类型量:常量,值不可变
- 符合类型量:引用不可变,即引用的值不可变
[java] view plaincopy
- final Object o1 = new Object();
- o1 = new Object();
finally:关键字,Java异常处理机制的一部分,在异常发生时,用来提供一个必要的清理的机会。
finalize:Object类的方法(参考自百度百科)
意义:Java技术允许使用finalize()方法在垃圾回收器将对象回收之前,做一些必要的清理操作。
调用前提:这个对象确定没有被引用到。
工作原理:
- 垃圾收集器准备好释放对象占用的空间。
- 首先调用其finalize方法。
- 下一次垃圾收集过程中,真正回收内存。
不确定性:
- finalize的执行时间是不缺定的。
- 一个对象引用另一个对象,并不能保证finalize的方法按照特定的执行顺序。
5.Override,Overload
| Override | Overload |
签名+返回值 | 相同 | 方法名相同,签名不同 |
关系 | 父子类继承关系 | 通常是同一类层次中 |
识别 | 运行时多态 | 编译时多态 |
修饰符限制 | 非private | 无特别 |
异常关系 | 子类方法不能抛出被父类方法更多的异常 | 无特别 |
可见性关系 | 子类不能比父类访问权限更窄 | 无特别 |
6.Collection Collections
Collection:接口,集合类的接口,一个契约,提供了集合基本的大小,添加,清除,遍历方法等。
Collections:工具类,提供了很多静态方法,给集合提供一些查询,比较,排序,交换,线程安全化等方法。
7.Integer 缓存
package com.jue.test;
public class TestMain {
public static void main(String[] args) {
Integer i1 = 1;
Integer i11 = 1;
System.out.println(i1 == i11);
Integer i2 = 200;
Integer i22 = 200;
System.out.println(i2 == i22);
}
}
结果 :True,false
分析:反编译结果为 Integer i1 = Integer.valueOf(1);
可以看出,对于Integer i = 1;编译器做了额外的处理,即Integer.valueof();可以看出Integer对于一定 范围内的数字从Cache中取得,对于额外的,调用new创建。
故可以知道Integer的大小,默认是从-128到127,对于这个范围内的数组做了缓存的处理。 对于额外的,调用new创建
8.sleep方法和wait方法的区别
| wait | sleep |
所属类 | Object | Thread |
意义 | 让线程挂起 | 让线程休眠指定的时间 |
释放锁 | 是 | 否(这个跟锁本来就没有关系) |
恢复 | 1.有参:wait指定时间 | 1.根据参数长度自动恢复。 |
使用限制 | wait,notify必须持有当前对象锁的情况下调用 | 无特别 |
抛出异常 | 否 | 是 |
静态方法 | 否 | 是 |
9.HashMap和Hashtable的区别。
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
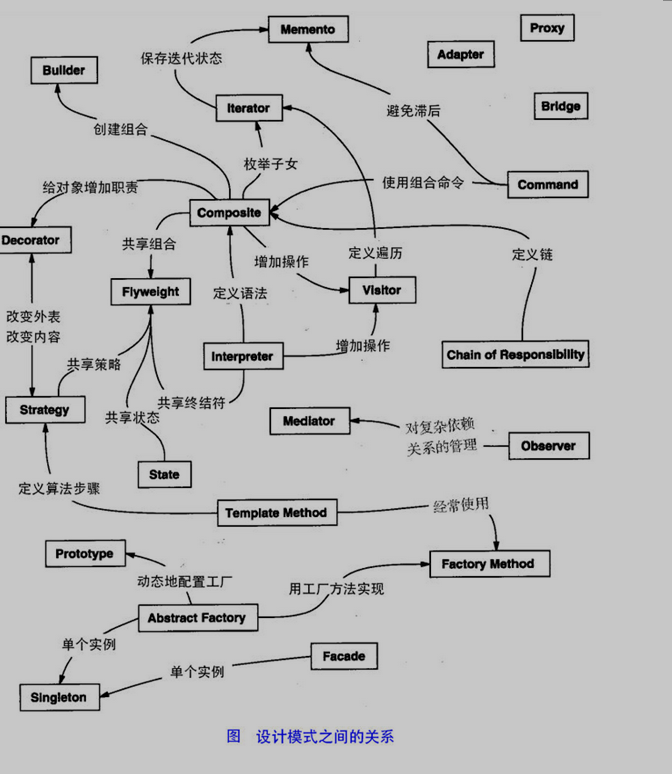
10、设计模式的分类
总体来说设计模式分为三大类:
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
其实还有两类:并发型模式和线程池模式。用一个图片来整体描述一下:
http://www.cnblogs.com/maowang1991/archive/2013/04/15/3023236.html
一:工厂模式:
(1):工厂模式主要是为创建对象提供过渡接口,以便将创建对象的具体过程屏蔽隔离起来,达到提高灵活性的目的。
首先,创建二者的共同接口:
[java] view plaincopy
- public interface Sender {
- public void Send();
- }
其次,创建实现类:
[java] view plaincopy
- public class MailSender implements Sender {
- @Override
- public void Send() {
- System.out.println("this is mailsender!");
- }
- }
[java] view plaincopy
- public class SmsSender implements Sender {
- @Override
- public void Send() {
- System.out.println("this is sms sender!");
- }
- }
最后,建工厂类:
[java] view plaincopy
- public class SendFactory {
- public Sender produce(String type) {
- if ("mail".equals(type)) {
- return new MailSender();
- } else if ("sms".equals(type)) {
- return new SmsSender();
- } else {
- System.out.println("请输入正确的类型!");
- return null;
- }
- }
- }
我们来测试下:
- public class FactoryTest {
- public static void main(String[] args) {
- SendFactory factory = new SendFactory();
- Sender sender = factory.produce("sms");
- sender.Send();
- }
- }
输出:this is sms sender!
a、多个工厂方法模式,是对普通工厂方法模式的改进,在普通工厂方法模式中,如果传递的字符串出错,则不能正确创建对象,而多个工厂方法模式是提供多个工厂方法,分别创建对象。关系图:
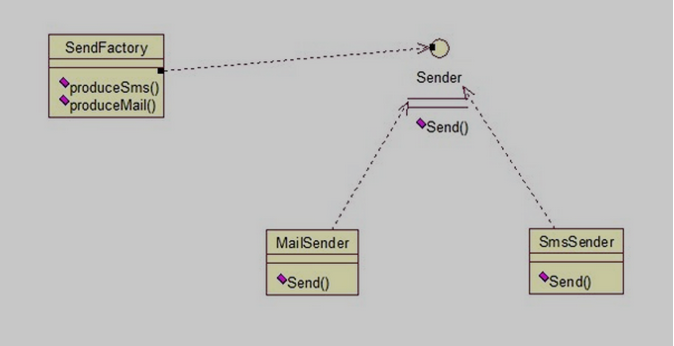
将上面的代码做下修改,改动下SendFactory类就行,如下:
[java] view plaincopypublic class SendFactory {
public Sender produceMail(){
- return new MailSender();
- }
- public Sender produceSms(){
- return new SmsSender();
- }
- }
测试类如下:
[java] view plaincopy
- public class FactoryTest {
- public static void main(String[] args) {
- SendFactory factory = new SendFactory();
- Sender sender = factory.produceMail();
- sender.Send();
- }
- }
输出:this is mailsender!
b、静态工厂方法模式,将上面的多个工厂方法模式里的方法置为静态的,不需要创建实例,直接调用即可。
[java] view plaincopy
- public class SendFactory {
- public static Sender produceMail(){
- return new MailSender();
- }
- public static Sender produceSms(){
- return new SmsSender();
- }
- }
[java] view plaincopy
- public class FactoryTest {
- public static void main(String[] args) {
- Sender sender = SendFactory.produceMail();
- sender.Send();
- }
- }
输出:this is mailsender!
总体来说,工厂模式适合:凡是出现了大量的产品需要创建,并且具有共同的接口时,可以通过工厂方法模式进行创建。在以上的三种模式中,第一种如果传 入的字符串有误,不能正确创建对象,第三种相对于第二种,不需要实例化工厂类,所以,大多数情况下,我们会选用第三种——静态工厂方法模式。
可以看出工厂方法的加入,使得对象的数量成倍增长。当产品种类非常多时,会出现大量的与之对应的工厂对象,这不是我们所希望的。因为如果不能避免这种情 况,可以考虑使用简单工厂模式与工厂方法模式相结合的方式来减少工厂类:即对于产品树上类似的种类(一般是树的叶子中互为兄弟的)使用简单工厂模式来实 现。
c、简单工厂和工厂方法模式的比较
工厂方法模式和简单工厂模式在定义上的不同是很明显的。工厂方法模式的核心是一个抽象工厂类,而不像简单工厂模式, 把核心放在一个实类上。工厂方法模式可以允许很多实的工厂类从抽象工厂类继承下来, 从而可以在实际上成为多个简单工厂模式的综合,从而推广了简单工厂模式。
反过来讲,简单工厂模式是由工厂方法模式退化而来。设想如果我们非常确定一个系统只需要一个实的工厂类, 那么就不妨把抽象工厂类合并到实的工厂类中去。而这样一来,我们就退化到简单工厂模式了。
d、抽象工厂模式
代码:
//抽象工厂类
public abstract class AbstractFactory {
public abstract Vehicle createVehicle();
public abstract Weapon createWeapon();
public abstract Food createFood();
}
//具体工厂类,其中Food,Vehicle,Weapon是抽象类,
public class DefaultFactory extends AbstractFactory{
@Override
public Food createFood() {
return new Apple();
}
@Override
public Vehicle createVehicle() {
return new Car();
}
@Override
public Weapon createWeapon() {
return new AK47();
}
}
//测试类
public class Test {
public static void main(String[] args) {
AbstractFactory f = new DefaultFactory();
Vehicle v = f.createVehicle();
v.run();
Weapon w = f.createWeapon();
w.shoot();
Food a = f.createFood();
a.printName();
}
}
在抽象工厂模式中,抽象产品 (AbstractProduct) 可能是一个或多个,从而构成一个或多个产品族(Product Family)。 在只有一个产品族的情况下,抽象工厂模式实际上退化到工厂方法模式。
六、总结。
(1)简单工厂模式是由一个具体的类去创建其他类的实例,父类是相同的,父类是具体的。
(2)工厂方法模式是有一个抽象的父类定义公共接口,子类负责生成具体的对象,这样做的目的是将类的实例化操作延迟到子类中完成。
(3)抽象工厂模式提供一个创建一系列相关或相互依赖对象的接口,而无须指定他们具体的类。它针对的是有多个产品的等级结构。而工厂方法模式针对的是一个产品的等级结构。
二、单例模式(Singleton)
单例对象(Singleton)是一种常用的设计模式。在Java应用中,单例对象能保证在一个JVM中,该对象只有一个实例存在。这样的模式有几个好处:
1、某些类创建比较频繁,对于一些大型的对象,这是一笔很大的系统开销。
2、省去了new操作符,降低了系统内存的使用频率,减轻GC压力。
3、有些类如交易所的核心交易引擎,控制着交易流程,如果该类可以创建多个的话,系统完全乱了。(比如一个军队出现了多个司令员同时指挥,肯定会乱成一团),所以只有使用单例模式,才能保证核心交易服务器独立控制整个流程。
首先我们写一个简单的单例类:
[java] view plaincopy
- public class Singleton {
- /* 持有私有静态实例,防止被引用,此处赋值为null,目的是实现延迟加载 */
- private static Singleton instance = null;
- /* 私有构造方法,防止被实例化 */
- private Singleton() {
- }
- /* 静态工程方法,创建实例 */
- public static Singleton getInstance() {
- if (instance == null) {
- instance = new Singleton();
- }
- return instance;
- }
- /* 如果该对象被用于序列化,可以保证对象在序列化前后保持一致 */
- public Object readResolve() {
- return instance;
- }
- }
这个类可以满足基本要求,但是,像这样毫无线程安全保护的类,如果我们把它放入多线程的环境下,肯定就会出现问题了,如何解决?我们首先会想到对getInstance方法加synchronized关键字,如下:
[java] view plaincopy
- public static synchronized Singleton getInstance() {
- if (instance == null) {
- instance = new Singleton();
- }
- return instance;
- }
但是,synchronized关键字锁住的是这个对象,这样的用法,在性能上会有所下降,因为每次调用getInstance(),都要对对象上锁,事实上,只有在第一次创建对象的时候需要加锁,之后就不需要了,所以,这个地方需要改进。我们改成下面这个:
[java] view plaincopy
- public static Singleton getInstance() {
- if (instance == null) {
- synchronized (instance) {
- if (instance == null) {
- instance = new Singleton();
- }
- }
- }
- return instance;
- }
1、最简单的实现
首先,能想到的最简单的实现是,把类的构造函数写成private的,从而保证别的类不能实例化此类。然后在类中返回一个静态示例并返回给调用者。这样,调用者就可以通过这个引用使用这个实例了。
public class Singleton{ private static final Singleton singleton = new Singleton(); public static Singleton getInstance(){ return singleton; } private Singleton(){ }}
如上例,外部使用者如果需要使用SingletonClass的实例,只能通过getInstance()方法,并且它的构造方法是private的,这样就保证了只能有一个对象存在。
2、性能优化--lazy loaded
上面的代码虽然简单,但是有一个问题----无论这个类是否被使用,都会创建一个instance对象。如果这个创建很耗时,比如说链接10000次数据库(夸张一点啦....),并且这个类还不一定会被使用,那么这个创建过程就是无用的,怎么办呢?
为了解决这个问题,我们想到的新的解决方案:
public class SingletonClass { private static SingletonClass instance = null; public static SingletonClass getInstance() { if(instance == null) { instance = new SingletonClass(); } return instance; } private SingletonClass() { } }
代码的变化有俩处----首先,把 instance 设置为 null ,知道第一次使用的时候判是否为 null 来创建对象。因为创建对象不在声明处,所以那个 final 的修饰必须去掉。
我们来想象一下这个过程。要使用 SingletonClass ,调用 getInstance()方法,第一次的时候发现instance时null,然后就创建一个对象,返回出去;第二次再使用的时候,因为这个 instance事static的,共享一个对象变量的,所以instance的值已经不是null了,因此不会再创建对象,直接将其返回。
这个过程就称为lazy loaded ,也就是迟加载-----直到使用的时候才经行加载。
这样写法也比较完美:但是还可以优化
public class SingletonClass{ private static SingletonClass instance = null; public static SingletonClass getInstance(){ if(instance == null){ synchronized(SingletonClass.class){ if(instance == null){ instance = new SingletonClass(); } } } return instance; } private SingletonClass(){ } }
通过单例模式的学习告诉我们:
1、单例模式理解起来简单,但是具体实现起来还是有一定的难度。
2、synchronized关键字锁定的是对象,在用的时候,一定要在恰当的地方使用(注意需要使用锁的对象和过程,可能有的时候并不是整个对象及整个过程都需要锁)。
到这儿,单例模式基本已经讲完了,结尾处,笔者突然想到另一个问题,就是采用类的静态方法,实现单例模式的效果,也是可行的,此处二者有什么不同?
首先,静态类不能实现接口。(从类的角度说是可以的,但是那样就破坏了静态了。因为接口中不允许有static修饰的方法,所以即使实现了也是非静态的)
其次,单例可以被延迟初始化,静态类一般在第一次加载是初始化。之所以延迟加载,是因为有些类比较庞大,所以延迟加载有助于提升性能。
再次,单例类可以被继承,他的方法可以被覆写。但是静态类内部方法都是static,无法被覆写。
最后一点,单例类比较灵活,毕竟从实现上只是一个普通的Java类,只要满足单例的基本需求,你可以在里面随心所欲的实现一些其它功能,但是静态类 不行。从上面这些概括中,基本可以看出二者的区别,但是,从另一方面讲,我们上面最后实现的那个单例模式,内部就是用一个静态类来实现的,所以,二者有很 大的关联,只是我们考虑问题的层面不同罢了。两种思想的结合,才能造就出完美的解决方案,就像HashMap采用数组+链表来实现一样,其实生活中很多事 情都是这样,单用不同的方法来处理问题,总是有优点也有缺点,最完美的方法是,结合各个方法的优点,才能最好的解决问题!
三:建造者模式(Builder)
工厂类模式提供的是创建单个类的模式,而建造者模式则是将各种产品集中起来进行管理,用来创建复合对象,所谓复合对象就是指某个类具有不同的属性,其实建造者模式就是前面抽象工厂模式和最后的Test结合起来得到的。我们看一下代码:
还和前面一样,一个Sender接口,两个实现类MailSender和SmsSender。最后,建造者类如下:
[java] view plaincopy
- public class Builder {
- private List<Sender> list = new ArrayList<Sender>();
- public void produceMailSender(int count){
- for(int i=0; i<count; i++){
- list.add(new MailSender());
- }
- }
- public void produceSmsSender(int count){
- for(int i=0; i<count; i++){
- list.add(new SmsSender());
- }
- }
- }
测试类:
[java] view plaincopy
- public class Test {
- public static void main(String[] args) {
- Builder builder = new Builder();
- builder.produceMailSender(10);
- }
- }
从这点看出,建造者模式将很多功能集成到一个类里,这个类可以创造出比较复杂的东西。所以与工程模式的区别就是:工厂模式关注的是创建单个产品,而建造者模式则关注创建符合对象,多个部分。因此,是选择工厂模式还是建造者模式,依实际情况而定。
四:原型模式(Prototype)
原型模式虽然是创建型的模式,但是与工程模式没有关系,从名字即可看出,该模式的思想就是将一个对象作为原型,对其进行复制、克隆,产生一个和原对象类似的新对象。本小结会通过对象的复制,进行讲解。在Java中,复制对象是通过clone()实现的,先创建一个原型类:
[java] view plaincopy
- public class Prototype implements Cloneable {
- public Object clone() throws CloneNotSupportedException {
- Prototype proto = (Prototype) super.clone();
- return proto;
- }
- }
很简单,一个原型类,只需要实现Cloneable接口,覆写clone方法,此处clone方法可以改成任意的名称,因为Cloneable接口 是个空接口,你可以任意定义实现类的方法名,如cloneA或者cloneB,因为此处的重点是super.clone()这句 话,super.clone()调用的是Object的clone()方法,而在Object类中,clone()是native的,具体怎么实现,我会 在另一篇文章中,关于解读Java中本地方法的调用,此处不再深究。在这儿,我将结合对象的浅复制和深复制来说一下,首先需要了解对象深、浅复制的概念:
浅复制:将一个对象复制后,基本数据类型的变量都会重新创建,而引用类型,指向的还是原对象所指向的。
深复制:将一个对象复制后,不论是基本数据类型还有引用类型,都是重新创建的。简单来说,就是深复制进行了完全彻底的复制,而浅复制不彻底。
此处,写一个深浅复制的例子:
[java] view plaincopy
- public class Prototype implements Cloneable, Serializable {
- private static final long serialVersionUID = 1L;
- private String string;
- private SerializableObject obj;
- /* 浅复制 */
- public Object clone() throws CloneNotSupportedException {
- Prototype proto = (Prototype) super.clone();
- return proto;
- }
- /* 深复制 */
- public Object deepClone() throws IOException, ClassNotFoundException {
- /* 写入当前对象的二进制流 */
- ByteArrayOutputStream bos = new ByteArrayOutputStream();
- ObjectOutputStream oos = new ObjectOutputStream(bos);
- oos.writeObject(this);
- /* 读出二进制流产生的新对象 */
- ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
- ObjectInputStream ois = new ObjectInputStream(bis);
- return ois.readObject();
- }
- public String getString() {
- return string;
- }
- public void setString(String string) {
- this.string = string;
- }
- public SerializableObject getObj() {
- return obj;
- }
- public void setObj(SerializableObject obj) {
- this.obj = obj;
- }
- }
- class SerializableObject implements Serializable {
- private static final long serialVersionUID = 1L;
- }
要实现深复制,需要采用流的形式读入当前对象的二进制输入,再写出二进制数据对应的对象。
//其他几种模式
我们接着讨论设计模式,上篇文章我讲完了5种创建型模式,这章开始,我将讲下7种结构型模式:适配器模式、装饰模式、代理模式、外观模式、桥接模式、组合模式、享元模式。其中对象的适配器模式是各种模式的起源,我们看下面的图:
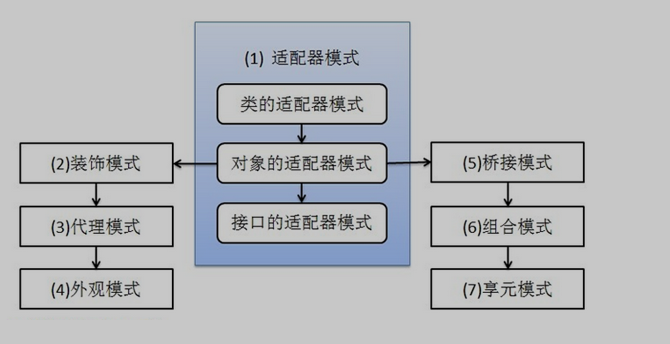
适配器模式将某个类的接口转换成客户端期望的另一个接口表示,目的是消除由于接口不匹配所造成的类的兼容性问题。主要分为三类:类的适配器模式、对象的适配器模式、接口的适配器模式。首先,我们来看看类的适配器模式,先看类图:
核心思想就是:有一个Source类,拥有一个方法,待适配,目标接口时Targetable,通过Adapter类,将Source的功能扩展到Targetable里,看代码:
[java] view plaincopy
- public class Source {
- public void method1() {
- System.out.println("this is original method!");
- }
- }
[java] view plaincopy
- public interface Targetable {
- /* 与原类中的方法相同 */
- public void method1();
- /* 新类的方法 */
- public void method2();
- }
[java] view plaincopy
- public class Adapter extends Source implements Targetable {
- @Override
- public void method2() {
- System.out.println("this is the targetable method!");
- }
- }
Adapter类继承Source类,实现Targetable接口,下面是测试类:
[java] view plaincopy
- public class AdapterTest {
- public static void main(String[] args) {
- Targetable target = new Adapter();
- target.method1();
- target.method2();
- }
- }
输出:
this is original method!
this is the targetable method!
这样Targetable接口的实现类就具有了Source类的功能
五:算法:
将之前介绍的所有排序算法整理成NumberSort类,代码
NumberSort




六:深入探索Java工作原理:JVM内存回收及其他
Java语言引入了Java虚拟机,具有跨平台运行的功能,能够很好地适应各种Web应用。同时,为了提高Java语言的性能和健壮性,还引入了如垃圾回收机制等新功能,通过这些改进让Java具有其独特的工作原理。
1.Java虚拟机
Java源程序通过编译器编译成.Class文件,然后java虚拟机中的java 解释器负责将字节码文件解释成为特定的机器码进行运行。
java是一种半编译半解释型语言。半编译是指:java源代码,会经过javac命令变成 .class文件。半解释是指: .class文件被jvm解释的过程。也就是因为jvm的半解释才有了java的动态语言特性:反射和annotation。
和android区别
alvik有自己的libdex库负责对.class进行处理。libdex主要对.class进行处理生成自己的dex文件。主要做的工作是,对虚拟机指令进行转换(dalvik是基于寄存器的,sun虚拟机是基于栈的),对类的静态数据进行归类、压缩。
dalvik基于寄存器,而JVM基于stack ,Dalvik执行的是特有的DEX文件格式,而JVM运行的是*.class文件格式。
优势:1、在编译时提前优化代码而不是等到运行时
2、 虚拟机很小,使用的空间也小;被设计来满足可高效运行多种虚拟机实例。
Java虚拟机的建立需要针对不同的软硬件平台来实现,既要考虑处理器的型号,也要考虑操作系统的种类。由此在SPARC结构、X86结构、MIPS和PPC等嵌入式处理芯片上,在UNIX、Linux、Windows和部分实时操作系统上都可实现Java虚拟机。
2.无用内存自动回收机制
而在Java运行环境中,始终存在着一个系统级的线程,专门跟踪内存的使用情况, 定期检测出不再使用的内存,并自动进行回收,避免了内存的泄露,也减轻了程序员的工作量。
1.JVM
JVM是Java平台的核心,为了让编译产生的字节码能更好地解释与执行,因此把JVM分成了6个部分:JVM解释器、指令系统、寄存器、栈、存储区和碎片回收区。
基于android的Socket通信 Android框架
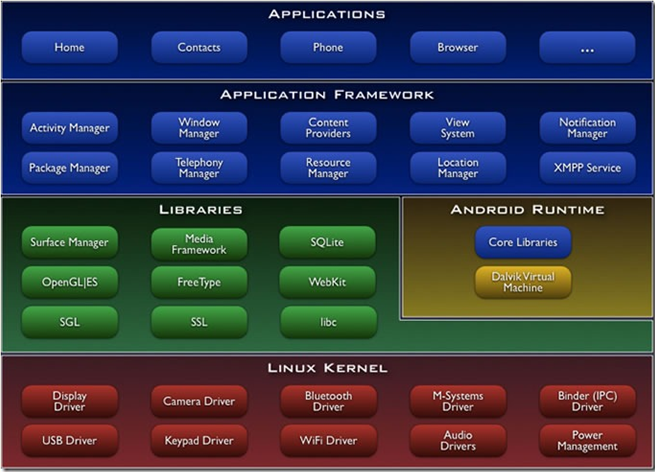
可以很明显看出,Android系统架构由5部分组成,分别是:Linux Kernel、Android Runtime、Libraries、Application Framework、Applications。第二部分将详细介绍这5个部分。
2、架构详解
现在我们拿起手术刀来剖析各个部分。其实这部分SDK文档已经帮我们做得很好了,我们要做的就是拿来主义,然后再加上自己理解。下面自底向上分析各层。
2.1、Linux Kernel
Android基于Linux 2.6提供核心系统服务,例如:安全、内存管理、进程管理、网络堆栈、驱动模型。Linux Kernel也作为硬件和软件之间的抽象层,它隐藏具体硬件细节而为上层提供统一的服务。
2.2、Android Runtime
Android 包含一个核心库的集合,提供大部分在Java编程语言核心类库中可用的功能。每一个Android应用程序是Dalvik虚拟机中的实例,运行在他们自己 的进程中。Dalvik虚拟机设计成,在一个设备可以高效地运行多个虚拟机。Dalvik虚拟机可执行文件格式是.dex,dex格式是专为Dalvik 设计的一种压缩格式,适合内存和处理器速度有限的系统。
大多数虚拟机包括JVM都是基于栈的,而Dalvik虚拟机则是基于寄存器的。 两种架构各有优劣,一般而言,基于栈的机器需要更多指令,而基于寄存器的机器指令更大。dx 是一套工具,可以將 Java .class 转换成 .dex 格式。一个dex文件通常会有多个.class。由于dex有時必须进行最佳化,会使文件大小增加1-4倍,以ODEX结尾。
Dalvik虚拟机依赖于Linux 内核提供基本功能,如线程和底层内存管理。
2.3、Libraries
Android包含一个C/C++库的集合,供Android系统的各个组件使用。这些功能通过Android的应用程序框架(application framework)暴露给开发者。下面列出一些核心库:
- 系统C库——标准C系统库(libc)的BSD衍生,调整为基于嵌入式Linux设备
- 媒体库——基于PacketVideo的OpenCORE。这些库支持播放和录制许多流行的音频和视频格式,以及静态图像文件,包括MPEG4、 H.264、 MP3、 AAC、 AMR、JPG、 PNG
- 界面管理——管理访问显示子系统和无缝组合多个应用程序的二维和三维图形层
- LibWebCore——新式的Web浏览器引擎,驱动Android 浏览器和内嵌的web视图
- SGL——基本的2D图形引擎
- 3D库——基于OpenGL ES 1.0 APIs的实现。库使用硬件3D加速或包含高度优化的3D软件光栅
- FreeType ——位图和矢量字体渲染
- SQLite ——所有应用程序都可以使用的强大而轻量级的关系数据库引擎
2.4、Application Framework
通过提供开放的开发平台,Android使开发者能够编制极其丰富和新颖的应用程序。开发者可以自由地利用设备硬件优势、访问位置信息、运行后台服务、设置闹钟、向状态栏添加通知等等,很多很多。
开发者可以完全使用核心应用程序所使用的框架APIs。应用程序的体系结构旨在简化组件的重用,任何应用程序都能发布他的功能且任何其他应用程序可以使用这些功能(需要服从框架执行的安全限制)。这一机制允许用户替换组件。
所有的应用程序其实是一组服务和系统,包括:
- 视图(View)——丰富的、可扩展的视图集合,可用于构建一个应用程序。包括包括列表、网格、文本框、按钮,甚至是内嵌的网页浏览器
- 内容提供者(Content Providers)——使应用程序能访问其他应用程序(如通讯录)的数据,或共享自己的数据
- 资源管理器(Resource Manager)——提供访问非代码资源,如本地化字符串、图形和布局文件
- 通知管理器(Notification Manager)——使所有的应用程序能够在状态栏显示自定义警告
- 活动管理器(Activity Manager)——管理应用程序生命周期,提供通用的导航回退功能
2.5、Applications
Android装配一个核心应用程序集合,包括电子邮件客户端、SMS程序、日历、地图、浏览器、联系人和其他设置。所有应用程序都是用Java编程语言写的。更加丰富的应用程序有待我们去开发!
一、Socket通信简介
Android 与服务器的通信方式主要有两种,一是Http通信,一是Socket通信。两者的最大差异在于,http连接使用的是“请求—响应方式”,即在请求时建立 连接通道,当客户端向服务器发送请求后,服务器端才能向客户端返回数据。而Socket通信则是在双方建立起连接后就可以直接进行数据的传输,在连接时可 实现信息的主动推送,而不需要每次由客户端想服务器发送请求。 那么,什么是socket?Socket又称套接字,在程序内部提供了与外界通信的端口,即端口通信。通过建立socket连接,可为通信双方的数据传输 传提供通道。socket的主要特点有数据丢失率低,使用简单且易于移植。
1.2Socket的分类
根据不同的的底层协议,Socket的实现是多样化的。本指南中只介绍TCP/IP协议族的内容,在这个协议族当中主要的Socket类型为流套接字 (streamsocket)和数据报套接字(datagramsocket)。流套接字将TCP作为其端对端协议,提供了一个可信赖的字节流服务。数据 报套接字使用UDP协议,提供数据打包发送服务。
二、Socket 基本通信模型
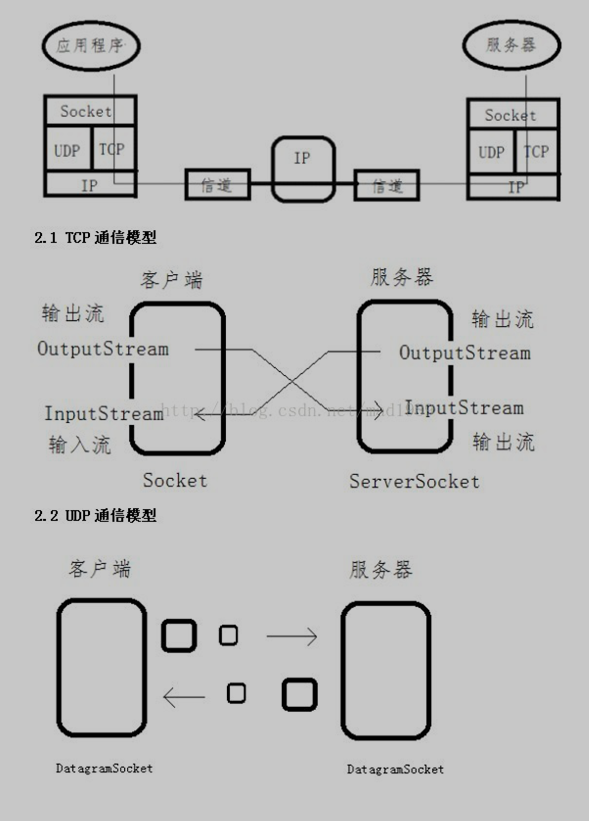
三、Socket基本实现原理
3.1基于TCP协议的Socket
服务器端首先声明一个ServerSocket对象并且指定端口号,然后调 用Serversocket的accept()方法接收客户端的数据。accept()方法在没有数据进行接收的处于堵塞状态。 (Socketsocket=serversocket.accept()),一旦接收到数据,通过inputstream读取接收的数据。
客户端创建一个Socket对象,指定服务器端的ip地址和端口号 (Socketsocket=newSocket("172.168.10.108",8080);),通过inputstream读取数据,获取服务器 发出的数据(OutputStreamoutputstream=socket.getOutputStream()),最后将要发送的数据写入到 outputstream即可进行TCP协议的socket数据传输。














 6068
6068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









