








大纲

上节课我们主要介绍了Kernel Logistic Regression,讨论如何把SVM的技巧应用在soft-binary classification上。方法是使用2-level learning,先利用SVM得到参数b和w,然后再用通用的logistic regression优化算法,通过迭代优化,对参数b和w进行微调,得到最佳解。然后,也介绍了可以通过Representer Theorem,在z空间中,引入SVM的kernel技巧,直接对logistic regression进行求解。本节课将延伸上节课的内容,讨论如何将SVM的kernel技巧应用到regression问题上。
Kernel Ridge Regression
1 Recall: Representer Theorem
首先回顾一下上节课学过的表示定理,对于任何L2-regularized linear model,如果我们存在这样的最小化问题,
我们可以把最优的w表示为
所以我们可以得出结论,任何的L2-regualrized线性模型都可以被kernelized
那么如何将regression模型变成kernel的形式呢?我们之前介绍的linear/ridge regression最常用的错误估计是squared error,即 err(y,wTz)=(y−wTz)2 。这种形式对应的解是analytic solution,即可以使用线性最小二乘法,通过向量运算,直接得到最优化解。那么接下来我们就要研究如何将kernel引入到ridge regression中去,得到与之对应的analytic solution。
2 Kernel Ridge Regression Problem
我们先把Ridge Regression 问题写下来

因为 w∗=∑Nn=1βnzn
所以我们可以将原问题转化为一个之与 β 有关的问题

不失一般性,我们可以通过求解 β 来获得最优值
总结一下Kernel Ridge Regression Problem就是就是利用表示定理,在ridge regression问题上应用核技巧
3 Solving Kernel Ridge Regression
这种凸二次最优化问题,只需要先计算其梯度,再令梯度为零即可。我们就可以得到 β 的闭式解

现在我们就可以很容易的做非线性回归啦
4 Linear versus Kernel Ridge Regression
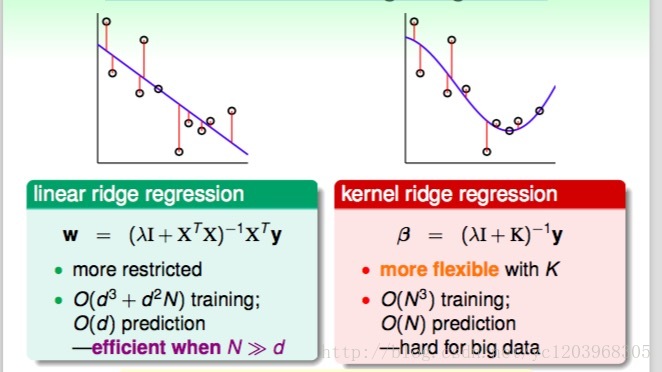
如上图所示,左边是linear ridge regression,是一条直线;右边是kernel ridge regression,是一条曲线。大致比较一下,右边的曲线拟合的效果更好一些。这两种regression有什么样的优点和缺点呢?对于linear ridge regression来说,它是线性模型,只能拟合直线;其次,它的训练复杂度是 O(d3+d2N) ,预测的复杂度是O(d),如果N比d大很多时,这种模型就更有效率。而对于kernel ridge regression来说,它转换到z空间,使用kernel技巧,得到的是非线性模型,所以更加灵活;其次,它的训练复杂度是O(N^3),预测的复杂度是O(N),均只与N有关。当N很大的时候,计算量就很大,所以,kernel ridge regression适合N不是很大的场合。比较下来,可以说linear和kernel实际上是效率(efficiency)和灵活(flexibility)之间的权衡。
Support Vector Regression Primal
1 Soft-Margin SVM versus Least-Squares SVM
我们在机器学习基石课程中介绍过linear regression可以用来做classification,那么上一部分介绍的kernel ridge regression同样可以来做classification。我们把kernel ridge regression应用在classification上取个新的名字,叫做least-squares SVM(LSSVM)

如上图所示:
Gaussian LSSVM和soft-margin Gaussian SVM有着相似的边界,但是Gaussian LSSVM有更多的SVs,SVs太多会带来一个问题,就是做预测的 g(x)=∑Nn=1βnK(xn,x) ,如果\beta_n非零值较多,那么g的计算量也比较大,降低计算速度。基于这个原因,soft-margin Gaussian SVM更有优势。因为soft-margin Gaussian SVM的 α 是稀疏的。这让我们想到上节课的Kernel Logistics Regression的 β 也是稠密的
那么,针对LSSVM中dense β 的缺点,我们能不能使用一些方法来的得到sparse β ,使得SV不会太多,从而得到和soft-margin SVM同样的分类效果呢?
2 Tube Regression

Tube Regression的做法是在回归线先上下划定一个区域,叫做Tube。数据点在这个区域内,则不计算错误,数据点落在Tube的外面,则计算错误。我们可以把错误函数表示为
3 Tube versus Squared Regression
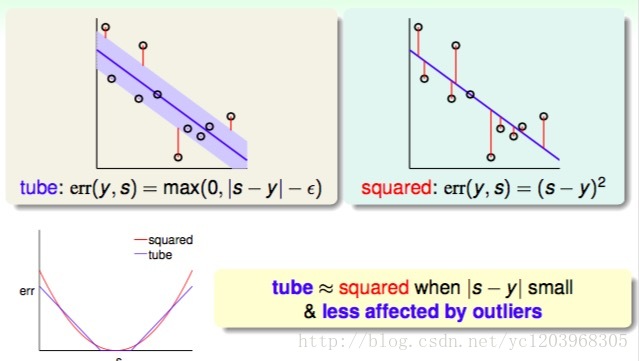
我们对比一下Tube Regression和Squared Regression的损失函数。我们可以发现
当 |s−y| 很小的时候, tube≈squared
tube Regression不易受outliers的影响
4 L2-Regularized Tube Regression

这个最优化问题,由于其中包含max项,并不是处处可微分的,所以不适合用GD/SGD来求解。而且,虽然满足representer theorem,有可能通过引入kernel来求解,但是也并不能保证得到sparsity β。从另一方面考虑,我们可以把这个问题转换为带条件的QP问题,仿照dual SVM的推导方法,引入kernel,得到KKT条件,从而保证解 β 是sparse的。
5 Standard Support Vector Regression Primal

现在我们已经有了Standard Support Vector Regression的初始形式,这还是不是一个标准的QP问题。我们继续对该表达式做一些转化和推导:

如上图右边所示,即为标准的QP问题,其中 ξ⋁n 和 ξ⋀n 分别表示lower tube violations和upper tube violations。这种形式叫做Support Vector Regression(SVR) primal。
6 Quadratic Programming for SVR
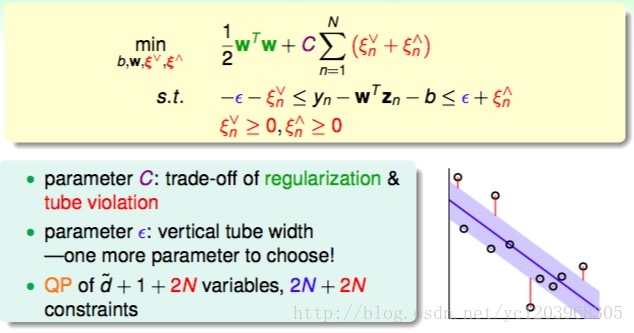
参数C是用来权衡regularization和tube violation的
参数 ϵ 是表示tube的宽度
这个QP问题有 d̂ +1+2N 个变量, 2N+2N 个约束
接下来我们要把它转化为对偶问题,并且进行核化,移除对 d̂ 的依赖
Support Vector Regression Dual
1 Lagrange Multipliers α∧ & α∨
首先,与SVM对偶形式一样,先令拉格朗日因子 α∧n & α∨n ,分别是与 ξ∧n & ξ∨n 不等式相对应。这里忽略了与 ξ∧n≥0 和 ξ∨n≤0 对应的拉格朗日因子。
然后,与SVM一样做同样的推导和化简,拉格朗日函数对相关参数偏微分为零,得到相应的KKT条件:

2 SVM Dual and SVR Dual
接下来,通过观察SVM primal与SVM dual的参数对应关系,直接从SVR primal推导出SVR dual的形式。

3 Sparsity of SVR Solution
我们的解 w=∑Nn=1(α∧n−α∨n)zn
对应的complementary slackness有:
对于在tube里面的点,我们有 |wTzn+b−yn|<ϵ ,此时的 ξ∧n=0 and ξ∨n=0 。
从而
进一步可得
α∧n=0
and
α∨n=0
从而 βn=0
对于在tube或者在tube外面的点, βn≠0 ,我们称为支持向量
所以SVR的解是稀疏的。
Summary of Kernel Models
1 Map of Linear Models
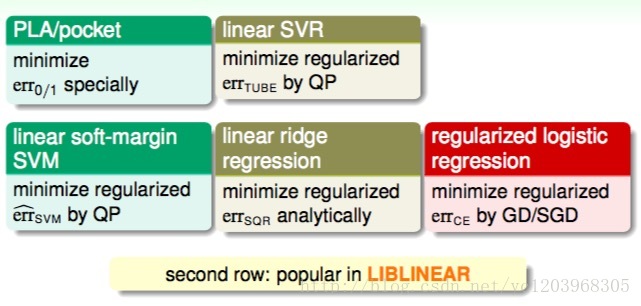
这部分将对我们介绍过的所有的kernel模型做个概括和总结。我们总共介绍过三种线性模型,分别是PLA/pocket,regularized logistic regression和linear ridge regression。
另外,我们介绍了linear soft-margin SVM,其中的error function是 errsvm ,可以通过标准的QP问题来求解。linear soft-margin SVM和PLA/pocket一样都是解决同样的问题。然后,还介绍了linear SVR问题,它与linear ridge regression一样都是解决同样的问题,从SVM的角度,使用 errtube ,转换为QP问题进行求解,这也是我们本节课的主要内容。
2 Map of Linear/Kernel Models
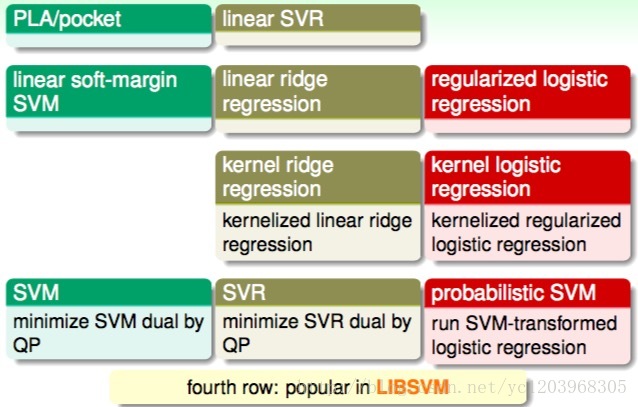
将Linear soft-margin SVM核化之后,我们可以得到SVM
将Linear SVR核化之后,我们可以得到SVR
将linear ridge regression核化之后,我们可以得到kernel ridge regression
将regularized logistic regression核化之后,我们可以得到 kernel logistic regression
- probabilistic SVM是先运行标准的SVM。然后利用logistic regression微调
总结:
第一行的算法,我们不常用,是因为表现不好。
第三行的算法,我们不常用,是因为解太稀疏,导致计算量大














 2501
2501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









