







我的开发环境:win10 Android studio 2.2 ndk 版本r12b 手机:Honor 5x
第一步:下载文件
从githup下载:https://github.com/rmtheis/tess-two
第二步:编译出so文件
首先打开dos命令行 win+R 键,输入cmd,回车。
切换到下载的项目目录 例如:我下载的项目目录如下:


如果没有配置ndk的环境变量需要这样编译:
例如:我的ndk路径:

编译命令如下:

执行命令后:
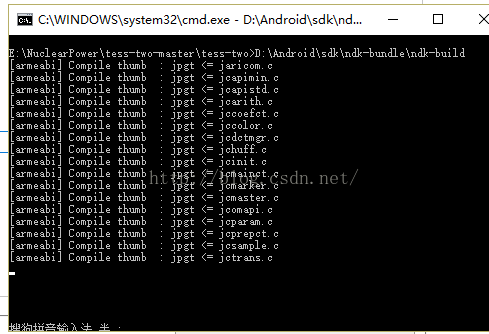
会依次编译armeabi armea-v7a arm64-v8a mips mips64 x86 x86——64 7种不同的so,编译时间大约40分钟。
编译好的so会保存在******\tess-two\libs目录下
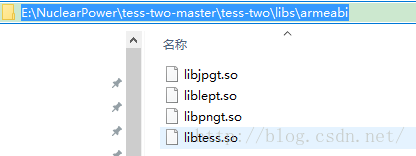
第三步:导入so文件和java源码
1.如果你没有在build.gridle中重定向so目录,将armeabi armeabi_v7a(一般这两个就可以了)复制到项目的src\main\jniLibs目录下(注意jniLibs的L是大写)。
2.导入java源码

复制com文件夹下面的所有文件到你的项目src\main\java目录下,这样做的好处是:不符合你要求的地方可以修改,打成jar包的话,只能查看源码不能修改。
我的教训:之前从网上下载别人编译好的so和jar遇到了很大的坑,所以希望我的读者朋友们自己去编译和配置开发环境。
第四部:配制语言包tessdata
将tessdata复制到手机内置存储的根目录下(当然其他目录也可以,需要在代码中指定路径)
第五部:简单使用
private static final String TESSBASE_PATH = Environment.getExternalStorageDirectory() + File.separator;
private static final String DEFAULT_LANGUAGE = "eng";//英文数据包
private static final String CHINESE_LANGUAGE = "chi_sim";//中文数据包
private static final String TAG = "TessTwoActivity";
TessBaseAPI baseApi = new TessBaseAPI();
baseApi.init(TESSBASE_PATH, DEFAULT_LANGUAGE);
Bitmap bitmap = BitmapFactory.decodeFile(Environment.getExternalStorageDirectory() + "/text.jpg");
baseApi.setImage(bitmaps[0]);
final String outputText = baseApi.getUTF8Text();
Log.e(TAG, "识别结果:" + outputText );至于TESSDATA_PATH为什么只指向了 根目录+“\”,可以从TessBaseAPI类的源码寻找答案,源码如下:
/**
* Initializes the Tesseract engine with the specified language model(s). Returns
* <code>true</code> on success.
*
* @see #init(String, String)
*
* @param datapath the parent directory of tessdata ending in a forward
* slash
* @param language an ISO 639-3 string representing the language(s)
* @param ocrEngineMode the OCR engine mode to be set
* @return <code>true</code> on success
*/
public boolean init(String datapath, String language, int ocrEngineMode) {
if (datapath == null)
throw new IllegalArgumentException("Data path must not be null!");
if (!datapath.endsWith(File.separator))
datapath += File.separator;
File datapathFile = new File(datapath);
if (!datapathFile.exists())
throw new IllegalArgumentException("Data path does not exist!");
// 答案就在这里--------------------------
File tessdata = new File(datapath + "tessdata");
if (!tessdata.exists() || !tessdata.isDirectory())
throw new IllegalArgumentException("Data path must contain subfolder tessdata!");
//noinspection deprecation
if (ocrEngineMode != OEM_CUBE_ONLY) {
for (String languageCode : language.split("\\+")) {
if (!languageCode.startsWith("~")) {
File datafile = new File(tessdata + File.separator +
languageCode + ".traineddata");
if (!datafile.exists())
throw new IllegalArgumentException("Data file not found at " + datafile);
}
}
}
boolean success = nativeInitOem(mNativeData, datapath, language, ocrEngineMode);
if (success) {
mRecycled = false;
}
return success;
}
其他问题:
1.导入tess-two使用过程中,可能一言不合就崩溃,崩溃一次找到原因解决或者try catch捕获异常应给出Toast 或其他提示信息。
推荐:
推荐一个githup上面的项目,简单描述一下:
打开摄像头,然后屏幕触摸调整识别框的大小,点击拍照后识别文字,有点像有道词典的摄像头识别单词。
githup下载地址android-ocr-master
参考:
http://www.cnblogs.com/muyun/archive/2012/06/12/2546693.html















 6956
6956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









