









昨天写了【XML解析(一)】SAX解析XML 和【XML解析(二)】DOM解析XML两篇文章,有兴趣的朋友可以去看一下,今天我们来学习一下PULL解析XML,刚好可以跟SAX和DOM解析XML的两种方式对比学习,其实Android里面解析XML最常用的也就这三种,而这三种并不一定拘泥于Android开发,同样也可以用在J2EE开发中,下面我们进入本篇文章的学习。
一、概述
PULL?,拉?,肯定不是什么的简称了,PULL是Android内置的解析XML的方式,但是并不局限与Android,也可以是J2EE。
PULL解析具有与SAX类似的特点,提供了与SAX类似的事件,比如:开始元素事件和结束元素事件,看过【XML解析(一)】SAX解析XML 的朋友或者使用过SAX解析XML的朋友是否还记得SAX解析的几个重要的事件吗?这里我简单复习一下SAX的几个重要的事件
SAX的几个重要的事件
- startDocument():XML文档解析开始的时候触发,只会调用一次,我们可以在这里做一些解析前的准备工作
- startElement():元素或标签解析开始的时候触发
- characters:startElement触发后立即触发
- endElement():元素或标签解析结束的时候触发
- endDocument():XML文档解析结束后触发,只会触发一次
PULL的事件(仅有五个)
- START_DOCUMENT:开始文档解析
- START_TAG:解析元素
- TEXT:解析文本
- END_TAG:结束元素解析
- END_DOCUMENT:结束文档解析
下面做个事件的简单对比(类似)
| PULL | SAX |
|---|---|
| START_DOCUMEN | startDocument |
| START_TAG | startElement |
| TEXT | characters |
| END_TAG | endElement |
| END_DOCUMENT | endElement |
Pull只有一个重要的事件next()
PULL解析XML的优点:
- 解析速度快
- 占用内存小,消耗的资源少
- 简单,易集成(Android)
- 支持生成,修改,删除XML文件
PULL解析适用于:
- Android
- 速度快,效率高的J2EE
大概了解了pull,下面我们通过一个简单的Demo简单学习一下pull 解析 xml
二、PULL解析XML实战
新建一个Android项目PullParseXmlDemo,因为android集成pull,无需导入jar包,为了方便这里将整个demo的目录结构给出,在文章末尾将会把demo贴上,方便大家下载导入eclipse测试。
目录结构:
PULL解析步骤:
- 加载xml资源
- 得到pull解析器XmlPullParser
- 使用解析器解析
1、新建xml测试文件,uses.xml
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="1">
<name>毕向东</name>
<password>bxd123</password>
</user>
<user id="2">
<name>韩顺平</name>
<password>hsp123</password>
</user>
<user id="3">
<name>马士兵</name>
<password>msb123</password>
</user>
</users>2、新建JavaBean,User.java
package com.example.pullparsexmldemp;
public class User{
private long id;
private String name;
private String password;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
3、新建一个解析核心方法getUsers()封装到一个工具类中,XmlParseUtils.java
public static List<User> getUsers() throws Exception {
List<User> users = null;
User user = null;
// 加载xml资源
InputStream is = XmlParseUtils.class.getClassLoader()
.getResourceAsStream("users.xml");
// 得到Pull解析器
XmlPullParser pullParser = Xml.newPullParser();
// 设置Xml输入流
pullParser.setInput(is, "utf-8");
int event = pullParser.getEventType(); // 触发第一个事件
while (event != XmlPullParser.END_DOCUMENT) {
switch (event) {
case XmlPullParser.START_DOCUMENT:
Log.e(TAG, pullParser.getName()+"----START_DOCUMENT");
users = new ArrayList<User>();
break;
case XmlPullParser.START_TAG:
if ("user".equals(pullParser.getName())) {
Log.e(TAG, pullParser.getName()+"----START_TAG");
user = new User();
int id = Integer.valueOf(pullParser.getAttributeValue(0));
user.setId(id);
}
if (user != null) {
if ("name".equals(pullParser.getName())) {
Log.e(TAG, pullParser.getName()+"----START_TAG");
// 注意是nextText()取标签之间的文本,而不是getText()
// getText()返回的是当前触发事件的字符描述
user.setName(pullParser.nextText());
}
if ("password".equals(pullParser.getName())) {
Log.e(TAG, pullParser.getName()+"----START_TAG");
user.setPassword(pullParser.nextText());
}
}
break;
case XmlPullParser.END_TAG:
if ("user".equals(pullParser.getName())) {
Log.e(TAG, pullParser.getName()+"----END_TAG");
users.add(user);
user = null;
}
break;
}
event = pullParser.next();
}
if(event == XmlPullParser.END_DOCUMENT){
Log.e(TAG, pullParser.getName()+"----END_DOCUMENT");
}
return users;
}这里的解析过程和SAX解析过程非常类似,就不多说了,这里先将日志打印,方便我们下面分析pull解析原理。
OK,PULL解析XML的核心就在getUsers()方法中了,接下来是测试是否解析成功了
Android的单元测试:
测试结果:
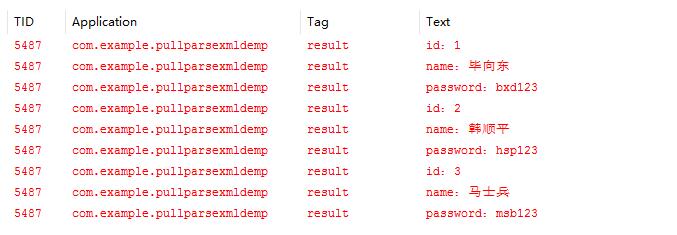
OK,可以看到使用PULL成功解析XML,下面我们看一下下面的日志来简单分析一下PULL解析的过程:
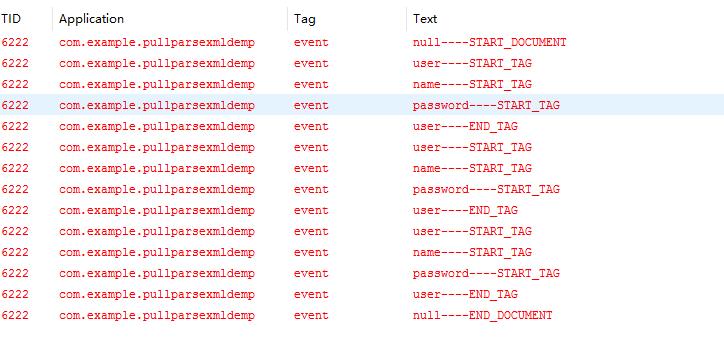
可以看到,当文档解析开始的时候START_DOCUMENT事件触发,仅触发了一次,接下来没遇到一个新的标签的开始都触发了STAET_TAG时间,每个标签的结束都触发了END_TAG,所以START_TAG和END_TAG事件触发的次数和标签是成对出现的,即有开始就有结束,最后文档解析结束END_DOCUMENT触发。原理过程分析结束,前面我们说了PULL不仅可以解析XML,还可以生成,修改,删除XML。下面我们通过PULL生成XML做个测试
三、PULL生成XML
PULL生成XML步骤:
- 设置输出源
- 得到xml序列化类xmlSerializer
- 使用序列化类生成XML
第一步:在工具类中添加一个方法createXml(List users,OutputStream outputStream)
XmlSerializer xmlSerializer = Xml.newSerializer();
// 设置输出源及编码
xmlSerializer.setOutput(outputStream,"utf-8");
// 参数1:设置编码
// 参数2:standalone 用来表示该文件是否呼叫其它外部的文件。若值是 true
// 表示没有呼叫外部文件,若值是 false 则表示有呼叫外部文件。默认值是true
xmlSerializer.startDocument("utf-8", true);
// 生成users开始标签
xmlSerializer.startTag(null, "users");
for(User user : users){ // 每循环一次生成一个user
// 生成user标签和id属性
xmlSerializer.startTag(null, "user");
xmlSerializer.attribute(null, "id", user.getId()+"");
// 生成name开始标签
xmlSerializer.startTag(null, "name");
// 设置name标签的文本
xmlSerializer.text(user.getName());
// 闭合name标签
xmlSerializer.endTag(null, "name");
// ...
xmlSerializer.startTag(null, "password");
xmlSerializer.text(user.getPassword());
xmlSerializer.endTag(null, "password");
// 闭合user标签
xmlSerializer.endTag(null, "user");
}
xmlSerializer.endTag(null, "users"); // 闭合users标签
xmlSerializer.endDocument(); // 结束文档
outputStream.flush(); // 将所有缓冲区的数据全部写到文件中
outputStream.close(); // 一定不要忘了关闭流
}注释说的差不多了,是不是觉得PULL生成XML文件好简单。
说明:startDocument的两个参数分别设置生成的xml文件头部的encoding和standalone属性,下面我们看了生成的文件就知道了。
第二步、在PullParseXmlTest.java中添加一个测试方法testCreateXml()
/**
* 测试生成xml
* @throws Exception
*/
public void testCreateXml() throws Exception{
// this.getContext().getFilesDir()得到的是/data/data/files/
File file = new File(this.getContext().getFilesDir(),"users.xml");
FileOutputStream fileOutputStream = new FileOutputStream(file);
List<User> users = new ArrayList<User>();
User user1 = new User();
user1.setId(1);
user1.setName("毕向东");
user1.setPassword("bxd123");
users.add(user1);
User user2 = new User();
user2.setId(2);
user2.setName("韩顺平");
user2.setPassword("hsp123");
users.add(user2);
User user3 = new User();
user3.setId(3);
user3.setName("马士兵");
user3.setPassword("msb123");
users.add(user3);
XmlParseUtils.createXml(users, fileOutputStream);
}没什么好说的,直接运行测试
下面我们看看生成的users.xml文件
1、打开DDMS视图:
2、找到当前应用的files文件夹
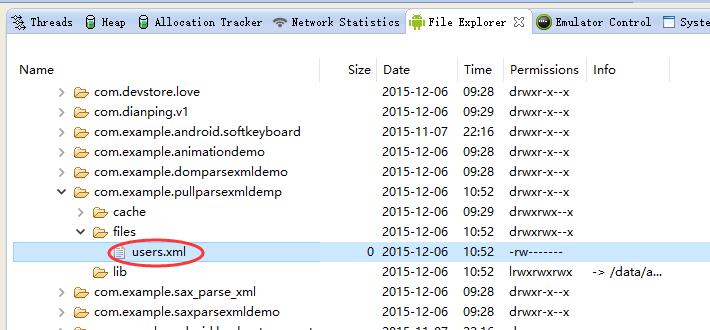
3、将生成的xml导出
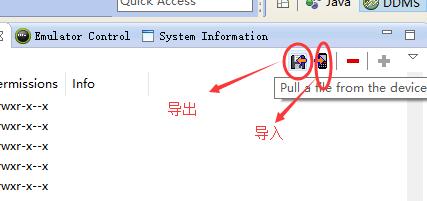
这里也可以用adb pull [remote] [local]:命令文件
adb命令参考:adb常用命令
用编辑器打开users.xml可以看到(格式化后):
<?xml version='1.0' encoding='utf-8' standalone='yes' ?>
<users>
<user id="1">
<name>毕向东</name>
<password>bxd123</password>
</user>
<user id="2">
<name>韩顺平</name>
<password>hsp123</password>
</user>
<user id="3">
<name>马士兵</name>
<password>msb123</password>
</user>
</users>注意看xml文件头,encoding和standalone属性都是startDocument()的两个参数知道指定的
<?xml version='1.0' encoding='utf-8' standalone='yes' ?>- 关于PULL,SAX,DOM解析XML
PULL解析XML与SAX类似,具有解析速度快,效率高,占用资源少的特点,而DOM解析XML虽然简单,可以随机访问文档树的任何一个节点,可以知道整个文档树结构和整个文档树的所有信息,但正是由于在内存中要形成这样的一个文档树,所以导致了解析速度慢,占用资源大,这对于资源多,不要求效率的场合是一种不错的选择,但是对于Android等内存小,cpu资源宝贵的移动设备来说是致命的,SAX虽然速度快,占用资源,但由于无法修改,生成XML,所以这就是为什么Android集成PULL,而不是SAX和DOM的原因吧。
总结:XML解析,生成,修改XML都好简单,Android集成PULL,掌握PULL必须的。
上面这篇文章由于个人理解,如果有理解错的地方,欢迎指出,与君共勉,一起进步。















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









