







1.爬取中国大数据首页的链接和标题
2.出现好多错误,特别是正则表达式
爬取的样式为:
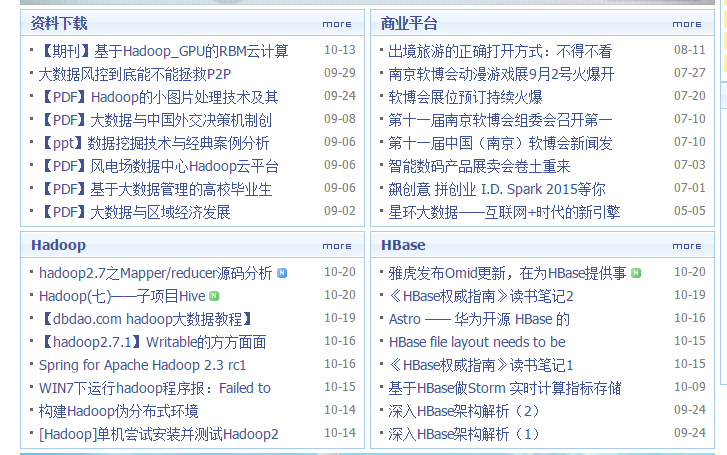
部分源代码:

#coding:utf-8
import re
import urllib
#获取网页
def getHtml(url):
page=urllib.urlopen(url)
html=page.read()
return html
#用正则匹配相应的链接和标题
def getText(html):
reg=r'</span><a href="((YeJieDongTai|YingYongAnLi|JieJueFangAn|Hadoop|HBase|QiTa|JiShuBoKe)/\d{4,5}\.html)"(.*?)>(.*?)</a>'
textre=re.compile(reg)
textlist=re.finditer(textre,html)
#print type(textlist)测试返回内容的类型,注意finditer和findall的区别
return textlist
url='http://www.thebigdata.cn/'
html=getHtml(url)
list=getText(html)
#将获取的内容写入文件
a=open(r"D:\Python test\restart.txt",'a+')
for item in list:
a.write(item.group(1)+item.group(4)+'\n')
#当以列表形式返回时,读取方式应为:
#a.write(item[1]+item[4]+'\n')
a.close()
小某说:
分享一下自己所犯的奇葩的错误。
1.刚开始写的时候,完完全全按照爬取图片的格式来的,出现一系列错误,后来发现这是不可行的。主要是对urlretrieve()的用法没有掌握清楚。urlretrieve()是将url定位到的html文件下载到本地的磁盘中,这次爬取的内容需要写入文件中。关于urllib模块中的方法可以参考
http://www.cnblogs.com/sysu-blackbear/p/3629420.html
2.然后改变方法重新爬取,正则又出现了很多错误
reg=r'target="_blank" title=(.*?)>'
reg=r'target="_blank" title?=?(.*?)>'?:可以表示匹配零次或一次,即前面的内容可有可无;也可以表示非贪婪匹配。重点在于后者。
常用的非贪婪匹配模式有:
- *?重复任意次,但尽可能少重复
- +?重复一次或更多次,但尽可能少重复
3.总之,正则匹配错误还很多。匹配成功后,如上面代码中所示,写入文件时由于有多个分组便又出现错误。主要是findall()和finditer()的区别:
findall():返回所有匹配的字符串,并存为列表,存入文件时使用列表的读取方法。
finditer():返回一个迭代器,存入文件时要调用group()
吼吼哈哈,补上昨天的博客,好开森,可能有写的不好的地方,小某就先闪啦!!














 3551
3551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









