







PS:本文中的大部分代码和案例数据来自《机器学习实践》这本书,但是原文中代码几乎没有注解,直接阅读难度很大,我在调试时增加了更详细的注解和步骤上的描述,方便理解。
k-近邻算法原理是存在一个训练集,并且训练集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。选择样本数据集中前k个最相似的数据中出现次数最多的分类,作为新数据的分类
从原理来看它是种处理分类场景的监督学习方式。
举个简单的例子先了解下:
from numpy import *
#简单介绍k-近邻算法的训练集
def createDataSet() :
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
#inX:需要被分类的内容
#dataSet:训练集的特性
#lables:训练集的分类
#k k-近邻算法的k
def classify0(inX, dataSet, labels, k) :
#shape[0]获得每列有多少行,shape[1]获得每行有多少列
dataSetSize = dataSet.shape[0]
#tile铺建一个矩阵,每个元素是inX,dataSetSize行1列
dataSetNew = tile(inX,(dataSetSize,1))
#Python矩阵可以直接相减,Java要写多少行啊!
diffMat = dataSetNew-dataSet
sqDiffMat = diffMat**2
#每一行相加合并
sqDistances = sqDiffMat.sum(axis=1)
#开根后得到的是欧式距离
distances = sqDistances**0.5
#按行进行索引排序,请注意是索引排序,不是内容排序
sortedDistIndicies = distances.argsort()
#classCount是个字典值(map)
classCount={}
for i in range(k) :
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#对classCount这个map针对第1列(从0列开始)进行倒序排序,组成个新矩阵
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
输入一个x,y,求是A还是B
group,labels = KNN.createDataSet()
inX=[1.2,1.3]
trainingResult = KNN.classify0(inX,group,labels,2)
print(trainingResult)
通过在这个例子我们对k-近邻算法有了直观的理解,下面我们要严格按照机器学习的开发步骤来研究个更复杂的实际问题。
复杂的案例:
某女士将相亲网站上认识的男士分为很喜欢、一般喜欢、不喜欢3种类型,并收集了他们每年旅行公里数、花费到玩游戏时间的比例、每周吃多少冰激凌这3个特性,通过这些数据来预测她对某个男士感兴趣的程度。
机器学习步骤如下:
1收集数据
将收集到的数据进行格式化处理,整理成代码能处理的格式
2准备输入数据
将文件格式的数据转化成python能处理的矩阵
3分析输入数据
用matPlotLib画二维图观察数据的规律
4训练算法
k-近邻算法是固定的算法,此处不需要自己训练
5测试算法
用测试集对算法进行运算和结果统计,观察准确率
6使用算法
将算法封装成一个普通人可以使用的应用程序。
1收集数据:
最终处理出来的可被机器识别的数据文件在git上(https://github.com/yejingtao/forblog/blob/master/MachineLearning/trainingSet/datingTestSet.txt),格式如下:
40920 8.326976 0.953952 3
14488 7.153469 1.673904 2
26052 1.441871 0.805124 1
75136 13.147394 0.428964 1
38344 1.669788 0.134296 1
72993 10.141740 1.032955 1
35948 6.830792 1.213192 3
2准备输入数据:
需要敲代码来解析文件转化成矩阵格式:
代码:
def file2Matrix(fileName) :
fr = open(fileName)
arrayOfLines = fr.readlines()
#得到文本行数
numberOfLines = len(arrayOfLines)
#创建以零填充的(numberOfLines,3)规模的矩阵
#形如[[0,0,0]
# [0,0,0]]
returnMat = zeros((numberOfLines,3))
#带返回的类别结果集
classLabelVector = []
index = 0
for line in arrayOfLines :
#trip,去除换行
line = line.strip()
#根据tab空格进行分割
lisfForLine = line.split('\t')
#lisfForLine里共4列,取前3个元素放入特性矩阵
returnMat[index,:] = lisfForLine[0:3]
#取最后一个值放入classLableVector
classLabelVector.append(int(lisfForLine[-1]))
index+=1
return returnMat,classLabelVector
3分析输入数据
用matplotlib生成二维图来观察训练集特性与分类的关系
图形代码:
from numpy import *
import matplotlib.pyplot as plt
mat,lab = file2Matrix.file2Matrix('C:\\2017\\提高\\机器学习\\训练样本\\datingTestSet.txt')
fig = plt.figure()
ax = fig.add_subplot(111)
#0和1代表的是训练集特性里的前两列:旅行公里数和玩游戏的时间比例
ax.scatter(mat[:,1],mat[:,2],15.0*array(lab),15.0*array(lab))
plt.show()
旅行公里数和玩游戏时间比例这两个特性与结果集的关系输出:
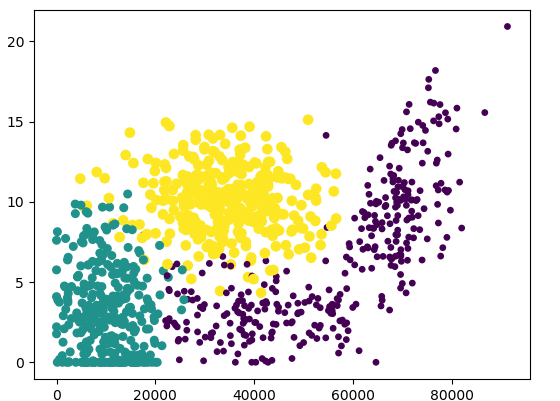
看得出有很明显的规律性在里面的
再来看玩游戏花费的时间比例和吃冰激凌这两个特性与结果集的关系:
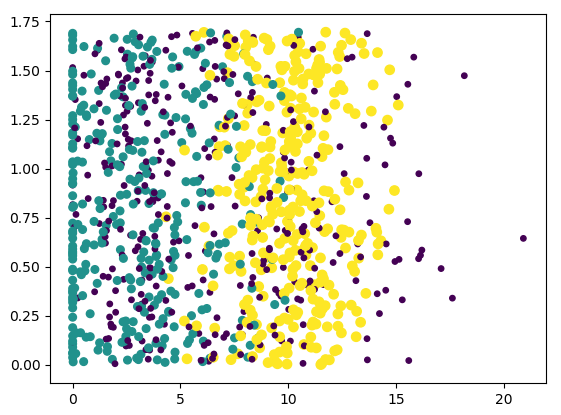
纵坐标是冰淇淋的特性,从图中看得出对结果集影响不明显。
4训练算法
k-近邻算法不需要训练,是个固化的成型算法,但是有一点需要注意,就是在欧氏距离计算前要对数据进行一次处理。
特性一是旅游的公里数,数值是四位甚至五位数,玩游戏的时间比例是百分比,也就是说是0-1之间的小数,如果直接套用欧氏距离那么第二个距离差将因为刻度尺不同而被稀释的微乎其微,所以要对数据进行统一的刻度处理,学名叫“归一化处理”。
处理公式:newValue=(oldValue-minValue)/(maxValue-minValue)
对应到代码语言是:
#对矩阵dataSet进行归一化处理
#normDataSet是归一后的新矩阵
#ranges是刻度尺
#min是每列最小值
def autoNorm(dataSet) :
#每列的最小值
min = dataSet.min(0)
# 每列的最大值
max = dataSet.max(0)
ranges = max-min
#构建一个跟dataSet一样的0矩阵
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(min,(m,1))
normDataSet = normDataSet/tile(ranges, (m, 1))
#normDataSet = linalg.solve(normDataSet,tile(max, (m, 1)))
return normDataSet,ranges,min
5测试算法:
训练集和测试集不能重复,所以我们将1000个样本集拆成了900+100的组合,用900个做训练用100个做测试,测试程序如下:
#测试算法,将1000个样本集拆成900个训练集和100个测试集
def dataClassTest() :
#测试集的比例
hoRatio = 0.10
mat, lab = file2Matrix.file2Matrix('C:\\2017\\提高\\机器学习\\训练样本\\datingTestSet.txt')
normDataSet, ranges, min = autoNorm(mat)
m = normDataSet.shape[0]
#测试集的个数
numTestVecs = int(m*hoRatio)
#统计测试集错误数量
erroCount = 0.0
for i in range(numTestVecs) :
#classify0的4个参数意义:测试特性、训练集特性矩阵、训练集分类集合、k
classifierResult = classify0(normDataSet[i,:],normDataSet[numTestVecs:m,:],lab[numTestVecs:m],4)
#判断测试结果
if classifierResult!=lab[i] : erroCount+=1
print('The total error rate is: %f' %(erroCount/float(numTestVecs)))
测试结果是0.04,成功率是96%,还算不错的结果
6使用算法,假设我们对96%的成功率已经满意了,决定将其投入到实用,我们需要对算法封装成一个更友好的可以被普通人使用的应用程序,代码如下:
def classifyPerson() :
resultList = ['很喜欢','有点喜欢','不感冒']
game = float(input('你每天花在玩游戏上的时间的比例(0-1之间小数表示):'))
fly = float(input('你每年旅游的公里数:'))
iceCream = float(input('你每年大约吃多少升冰激凌:'))
mat, lab = file2Matrix.file2Matrix('C:\\2017\\提高\\机器学习\\训练样本\\datingTestSet.txt')
normDataSet, ranges, min = autoNorm(mat)
inArray = ([fly,game,iceCream])
#这里注意要对客户输入做一次归一化处理
classifierResult = classify0((inArray-min)/ranges, normDataSet, lab, 4)
print("这个男人匹配结果是: %s" %resultList[classifierResult-1])
这样可以根据输入的3个参数来给出96%准确率的匹配结果啦!
再看个k-近邻算法做图像处理的案例:
我们将手写的数字例如:

处理成0和1标识的32*32的矩阵格式,例如:

然后准备好0-9每个数字几十至上百种书写格式的文件做为训练集,利用k-近邻算法来对手写数字进行图像处理。
训练集在git上:https://github.com/yejingtao/forblog/tree/master/MachineLearning/trainingSet/digits/trainingDigits
测试集在git上:https://github.com/yejingtao/forblog/tree/master/MachineLearning/trainingSet/digits/trainingDigits
核心代码如下:
#将图像文件32*32矩阵转化成1*1024矩阵
def image2Vector(fileName) :
#构建1维1024长度的0数组
returnVector = zeros((1,1024))
fi = open(fileName)
#读取每行文件内容,拼接到returnVector中
for i in range(32) :
lineSet = fi.readline()
for j in range(32) :
returnVector[0,32*i+j]=int(lineSet[j])
return returnVector
#根据训练集和测试集来验证k-近邻算法的成功率
def handWirteTest() :
#训练集所在目录
trainingDir = 'C:\\2017\\提高\\机器学习\\训练样本\\digits\\trainingDigits'
#测试集所在目录
testDir = 'C:\\2017\\提高\\机器学习\\训练样本\\digits\\testDigits'
#训练集的结果集
hwLabels=[]
#获取目录下所有文件
trainingFileList = listdir(trainingDir)
m = len(trainingFileList)
#trainingMat存放的最终参与训练的训练集
trainingMat = zeros((m,1024))
for i in range(m) :
fileFileNameStr = trainingFileList[i]
fileName = fileFileNameStr.split('.')[0]
classNumStr = fileName.split('_')[0]
hwLabels.append(classNumStr)
trainingFileName = trainingDir+'\\'+fileFileNameStr
trainingMat[i,:] = image2Vector(trainingFileName)
testFileList = listdir(testDir)
errorCount = 0;
tm = len(testFileList)
for i in range(tm) :
fileFileNameStr = testFileList[i]
fileName = fileFileNameStr.split('.')[0]
classNumStr = fileName.split('_')[0]
testFileName = testDir + '\\' + fileFileNameStr
testMat = image2Vector(testFileName)
#对每个测试集进行测试验证并统计错误数量
classResult = classify0(testMat,trainingMat,hwLabels,3)
if classResult!=classNumStr : errorCount+=1.0
print('Total error is %d , total test is %d' %(errorCount,tm))
print('Error rate is %f' %(errorCount/tm))
按照机器学习的开发步骤我们最终得包装成一个应用给客户,这里我们让客户在一个32*32像素的画图板上手写一个数并以jps的格式保存在固定的目录下,我们需要借助程序将图片解析成参与测试的高维数组,解析代码如下(需要借助PIL模块,不熟悉PIL的读者需要看下<PIL的基本概念>)
代码:
#将普通的图片解析为0/1矩阵
def image2Matrix(fileName):
im = Image.open(fileName)
width,height = im.size
#im_bands = im.getbands()
#转化成模式1
im = im.convert('1')
#获取图片内容
data = im.getdata()
data = matrix(data,dtype='int')/255.0
#图片中白色为1黑色为0,与我们训练结果是相反的,所以需要经过一轮转化
new_data = reshape(data,(height,width))
#构建一个纯1打造的矩阵
oneMatrix = ones(shape(new_data))
new_data = oneMatrix-new_data
#注意这里返回的是矩阵matrix
return new_data
在handWirteTest基础上改造成:
def handWirteFileTest(myNumberFile) :
trainingDir = 'C:\\2017\\提高\\机器学习\\训练样本\\digits\\trainingDigits'
hwLabels = []
trainingFileList = listdir(trainingDir)
m = len(trainingFileList)
trainingMat = zeros((m, 1024))
for i in range(m):
fileFileNameStr = trainingFileList[i]
fileName = fileFileNameStr.split('.')[0]
classNumStr = fileName.split('_')[0]
hwLabels.append(classNumStr)
trainingFileName = trainingDir + '\\' + fileFileNameStr
trainingMat[i, :] = image2Vector(trainingFileName)
#得到32*32的矩阵
myMatrix = file2Matrix.image2Matrix(myNumberFile)
#转化为array参与验证,需要将32*32转化成1*1024的矩阵才可以投入测试
myTestMatrix = asarray(reshape(myMatrix,(1,1024)))
classResult = classify0(myTestMatrix, trainingMat, hwLabels, 3)
print('Your number is %s' %classResult )
k-近邻算法总结:
优点:精度高,对异常值不敏感缺点:空间和时间复杂度都很高适用范围:分类其实K-近邻不适合做图像的处理,因为有个致命的缺点:我们是将代分类内容以纵列的形式去做处理的,不支持空间位移。更优秀的处理模式是深度学习里的深度卷积网络。














 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









