







朴素贝叶斯与前一篇ID3决策树最大的不同之处是前者是给出最大可能性结果的猜想和概率,后者是“武断”的给定唯一分类结果。
我们称之为“朴素”,是因为整个形式化过程只做原始、简单的假设。
贝叶斯决策理论的核心思想,即选择具有高概率的决策。
我们先加深下贝叶斯公式的了解,贝叶斯是基于概率的机器学习的基石。
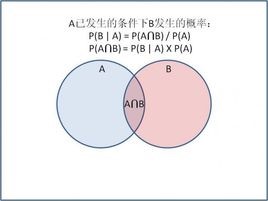
事件A在事件B(发生)的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯法则就是这种关系的陈述
P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)。
引用《机器学习实践》书中的例子来验证下这个公式。
我们有7个球,4黑3灰,很容易得出取出黑色球的概率P(灰)是3/7

现在将7个球拆分到A、B两个盒子里,A盒子4个球B盒子3个球
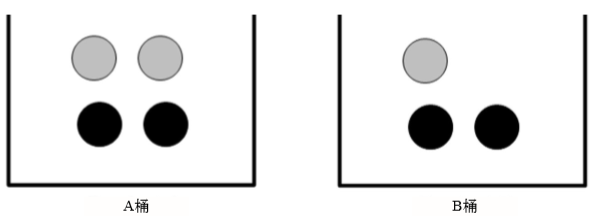
我还是可以算得出P(灰)=P(灰|A)*P(A)+P(灰|B)*P(B)=(2/4)*(4/7)+(1/3)*(3/7)=2/7+1/7=3/7
这种正向的概率我们都好计算的出来,但是逆向的概率缺没那么简单了,那么问题来了,如果我从两个桶中取出一个灰球,这个球来自B桶的概率是多少?
这就要靠贝叶斯公式了:
P(灰|B)*P(B) = P(B|灰)*P(灰)
(1/3)*(3/7) =P(B|灰)* (3/7)
P(B|灰) = 1/3
了解了贝叶斯,我们再来看朴素贝叶斯,朴素贝叶斯比起真正的贝叶斯只是多了两个假设条件来降低了复杂度:
假设1,多个特性之间相互独立,特性之间没有关联关系也不会相互影响,这在现实生活中是不可能的,就跟人说话一样,例如’吸烟’和’运动员’这两个词,理论上运动员是很少吸烟的,也就说如果一个人的特性里已经吸烟了那么他对运动员的概率将会建小,但是朴素贝叶斯忽略了特性之间的关系,把吸烟和运动员这两个特性独立开来,互不影响。
假设2,特性之间地位相同,这个更好理解,是否吸烟与是否爱运动这两个特性对最终分类的影响力是相同的,并不存在某个特性的地位高高在上的情况。
如果没有朴素贝叶斯,情况是怎样的呢?如果有N个特性,每个特性都要考虑对其它特性概率的影响,需要维护(N-1)的2次方的概率关系,这N个特性权重又不一样,又增加了N个权重,想想就要脑裂了。。。所以朴素贝叶斯不是最贴近真相的算法,但是在算法和结果见取了平衡,被大家广泛认可。
下面我们根据简单的训练集开始演示本期的算法,取自《机器学习实战》,演示通过算法来判断某篇文章是否是侮辱性的。
模拟简单的训练集:
#提供训练集
def loadDataSet() :
postingList = [['my','dog','has','flea','problems','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','likes','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid']]
#1代表侮辱言论,0代表正常言论
classList = [0,1,0,1,0,1]
return postingList,classList取训练集中出现过的所有单词:
#该函数作用是将训练集特性做去重并返回一维集合
def createVocabList(dataSet) :
#生成一个空set
vocabSet = set([])
for document in dataSet :
#请并集,也就是去重
vocabSet = vocabSet | set(document)
return list(vocabSet)
单词本身是不具备运算能力的,我们通过建模将单次数据化,这里称之向量化:
#词集模式
#对输入的inputSet做处理,转化成词向量
def setOfWords2Vec(vocabList, inputSet) :
#构建一个以0为元素的与vocabList长度一样的一维数组
returnVec = [0]*len(vocabList)
for word in inputSet :
if word in vocabList :
#将该单次对应的位置修改成1
returnVec[vocabList.index(word)] = 1
#在returnVec中在inputSet出现过的单次为1,未出现过的为0
return returnVec
这个时候我们需要套用贝叶斯公式,找到各个概率之间的关系。
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1]这样的一个词向量我们用W来标识,最终的结果是侮辱性的还是非侮辱性的结论我们用Ci来标识,贝叶斯公式变成了:
P(Ci|W)*P(W) = P(W|Ci)*P(Ci)
假设i=1,代表侮辱性的,贝叶斯翻译成中文就是:(该词向量出现的概率乘以其概率下属于侮辱性结论的概率)等于(侮辱性结论的概率乘以其概率下是因为W这个词向量造成的概率)
我们要做的就是对i=0和i=1两种情况进行计算,算出P(Ci|W)的概率,哪个概率大哪个是W的结果。
P(Ci|W) = P(W|Ci)*P(Ci)/ P(W)
P(Ci)最好计算,根据我们现在的数据共6句话0和1各3条,所以P(C0)=P(C1)=50%
P(W)我们不用去算,因为对于该词向量来讲i=0和i=1对P(W)没有影响
P(W|Ci)最难处理,这里就用到朴素贝叶斯了,假设词向量中每个词特性概率是独立平等的,那么P(W|Ci)= P(w0|Ci)* P(w1|Ci)* P(w2|Ci)* P(w3|Ci)….. P(wn|Ci)。这里是最难理解的地方,W是词向量,是一组特性组成的向量,在代码中对应的是[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1,0, 1, 1, 1, 0, 0, 0, 0, 0, 1],而小w是其中的每个特性,每个向量,w0=1,w1=0,w2=0,…..,wn=1.搞明白大W和小W的关系,就能搞明白这里朴素贝叶斯是如何转化的了。
如果以上文字没解释清楚,希望转化成代码能对理解有所帮助,求几个概率的算法如下:
#利用朴素贝叶斯来计算参与运算的各概率
def trainNB0(trainMatrix, trainCategory) :
#共多少文档
numTrainDoc = len(trainMatrix)
#共多少单词
numTrainWord = len(trainMatrix[0])
#结果为1的概率,对应贝叶斯中的P(C1)
pAbusive = sum(trainCategory)/numTrainDoc
#初始化两个词向量
p0Num = zeros(numTrainWord)
p1Num = zeros(numTrainWord)
#初始化两个P(Ci\W)
p0Denom = 0.0
p1Denom = 0.0
for i in range(numTrainDoc) :
if trainCategory[i] ==1 :
p1Num += trainMatrix[i]
p1Denom +=sum(trainMatrix[i])
else :
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom
p0Vect = p0Num/p0Denom
#p0Vect是P(wi\C0) p1Vect是P(wi\C1) pAbusive是P(C1)
return p0Vect,p1Vect,pAbusive打印下以上代码的产出,通过输出结果加深下理解:
postingList,classList = loadDataSet()
vocabList = createVocabList(postingList)
print(vocabList)
trainMat = []
for subList in postingList :
trainMat.append(setOfWords2Vec(vocabList,subList))
p0Vect,p1Vect,pAbusive = trainNB0(trainMat,classList)
print(p0Vect)
print(p1Vect)
['likes', 'not', 'my', 'how', 'maybe', 'is', 'park', 'take', 'stop', 'worthless', 'I', 'dog', 'help', 'flea', 'so', 'to', 'dalmation', 'love', 'buying', 'problems', 'cute', 'ate', 'please', 'steak', 'quit', 'mr', 'posting', 'food', 'stupid', 'has', 'garbage', 'him']
[ 0. 0. 0.05263158 0.15789474 0. 0.05263158
0. 0. 0. 0.10526316 0. 0.05263158
0. 0. 0. 0.05263158 0.05263158 0.
0.10526316 0. 0. 0.05263158 0. 0.05263158
0.05263158 0.05263158 0. 0.05263158 0. 0.
0.05263158 0.05263158]
[ 0.04166667 0.04166667 0. 0. 0.04166667 0.
0.04166667 0.04166667 0.125 0.04166667 0.04166667 0.
0.04166667 0.04166667 0.04166667 0. 0.04166667 0.04166667
0. 0.04166667 0.04166667 0. 0.04166667 0.
0.04166667 0. 0.04166667 0. 0.04166667 0.04166667
0. 0.08333333]
假如根据前面我们朴素贝叶斯推导的那样
P(W|Ci)= P(w0|Ci)* P(w1|Ci)* P(w2|Ci)* P(w3|Ci)…..P(wn|Ci)
这么多小数乘起来由于精准度的问题最终都趋于0了,而且只要其中一个概率为0,结果就是0,所以要对算法做下修改才能把理论真正用于实践。
1不允许有0的存在,所以将所有词的出现数初始化为1,并将分母初始化为2
2解决精度问题,对乘积取自然对数,f(x)与ln(f(x))它们在相同区域内同时增加或者减少,并且在相同点上取到极值,虽然最终结果的数值与概率不同,但是做为概率大小的判断是等效的。
将P(W|Ci)= P(w0|Ci)* P(w1|Ci)* P(w2|Ci)* P(w3|Ci)….. P(wn|Ci)利用ln(a*b) =ln(a)+ln(b)可以改成log P(w0|Ci)+ log P(w1|Ci)+ log P(w2|Ci)+…+ log P(wn|Ci)
def trainNB(trainMatrix, trainCategory) :
numTrainDoc = len(trainMatrix)
numTrainWord = len(trainMatrix[0])
pAbusive = sum(trainCategory)/numTrainDoc
#初始化两个词向量
p0Num = ones(numTrainWord)
p1Num = ones(numTrainWord)
#初始化两个P(Ci\W)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDoc) :
if trainCategory[i] ==1 :
p1Num += trainMatrix[i]
p1Denom +=sum(trainMatrix[i])
else :
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom)
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify, p0Vect,p1Vect,pAbusive) :
p1 = sum(vec2Classify*p1Vect) + log(pAbusive)
p0 = sum(vec2Classify*p0Vect) + log(1-pAbusive)
if p1>p0 :
return 1
else :
return 0到目前为止,我们使用的是“词集模式”,向量通过0和1标识某个词是否出现,但是忽略了出现的次数,如果想计算的更精准,需要采用“词袋模式”,也就是给每个单次装到一个袋子里,重复装入后对应的口袋会越来越重。
词集模式的原因从代码中很容易分析出来,是setOfWords2Vec()函数引起的,所以要改造成词袋模式需要从该函数动手:
#词袋模式
#对输入的inputSet做处理,转化成词向量
def bagOfWords2Vec(vocabList, inputSet) :
#构建一个以0为元素的与vocabList长度一样的一维数组
returnVec = [0]*len(vocabList)
for word in inputSet :
if word in vocabList :
#将该单次对应的位置增加1
returnVec[vocabList.index(word)] += 1
return returnVec
def trainNB(trainMatrix, trainCategory) :
numTrainDoc = len(trainMatrix)
numTrainWord = len(trainMatrix[0])
pAbusive = sum(trainCategory)/numTrainDoc
#初始化两个词向量
p0Num = ones(numTrainWord)
p1Num = ones(numTrainWord)
#初始化两个P(Ci\W)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDoc) :
if trainCategory[i] ==1 :
p1Num += trainMatrix[i]
p1Denom +=sum(trainMatrix[i])
else :
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom)
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive测试代码:
def coreTest() :
postingList, classList = loadDataSet()
vocabList = createVocabList(postingList)
print(vocabList)
trainMat = []
for subList in postingList:
trainMat.append(bagOfWords2Vec(vocabList, subList))
print(trainMat)
p0Vect, p1Vect, pAbusive = trainNB(trainMat, classList)
testEntry=['love','my','dalmation']
thisDoc = bagOfWords2Vec(vocabList,testEntry)
print(classifyNB(thisDoc,p0Vect, p1Vect, pAbusive))
testEntry = ['stupid', 'garbage',]
thisDoc = bagOfWords2Vec(vocabList, testEntry)
print(classifyNB(thisDoc, p0Vect, p1Vect, pAbusive))
目前为止朴素贝叶斯算法核心部分基本完毕,我们再回头看一下机器学习开发步骤,补齐其它步骤
收集数据,需要提供一个函数用于解析文本成单次集,代码:
#大文本转化为单词集
def textParse(strings) :
import re
list = re.split(r'\W*',strings)
return [tok.lower() for tok in list if len(tok)>2]准备测试的训练集,放在了git上https://github.com/yejingtao/forblog/tree/master/MachineLearning/trainingSet/email:
def mainTest() :
#docList是个高维数组,保存的是文件
docList=[]
#classList保存的是结果集
classList=[]
#fullText是一维度数组,保存的是所有单次
fullText=[]
for i in range(1,26) :
wordList = textParse(open('C:\\2017\\提高\\机器学习\\'
'训练样本\\email\\spam\\%d.txt' %i).read())
#append是将新元素做为新的一个属性
docList.append(wordList)
#extend是在本元素后面拼接
fullText.extend(wordList)
classList.append(1)
wordList = textParse(open('C:\\2017\\提高\\机器学习\\'
'训练样本\\email\\ham\\%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
#vecabList得到的是所有文档去重后的一维数组
vocabList = createVocabList(docList)
#构建0-49的list
#从3.X版本后list()强转必须有,否则会报错
trainingSet = list(range(50))
testSet = []
#下面的for循环是从50个数据样本中随机选10个做为测试集,剩下的40个为训练集
#这里保存的是index,不是内容
for i in range(10) :
readIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[readIndex])
trainingSet
del(trainingSet[readIndex])
trainingMat = []
trainingClass = []
for docIndex in trainingSet :
trainingMat.append(bagOfWords2Vec(vocabList,docList[docIndex]))
trainingClass.append(classList[docIndex])
#trainingMat里现在是参与训练的40组词向量
#trainingClass里是参与训练的40个结果集
p0Vect, p1Vect, pAbusive = trainNB(array(trainingMat),array(trainingClass))
errorCount = 0
for index in testSet :
#wordVector是每个参与测试的词向量
wordVector = bagOfWords2Vec(vocabList,docList[index])
if classifyNB(array(wordVector),p0Vect, p1Vect, pAbusive) != classList[index] :
errorCount +=1
print('error rate is %f' %float(errorCount/len(testSet)))朴素贝叶斯
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。














 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









