







什么是回归?
假设现在有一些数据点,我们用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归。
涉及到回归问题,我们借助Sigmoid函数来处理,Sigmoid函数:
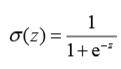
x=0时,函数值是0.5,x越大函数值越趋近于1,x越小函数值越趋近于0。
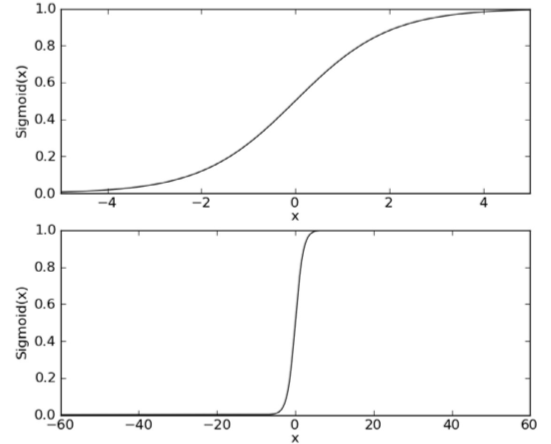
如果x的刻度足够大Sigmoid函数也可以堪称一个单位阶跃函数。之所以采用Sigmoid来解决回归问题,是因为在一定条件下Sigmoid函数呈现出“线性”的特性,“线性”的体现就是回归系数。
先来解释Sigmoid的线性,Sigmoid函数的输入记为z,假设有n个特性,也就是说有n个向量,那么Sigmoid函数中入参z可以标识成:
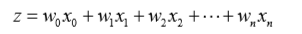
小写的w是各个向量上的回归系数,小写的x是各个向量上的入参。
如果采用向量的写法,上述公式可以写成z = WX,大写的W是多向量的回归系数,大写的X是多向量的一套入参。
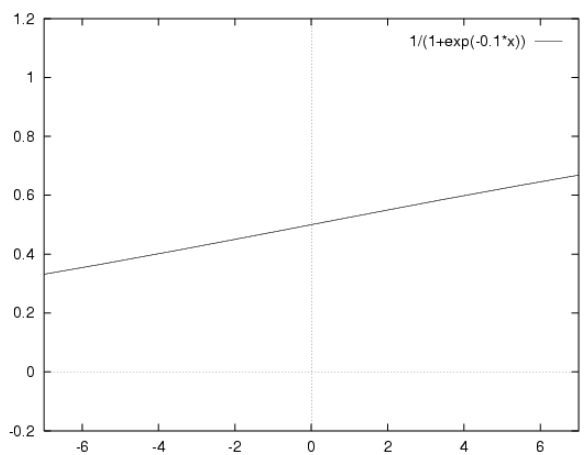
从公式中我们可以看出只要W是非零值,Z最终都会趋于无穷大和无穷小,所以Sigmoid函数值终将趋于0和1;但是如果W足够小,那么X在一定范围内对Z的影响将会放缓,相当于将上面第一张图向X轴两边拉长了,那么在一定范围内就会趋向与一条直线,也就是说会变成线性的。例如W=0.1时,x在(-7,7)之间的图形是这样的:
理解了线性之后后面的问题就变得简单了,我们对多向量的数据集进行0、1分组时就演化成了了求Z的过程,也就是求多向量的回归系数W的过程了。
在求得W的过程中采用的是梯度上升算法,梯度上升法基于的思想是:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为∇,则函数f(x,y)的梯度表示为:
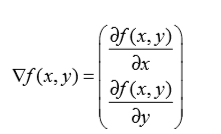
梯度上升算法到达每个点后都会重新估计移动的方向。从P0开始,计算完该点的梯度,函数就根据梯度移动到下一点P1。在P1点,梯度再次被重新计算,并沿新的梯度方向移动到P2。如此循环迭代,直到满足停止条件。迭代的过程中,梯度算子总是保证我们能选取到最佳的移动方向
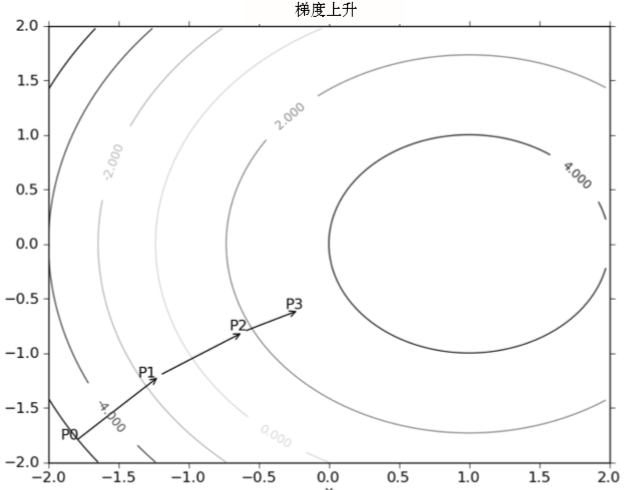
梯度上升算法,每上升一步,梯度算子总是指向函数值增长最快的方向,这里用的是方向而不是移动量的大小,是因为需要引入一个“步长”α的概念,步长越长,每次向山顶移动的越快,但是精准度越低,α的平衡是个学问。
梯度上升就是个不断递归的过程,每移动一步,更新当前的结果,重新计算剩下的最优方向,用公式标识是:
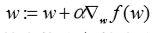
PS:梯度上升法如爬山一样,是求山顶最大值的方法,与梯度上升法对应的是梯度下降法,是求最小值的方法,将公式中的+号改成-号既可。
有了上面的理论基础,我们开始用代码和样例来演练下,训练文件在git上https://github.com/yejingtao/forblog/blob/master/MachineLearning/trainingSet/testSet.txt,格式如下:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
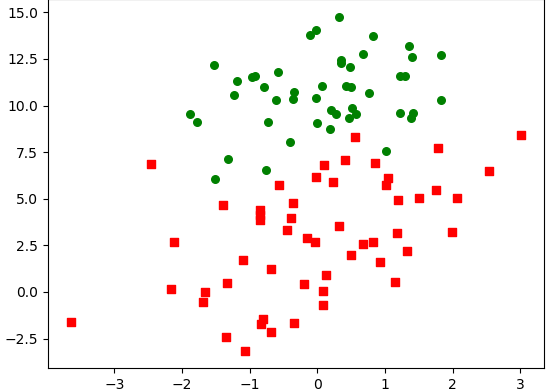
0.667394 12.741452 0其中前两项为特性,最后一列为结果。
要做的事情简单来说就是绘制一条“直线”,将图中这些训练集划分为两部分,处理这种0、1分类的场景我们采用前面介绍的Sigmoid函数,而求“直线”的过程就是求W的过程。
准备演示的训练集和结果集:
#加载训练集和结果集
def loadDataSet() :
dataMat = []
labelMat = []
fr = open('C:\\2017\\提高\\机器学习\\训练样本\\testSet.txt')
for line in fr.readlines():
lineArray = line.strip().split()
#这里给第一向量设置了1.0值,因为从分布图中看得出不是过原点的直线,所以要最终的W中要有x位的偏移量
dataMat.append([1.0,float(lineArray[0]), float(lineArray[1])])
labelMat.append(int(lineArray[2]))
return dataMat,labelMat
#sigmoid函数
def sigmoid(inX) :
return 1.0/(1.0+exp(-inX))
#最终返回的weights可以理解为梯度的塔顶
def gradAscent(dataMatIn, classLabels) :
dataMatrix = mat(dataMatIn)
#transpose将行数组转成列向量
labelMatrix = mat(classLabels).transpose()
m,n = shape(dataMatrix)
# 返回的是步长alpha,训练次数maxCycle的回归系数
alpha = 0.001
maxCycle = 500
weights = ones((n,1))
for i in range(maxCycle) :
#h是一个列向量
h = sigmoid(dataMatrix * weights)
#列向量相减,得到的还是个列向量error
error = labelMatrix - h
#dataMatrix.transpose()*error是矩阵相乘,事实上该运算包含了300次的乘积
#梯度上升,对weights做修正
weights = weights+alpha * dataMatrix.transpose()*error
#返回也是个列向量
return weights利用matplotlib模块用图像来验证回归系数:
def plotBestFit(wei) :
import matplotlib.pyplot as plt
weights = wei.getA()
dataMat, labelMat = loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xc1=[]
yc1=[]
xc2=[]
yc2=[]
for i in range(n) :
if int(labelMat[i])==1 :
xc1.append(dataArr[i,1])
yc1.append(dataArr[i,2])
else :
xc2.append(dataArr[i, 1])
yc2.append(dataArr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xc1,yc1,s=30,c='red',marker='s')
ax.scatter(xc2, yc2, s=30, c='green')
x = arange(-3.0,3.0,0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x,y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()测试代码:
dataMat,labelMat = loadDataSet()
weights = gradAscent(dataMat,labelMat)
print(weights)
plotBestFit(weights)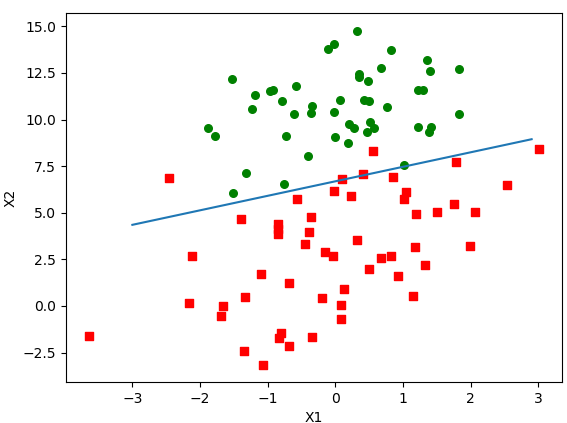
这里有一行代码不容易理解需要解释下:y = (-weights[0]-weights[1]*x)/weights[2],来自:
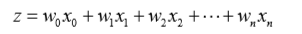
公式中x0=常量1,x1=这里的x,x2=这里的y,同时z取0,是因为在z=0时Sigmoid函数值为1/2正好是0与1的临界点。
所以从0= weights[0]*1+ weights[1]*x + weights[2]*y推导而来。
从图像结果来看回归系数比较理想,但是缺点也很明显,尽管例子简单且数据集很小,这个方法却需要大量的计算量。
假设我们的数据集是几万几亿 的话,该训练算法计算量将不可控制
再介绍下随机梯度上升法:
def stocGradAscent0 (dataMatrix, classLabels) : m,n = shape(dataMatrix) alpha = 0.01 weights = ones(n) for i in range(m) : h = sigmoid(sum(dataMatrix[i] * weights)) error = classLabels[i] - h weights = weights + alpha*error*dataMatrix[i] return weights
测试结果是:[ 1.01702007 0.85914348 -0.36579921]
一个判断优化算法优劣的可靠方法是看它是否收敛,也就是说参数是否达到了稳定值,是否还会不断地变化。可以看到目前结果并没有收敛,假如继续不断对随机梯度进行递归的话,最终将会收敛,这里请看下机器学习实践中给出的测试结果:
X0和X1要迭代很久才能收敛,X2很快就可以收敛,X1和X2存在一定的波动,波动来源于趋于临界点的数据,在n次修订后在n+1次又被修订回去,重复数据的来回修订引起了波动。
基于以上的分析我们对随机梯度上升法进行加强,第一如何最快收敛,第二如何减少波动。
1调整步长尽快收敛,开始时步长设置较大,减少前期计算上的浪费,越是趋于收敛时步长越小
2随机数据减少波动,前面已经分析过既然重复数据的来回修订引起了波动,那么我们就采用随机数据来训练算法。
加强后的代码是:
def stocGradAscent1 (dataMatrix, classLabels, numIter=150) : m,n = shape(dataMatrix) weights = ones(n) for j in range(numIter) : dataIndex = list(range(m)) for i in range(m) : #动态的步长,i,j越大越趋于稳定,步长越小 alpha = 4/(1.0+i+j) + 0.01 #随机训练入参解决波动问题 randIndex = int(random.uniform(0,len(dataIndex))) h = sigmoid(sum(dataMatrix[randIndex]*weights)) error = classLabels[randIndex] - h weights = weights + alpha*error*dataMatrix[randIndex] del(dataIndex[randIndex]) return weights
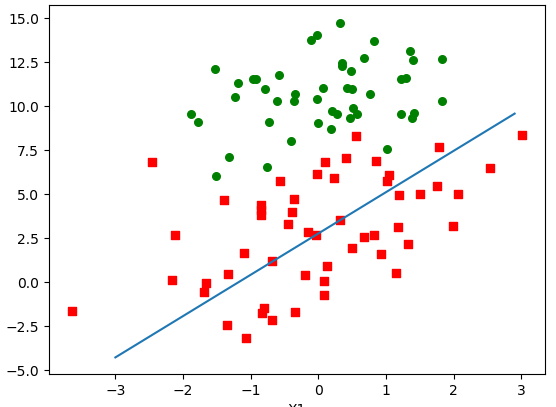
测试结果:
[ 14.56523388 0.87521806 -1.92639734]
虽然回归系数不如基本梯度上升法优秀,但是该算法是考虑到了计算量和回归性的平衡。
Logistic回归
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
适用数据类型:数值型和标称型数据。
PS:本文中的代码和训练数据来自机器学习实践















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









