







1.变量就像一个盒子,里面装着变量的值。在python中,变量更像一个指针指向变量盒子。对于数字类型来说,它是不可更改类型,我们无法改变盒子的内容,但可以将指针指向一个新盒子。每次将另外的数字赋值给变量的时候,实际上是创建了一个新的对象并把它赋值给变量(不仅仅是数字类型,对于所有不可变类型都是如此)。
2.python中长整型与C语言中的不同,python的长整型能表达的数值仅仅与我们所用的机器支持的(虚拟)内存大小有关。
3.位操作符(只适用于整型)
取反~
按位与&
或|
异或^
左移<<
右移>>
4.函数int()、float()、long()和complex()用来将其他数值转换为相应的数值类型。
例如:

5.功能函数abs()、coecre()、divmod()、pow()和round()。
例如:
(1)abs()返回给定参数的绝对值。

(2)函数coerce()是一个数据类型转换函数,该函数为程序员提供了不依赖python解释器,而是自定义两个数值类型转换的方法。
函数coerce()仅返回一个包含类型转换完毕的两个数值元素的元组。

(3)divmod()内建函数吧除法和取余运算结合起来,返回一个包含商和余数的元组。

(4)函数pow()和双星号**操作符都可以进行指数运算。

(5)內建函数round()用于对浮点型进行四舍五入。

6.仅用于整型的函数
(1)hex(num)函数,将数字转换成十六进制数并以字符串形式返回。
(2)oct(num)函数,将数字转换成八进制数并以字符串形式返回。
(3)chr(num)函数,将ASCII值的数字转换成ASCII字符,范围只能是0<=num<=255.
(4)ord(chr)函数,将ASCII或Unicode字符(长度为1的字符串),返回相应的ASCII或Unicode值。
(5)unichr(num)函数,接受ASCII或Unicode字符(长度为1的字符串),返回相应的ASCII或Unicode字符。所接受的码值范围依赖于你的python是构建于UCS-2还是UCS-4。


7.布尔“数”:尽管布尔值看上去是“True”和“false”,但是事实上是整型的子类,对应与整型的1和0。
(1)两个永不改变的值“True”或“false”。
(2)布尔型是整型的子类,但是不能再被继承而生成它的子类。
(3)没有__nonzero__()方法的对象的默认值是True。
(4)对于值为0的任何数字或空集(空列表、空元组和空字典)在python中的布尔值都是false。
(5)在数组运算中,Boolean值的true和false分别对应于0和1.
(6)以前返回整型的大部分标准库函数和內建函数现在返回布尔型。
8.切片操作
S[::-1]可以看做“翻转操作”
S[::2]隔一个取一个操作

特殊地:
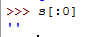
9.若想用一个变量作为索引从从第一个开始遍历到最后一个元素,使用None作为索引值:

10.类型转换內建函数
(1)list(iter)函数,把可迭代对象转换为列表。
(2)str(obj)函数,把obj对象转换为字符串(对象的字符串表示法)。
(3)unicode(obj)函数,把对象转换成Unicode字符串(使用默认编码)。
(4)basestring()函数,抽象工厂函数,其作用仅仅是为str和unicode函数提供父类,所以不能被实例化,也不能被调用。
(5)truple(iter)函数,把一个可迭代对象转换成一个元组对象。
11.序列类型可用內建函数
(1)enumerate(iter)函数,接受一个可迭代对象作为参数,返回一个enumerate对象(同时也是一个迭代器),该对象生成由iter每个元素的index值和item值组成的元组。
(2)len(seq)函数,返回seq的长度。
(3)max(iter,key=None)or max(arg0,arg1…, key=None),返回iter或(arg0,arg1,...)中的最大值,如果指定了key,这个key必须是一个可以传给sort()方法的,用于比较的回调函数。
(4)min(iter, key=None)or min(arg0, arg1…key=None,返回iter里面的最小值或者返回(arg0,arg1,...)里面的最小值; 如果指定了key,这个key必须是一个可以传给sort()方法的,用于比较的回调函数。
(5)reversed(seq)函数,接受一个序列作为参数,返回一个以逆序访问的迭代器。
(6)sorted(iter, func=None, key=None,reverse=False)函数,接受一个可迭代对象作为参数,返回一个有序的列表;可选参数func、key和reverse的含义跟list.sort()内建函数的参数含义一样。
(7)sum(seq, init=0)函数,返回seq和可选参数init的总和,其效果等同于reduce(operator.add,seq,init)。
(8)zip([it0, it1,... itN])函数,返回一个列表,其第一个元素是it0、it1...这些元素的第一个元素组成的一个元组,第二个...依此类推。
12.例子:

13.
>>> str1 = 'abc'
>>> str2 = 'lmn'
>>> str3 = 'xyz'
>>> str1 < str2
True
>>> str2 != str3
True
>>> str1 < str3 and str2 == 'xyz'
False
在做比较操作的时候,字符串是按照ASCII值的大小来比较的。
14.

15.连接符(+)
>>> 'Spanish' + 'Inquisition'
'SpanishInquisition'
>>> 'Spanish' + ' ' + 'Inquisition'
'Spanish Inquisition'
>>> s = 'Spanish' + ' ' + 'Inquisition' + ' Made Easy'
>>> s
'Spanish Inquisition Made Easy'
>>> import string
>>> string.upper(s[:3] + s[20]) # archaic (see below)
'SPAM'
16.join()方法
>>> '%s %s' % ('Spanish', 'Inquisition')
'Spanish Inquisition'
>>> s = ' '.join(('Spanish', 'Inquisition', 'Made Easy'))
>>> s
'Spanish Inquisition Made Easy'
>>> # no need to import string to use string.upper():
>>> ('%s%s' % (s[:3], s[20])).upper()
'SPAM'
17.字符串格式化符号
%c 转换成字符(ASCII码值,或者长度为一的字符串)
%r 优先用repr()函数进行字符串转换
%s 优先用str()函数进行字符串转换
%d / %i 转成有符号十进制数
%u 转成无符号十进制数
%o 转成无符号八进制数
%x/%X 转成无符号十六进制数(x/X代表转换后的十六进制字符的大小写)
%e/%E 转成科学计数法(e/E控制输出e/E)
%f/%F 转成浮点型(小数部分自然截断)
%g/%G %e和%f/%E和%F的简写
%% 输出%
18.十六进制输出


19.浮点型和科学计数法形式输出
%g或%G是%e和%f,%E和%F的简写。
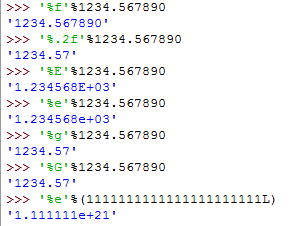
20整型和字符串输出
(%02d其中0表示显示的数字前面填充‘0’而不是默认的空格)

21.格式化操作符辅助指令
* 定义宽度或者小数点精度
- 用做左对齐
+ 在正数前面显示加号(+)
<sp> 在正数前面显示空格
# 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X')
0 显示的数字前面填充‘0’而不是默认的空格
% '%%'输出一个单一的'%'
(var) 映射变量(字典参数)
m.n m是显示的最小总宽度,n是小数点后的位数(如果可用的话)
22.原始字符串操作符(r/R)
'r'可以是小写也可以是大写,唯一的要求是必须紧靠在第一个引号前。

23.Unicode字符串操作符(u/U)
24.內建函数
(1)cmp()函数:内建的cmp()函数也根据字符串的ASCII码值进行比较。

(2)len()函数:返回字符串的字符数。

(3)max()和min()函数:虽然max()和min()函数对其他的序列类型可能更有用,但对于string类型它们能很好地运行,返回最大或者最小的字符(按照ASCII码值排列)。

(4)enumerate()函数

(5)chr()函数用一个范围在range(256)内的(就是0~255)整数作参数,返回一个对应的字符。unichr()跟它一样,只不过返回的是Unicode字符。
ord()函数是chr()函数(对于8位的ASCII字符串)或unichr()函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的ASCII数值,或者Unicode数值,如果所给的Unicode字符超出了你的Python定义范围,则会引发一个TypeError的异常。
25.字符串內建函数
| 方 法 | 描 述 |
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度width的新字符串 |
| string.count(str, beg=0,end=len(string)) | 返回str在string里面出现的次数,如果beg或者end指定则返回指定范围内str出现的次数 |
| string.decode(encoding='UTF-8' errors='strict') | 以dncoding指定的编码格式解码string,如果出错默认报一个ValueError的异常,除非errors指定的是'ignore'或者'replace' |
| string.encode(encoding='UTF-8', errors='strict') | 以encoding指定的编码格式编码string,如果出错默认报一个 ValueError的异常,除非errors指定的是'ignore'或者'replace' |
| string.endswith (obj, beg=0,end =len(string)) | 检查字符串是否以obj结束,如果beg或者end指定则检查指定的范围内是否以obj结束,如果是,返回True,否则返回False。 |
| string.expandtabs (tabsize=8) | 把字符串string中的tab符号转为空格,默认的空格数tabsize是8 |
| string.find(str, beg=0,end=len(string)) | 检测str是否包含在string中,如果beg和end指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.index(str, beg=0,end=len(string)) | 跟find()方法一样,只不过如果str不在string中会报一个异常 |
| string.isalnum() | 如果string至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False |
| string.isalpha() | 如果string至少有一个字符并且所有字符都是字母则返回True,否则返回False |
| string.isdecimal() | 如果string只包含十进制数字则返回True、否则返回False |
| string.isdigit() | 如果string只包含数字则返回True否则返回False |
| string.islower() | 如果string中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回True,否则返回False |
| string.isnumeric() | 如果string中只包含数字字符,则返回True,否则返回False |
| string.isspace() | 如果string中只包含空格,则返回True,否则返回False |
| string.istitle() | 如果string是标题化的(见title())则返回True,否则返回False |
| string.isupper() | 如果string中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回True,否则返回False |
| string.join(seq) | 以string作为分隔符,将seq中所有的元素(字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度width的新字符串 |
| string.lower() | 转换string中所有大写字符为小写 |
| string.lstrip() | 截掉string左边的空格 |
| string.partition(str) | 有点像find()和split()的结合体,从str出现的第一个位置起,把字符串string分成一个3元组(string_pre_str,str,string_post_str),如果string中不包含str则string_pre_str == string |
| string.replace(str1, str2, num=string count(str1)) | 把string中的str1替换成str2,如果num指定,则替换不超过num次 |
| string.rfind(str, beg=0, end=len(string)) | 类似于find()函数,不过是从右边开始查找 |
| string.rindex( str, beg=0, end=len(string)) | 类似于index(),不过是从右边开始 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度width的新字符串 |
| 方 法 | 描 述 |
| string.rpartition(str) | 类似于partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除string字符串末尾的空格 |
| string.split(str="", num =string.count(str)) | 以str为分隔符切片string,如果num有指定值,则仅分隔num 个子字符串 |
| string.splitlines(num= string.count('\n')) | 按照行分隔,返回一个包含各行作为元素的列表,如果num指 定则仅切片num行 |
| string.startswith(obj, beg =0,end=len(string)) | 检查字符串是否是以obj开头,是则返回True,否则返回False 如果beg和end指定值,则在指定范围内检查 |
| string.strip([obj]) | 在string上执行lstrip()和rstrip() |
| string.swapcase() | 翻转string中的大小写 |
| string.title() | 返回“标题化”的string,就是说所有单词都是以大写开始,其余字母均为小写(见istitle()) |
| string.translate(str, del="") | 根据str给出的表(包含256个字符)转换string的字符,要过滤掉的字符放到del参数中 |
| string.upper() | 转换string中的小写字母为大写 |
| string.zfill(width) | 返回长度为width的字符串,原字符串string右对齐,前面填充0 |
26.例子


27.三引号
Python的三引号就是为了解决这个问题的,它允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
28.id()函数返回一个对象的身份,这个概念有点类似于“内存地址”。

注意修改前后的身份是不同的。另一个测试是针对字符串的一个字符或者一个子串所做的修改。我们现在将展示对字符串的一个字符或者一片字符的改动都是不被允许的。

两个操作都抛出了异常。为了实现要求,我们需要用现有字符串的子串来构建一个新串,然后把这个新串赋给原来的变量。

30.失误#1:在源码中到处使用string模块或者str()和chr()函数。
结果#1:通过全局的查找替换把str()和chr()替换成unicode()和unichr(),但是这样一来很可能就不能再用pickle模块,要用的话只能把所有要pickle处理的数据存成二进制形式,这样一来就必须修改数据库的结构,而修改数据库结构就意味着全部推倒重来。
失误#2:不能确定所有的辅助系统都完全地支持Unicode。
结果#2:不得不去为那些系统打补丁,而其中有些系统可能你根本就没有源码。修复对Unicode支持的bug可能会降低代码的可靠性,而且非常有可能引入新的bug。
总结:使应用程序完全支持Unicode,兼容其他的语言本身就是一个工程。
31.与字符串类型有关的模块
| 模 块 | 描 述 |
| string | 字符串操作相关函数和工具,比如Template类 |
| re | 正则表达式:强大的字符串模式匹配模块 |
| struct | 字符串和二进制之间的转换 |
| c/StringIO | 字符串缓冲对象,操作方法类似于file对象 |
| base64 | Base 16、32和64数据编解码 |
| codecs | 解码器注册和基类 |
| crypt | 进行单方面加密 |
| difflib | 找出序列间的不同 |
| hashlib | 多种不同安全哈希算法和信息摘要算法的API |
| hma | HMAC信息鉴权算法的Python实现 |
| md5 | RSA的MD5信息摘要鉴权 |
| rotor | 提供多平台的加解密服务 |
| sha | NIAT的安全哈希算法SHA |
| stringprep | 提供用于IP协议的Unicode字符串 |
| textwrap | 文本包装和填充 |
| unicodedata | Unicode数据库 |
32.列表
(1)如何创建列表类型数据并给它赋值
>>> list('foo')
['f', 'o', 'o']

(2)如何访问列表中的值
>>> aList[3][1]
'list'

(3)如何更新列表

(4)如何删除列表中的元素或者列表本身
要删除列表中的元素,如果知道要删除元素的素引可以用del语句,否则可以用remove()方法。

还可以通过pop()方法来删除并从列表中返回一个特定对象。
33.标准类型操作符

34.序列类型操作符
(1)切片[]和[:]

(2)成员关系操作(in,not in)

(3)连接操作符(+)
必须指出,连接操作符并不能实现向列表中添加新元素的操作。在接下来的例子中,我们展示了一个试图用连接操作向列表中添加新元素而报错的例子。
>>> num_list + 'new item'
Traceback (innermost last):
File "<stdin>", line 1, in ?
TypeError: illegal argument type for built-in operation

(4)重复操作符(*)

复合赋值运算

35.列表解析

36.标准类型內建函数
cmp()函数

37.序列类型函数
(1)len()函数

(2)max()和min()函数

(3)sorted()和reversed()函数

应该注意如何把单引号和双引号的使用矛盾和谐掉,同时还要注意字符串排序使用的是字典序,而不是字母序(字母'T'的ASCII码值要比字母'a'的还要靠前)。
(4).enumerate()和zip()函数

(5)sum()函数

(6)list()和truple函数

37.列表类型內建函数
| 列 表 函 数 | 作 用 |
| list.append(obj) | 向列表中添加一个对象obj |
| list.count(obj) | 返回一个对象obj在列表中出现的次数 |
| list.extend(seq) | 把序列seq的内容添加到列表中 |
| list.index(obj, i=0, j=len(list)) | 返回list[k] == obj的k值,并且k的范围在 i<=k<j;否则引发ValueError异常 |
| list.insert(index, obj) | 在索引量为index的位置插入对象obj |
| list.pop(index=−1) | 删除并返回指定位置的对象,默认是最后一个对象 |
| list.remove(obj) | 从列表中删除对象obj |
| list.reverse() | 原地翻转列表 |
| list.sort(func=None, key=None,reverse= False) | 以指定的方式排序列表中的成员,如果func和key参数指定,则按照指定的方式比较各个元素,如果reverse标志被置为True,则列表以反序排列 |
38.例子
(1)

(2)


(3)

(4)


39.用列表构建其他数据结构
(1)堆栈
堆栈是一个后进先出(LIFO)的数据结构,在栈上“push”元素是个常用术语,意思是把一个对象添加到堆栈中。反之,要删除一个元素,你可以把它“pop”出堆栈。
例子:用列表模拟堆栈。
1 #!/usr/bin/env python(2)队列
2
3 stack = []
4
5 def pushit():
6 stack.append(raw_input(' Enter New string: ').strip())
7
8 def popit ():
9 if len (stack)==0:
10 print 'Cannot pop from an empty stack!'
11 else:
12 print 'Removed [', ‘stack.pop()‘, ']'
13
14 def viewstack():
15 print stack # calls str() internally
16
17 CMDs = {'u': pushit, 'o': popit, 'v': viewstack}
18
19 def showmenu():
20 pr="""
21 p(U)sh
22 p(O)p
23 (V)iew
24 (Q)uit
25
26 Enter choice: """
27
28 while True:
29 while True:
30 try:
31 choice = raw_input(pr).strip()[0].lower()
32 except (EOFError,KeyboardInterrupt,IndexError):
33 choice = 'q'
34
35 print '\nYou picked: [%s]' % choice
36 if choice not in 'uovq':
37 print 'Invalid option, try again'
38 else:
39 break
40
41 if choice == 'q':
42 break
43 CMDs[choice]()
44
45 if __name__ == '__main__':
46 showmenu()
队列是一种先进先出(FIFO)的数据类型。新的元素通过“入队”的方式添加进队列的末尾,“出队”就是从队列的头部删除。
例:把列表用作队列。
1 #!/usr/bin/env python40.元组
2
3 queue = []
4
5 def enQ():
6 queue.append(raw_input(' Enter New string: ').strip())
7
8 def deQ():
9 if len(queue)==0:
10 print 'Cannot pop from an empty queue!'
11 else:
12 print 'Removed [', ‘queue.pop(0)‘, ']'
13
14 def viewQ():
15 print queue # calls str() internally
16
17 CMDs = {'e': enQ, 'd': deQ, 'v': viewQ}
18
19 def showmenu():
20 pr="""
21 (E)nqueue
22 (D)equeue
23 (V)iew
24 (Q)uit
25
26 Enter choice: """
27
28 while True:
29 while True:
30 try:
31 choice = raw_input(pr).strip()[0].lower()
32 except (EOFError,KeyboardInterrupt,IndexError):
33 choice = 'q'
34
35 print '\nYou picked: [%s]' % choice
36 if choice not in 'devq':
37 print 'Invalid option, try again'
38 else:
39 break
40
41 if choice == 'q':
42 break
43 CMDs[choice]()
44
45 if __name__ == '__main__':
46 showmenu()
(1)如何创建一个元组并给它赋值
创建一个元组并给他赋值实际上跟创建一个列表并给它赋值完全一样,除了一点,只有一个元素的元组需要在元组分割符里面加一个逗号(,)以防止跟普通的分组操作符混淆。

(2)如何访问元组中的值

(3)如何更新元组

(4)如何移除一个元组的元素
删除一个单独的元组元素是不可能的。当然,把不需要的元素丢弃后,重新组成一个元组是没有问题的。
要显示地删除一整个元组,只要用del语句减少对象引用计数。当这个引用计数达到0的时候,该对象就会被析构。记住,大多数时候,我们不需要显式的用del删除一个对象,一出它的作用域它就会被析构,Python编程里面用到显式删除元组的情况非常之少。
del aTuple
41.元组操作符和内建函数
(1)创建、重复、连接操作

(2)成员关系操作、切片操作

(3)内建函数

(4)操作符
















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









