







第十五次博客作业
1、总结sed和awk的详细用法;
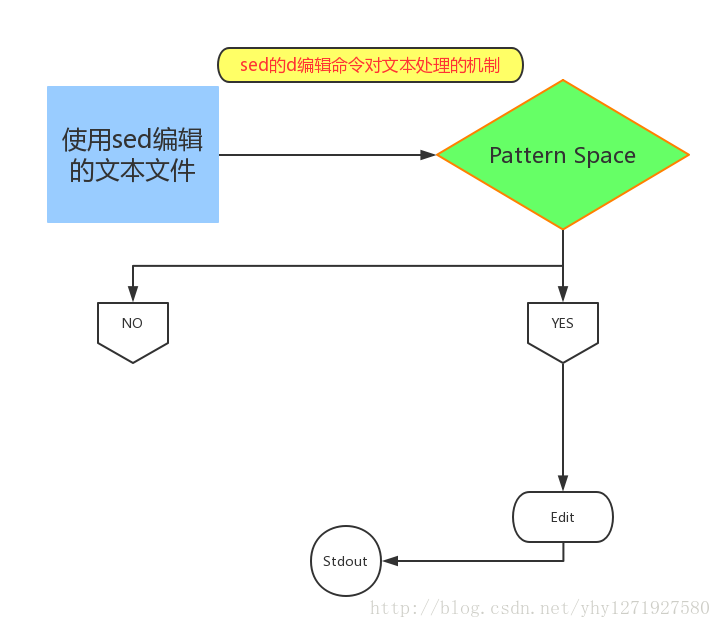
sed工作机制:sed处理的文本文件首先会被读到pattern space中,然后再判断pattern space是否会被匹配到,如果匹配到,就会对匹配到的文本做编辑操作,之后再将被编辑的文本和没有被编辑的文本一同输出到标准输出。如果pattern space没有被匹配到,直接将没有被匹配到的文本输出至默认输出
- sed命令的基本格式为:
sed [OPTION]… Script [input-file],Script:为地址定界和编辑命令的组合,其中选项有
- -n:取消默认输出Script
- -e:使用多编辑点,也就是可以有多个Script
- -f /PATH/TO/SED_SCRIPT_FIEL:指定多个编辑命令的脚本
- -r:使用扩展正则表达式
- -i:直接对原文件进行处理
- 此外对于sed的应用来说,最为主要的就是其Script编辑命令
- sed命令的基本格式为:
- grep,eprep,fgrep:文本过滤器,行过滤
- sed:流编辑器
- awk:文本格式化工具,报告生成器
sed工作机制:sed处理的文本文件首先会被读到pattern space中,然后再判断pattern space是否会被匹配到,如果匹配到,就会对匹配到的文本做编辑操作,之后再将被编辑的文本和没有被编辑的文本一同输出到标准输出。如果pattern space没有被匹配到,直接将没有被匹配到的文本输出至默认输出sed [OPTION]…
Script[input-file]…script :地址定界,编辑命令-n:不输出模式控件中的内容至屏幕,也就是不会将没有匹配到的文本输出到标准输出,只是输出编辑到的文本- -e:可以在sed命令中使用多个script ,多点编辑
- -f:/PATH/TO/SED_SCRIPT_FIEL:每行一个编辑命令的脚本,多个编辑命令组合的脚本
- -r:支持使用扩展的正则表达式
- -i:直接编辑源文件
地址定界
- (1)空地址:对全文进行处理
- (2)
单地址:
- #:指定行
- /pattern/:被此模式匹配到的每一行
- (3)
地址范围
- #,#:起始行号,末行号
- #+#:
- #, /pat1/:从起始行开始,到匹配到的行结束
- /pat1/, /pat2/:第一个模式匹配到的行,到第二个模式匹配到的行
- $:表示最后一行
- (4)步长:~
- 1~2:所有的奇数行:
- 例如:sed -n ‘1~2p’ /etc/fstab:删除奇数行,输出偶数行
- 2~2:所有的偶数行
- 1~2:所有的奇数行:
编辑命令- d:删除
- 例如:sed ‘/^#/d’ /etc/fstab: /^#/表示匹配所有以#号开头的行,d 表示删除,这样标准输出中就是文本中以#开头的行删除,其他的行标准输出,
如果使用sed -n "/^#/d" /etc/fstab:则什么都不输出,因为没有被模式匹配的不输出,编辑的删除了
- 例如:sed ‘/^#/d’ /etc/fstab: /^#/表示匹配所有以#号开头的行,d 表示删除,这样标准输出中就是文本中以#开头的行删除,其他的行标准输出,
- d:删除
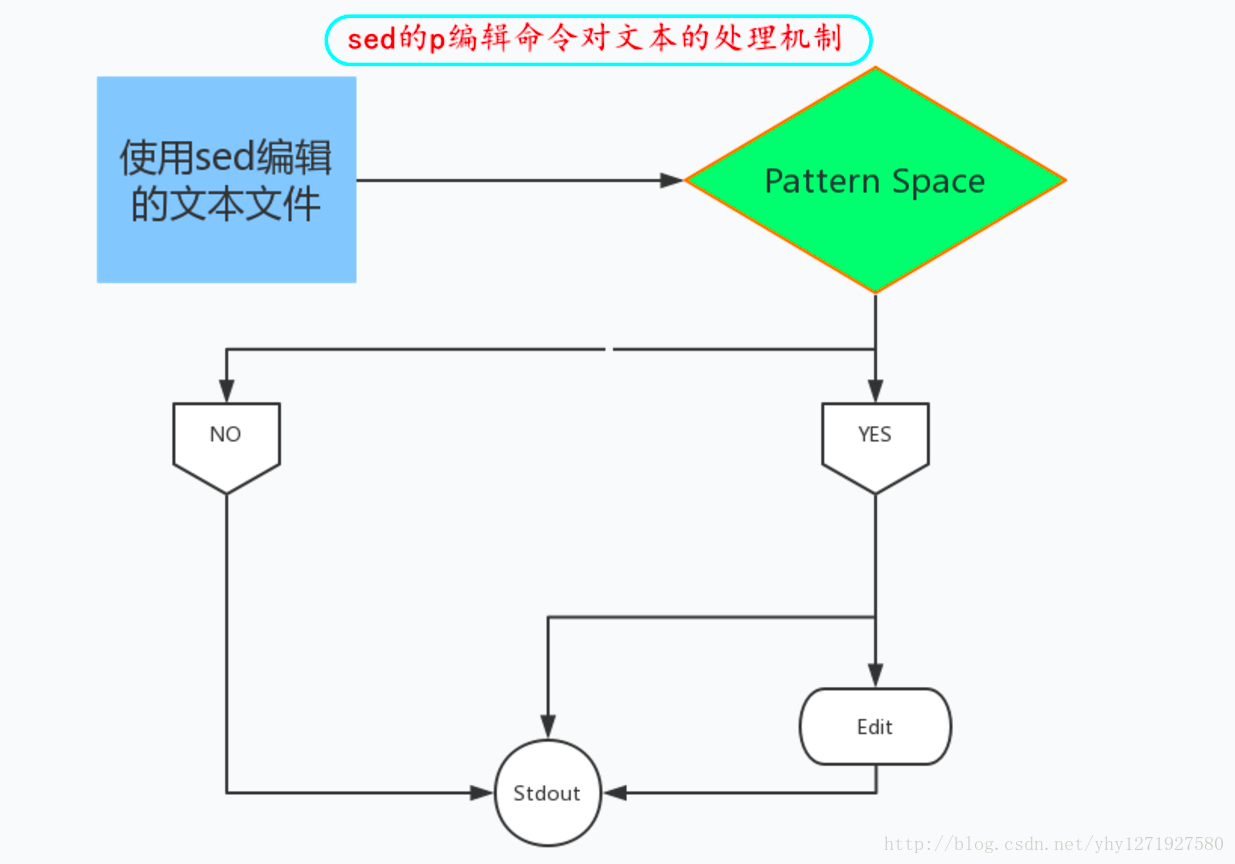
p:打印
- 例如:sed ‘/^#/p’ /etc/fstab:’/^#/p’ 表示SCRIPT脚本匹配,会将以#开头的行进行编辑处理,但是没有被编辑处理的文本也会被默认输出到标准输出,而被编辑处理的行同样也会输出到标准输出,这样就使得#开头的行变为两行,一般p与-n选项一起使用,表示显示匹配到的行,如:sed -n ‘/^#/p’ /etc/fstab
- 例如:sed ‘/^#/p’ /etc/fstab:’/^#/p’ 表示SCRIPT脚本匹配,会将以#开头的行进行编辑处理,但是没有被编辑处理的文本也会被默认输出到标准输出,而被编辑处理的行同样也会输出到标准输出,这样就使得#开头的行变为两行,一般p与-n选项一起使用,表示显示匹配到的行,如:sed -n ‘/^#/p’ /etc/fstab
- a \text:在行后面追加文本“\text”,支持使用\n实现多行追加
- 例如:sed ‘5a \new line’ /etc/fstab:表示在文本匹配到的第五行后面,也就是第六行插入/new line字符,
- i \text:在行前面插入文本“text”,支持使用\n实现多行插入
- 例如:sed ‘5i \new line’ /etc/fstab :表示在文本的匹配到的第5行插入\new line字符,其后的行一次向下移动
- c \text:把匹配到的行替换为“text”文本
- 例如:sed ‘3c \nihaoma \nhhh’ /etc/fstab 将第三行替换为\nihaoma字符
- w:/PATH/TO/SOMEFILE:保存模式空间匹配到的行到指定的文件中
- 例如:sed ‘/^[^#]/w /yes.txt’ /etc/fstab 将非井号开头的行保存至/yes.txt文件中
- r:/PATH/FROM/SOMEFILE:读取指定文件的内容至当前文件被匹配到的行处
- 例如: sed ‘3r /etc/issue’ /etc/fstab 将/etc/issue中的内容插入到第3行的文本后面
- =:表示为模式匹配到的行打印行号
- !:取反条件
- 例如:sed ‘/^#/!w /yes.txt’ /etc/fstab
- s///:查找替换,其分隔符可以自行指定,常用的有s@@@, s### ,
- 替换标记
- g:全局替换
- w /PATH/TO/SOMEFILE:替换成功的结果保存至指定文件中
- p :显示替换成功的行
- 1:删除/etc/grub2.cfg文件中所有的以空白字符开头的行的行首的所有空白字符
- 替换标记
sed 's#^[[:space:]]\+##' /etc/grub2.cfg- 2:删除/etc/fstab文件中所有以#开头的行的行首的#号以及#号后面的所有空白字符
sed -r 's/^#[[:space:]]*//' /etc/fstab- 3:输出一个绝对路径给sed命令,取出其文件名
echo "/var/log/messages" | sed -r 's#^.*/(.*$)#\1#' - 4:输出一个绝对路径给sed命令,取出其目录名,相当于dirname
echo "/var/log/messages/" | sed -r 's#[^/]+/?$##' awk工作机制:- 文本处理工具:grep ,sed,awk
- grep , egrep:文本过滤工具
- sed:行编辑器。 模式空间,保持空间
- awk:报表生成器,格式化文本输出
- gawk - pattern scanning and processing language
- 基本用法
- awk [options] ‘program’ FILE
- program : PATTERN{ACTION STATEMENTS}
- 语句之间用分号分割
- print ,printf
- 选项
- -F :指明输入时用到的字段分隔符
- -v:var=value :自定义变量
- program : PATTERN{ACTION STATEMENTS}
- awk [options] ‘program’ FILE
- 1:print
- print item1,item2…
- 要点:
- (1)逗号分隔符
- (2)输出的各个item可以是字符串,也可以是数值,当前的记录的字段、变量、或awk的表达式
- (3)在awk中,如果变量放在引号内部,则不会做变量替换的,比如:{print ‘$1’} ,如果想做变量替换,那么需要将变量放在引号外,
例如:{print $1 $2} - (4)如果不是用
$1 , $2,那么print 默认为$0
- 2:变量
- 内建变量,自定义变量
- FS:input field seperator,默认为空白字符
- 例如:
awk -v FS=':' '{print $1}' /etc/passwd或awk -F: '{print $1}' /etc/passwd
- 例如:
- OFS:output field seperator,默认为空白字符
awk -F: -v OFS=':' '{print $1}' /etc/passwd
- RS:input record seperator ,输入时的换行符
- ORS:output record seperator,输出时的换行符
- NF:number of field ,字段的个数
awk '{print $NF}' /etc/fstab:表示打印每一行的字段的个数awk '{print $NF}' /etc/fstab:表示打印每一行最后一个字段
- NR:number of record 用来指定行号;
- FNR:各文件分别计数
- FILENAME:当前文件名
- ARGC:命令行参数的个数
- ARGV :数组,保存的是命令行给定的各参数
- FS:input field seperator,默认为空白字符
- 自定义变量
- (1)-v var=val
- 变量名区分字符大小写
- (2)在program中直接定义
- (1)-v var=val
- 内建变量,自定义变量
- 3:printf命令
- 格式化输出:printf “FORMAT” , item1,item2….
- (1)FORMAT必须给出
- (2)不会自动换行,需要显示给出换行符,\n
- (3)FORMAT中需要分别为后面每个item指定一个格式化符号
- 格式符
- %c:显示字符的ASCLL码
- %d,%i:显示十进制整数
- %e, %E:科学计数法数值显示
- %f:显示为浮点数
- %g, %G:以科学计数法或浮点形式显示数值
- %s:显示字符串
- %u:无符号整数
- %%:显示%自身
- 例如:
awk -F: '{printf "Username:%s\n",$1}' /etc/passwd
- 修饰符
- -:表示左对齐
- +:表示显示数值的符号,正负号
- 例如:
awk -F: '{printf "Username:%-15s UUID:%-5i \n",$1,$3}' /etc/passwd
- 格式符
- 格式化输出:printf “FORMAT” , item1,item2….
- 4:操作符
- 算数运算操作符
- +,-,*,/,^,%
- 字符串操作符:没有符号的操作符,字符串连接
- 赋值操作符:=,+=,-=,/=,…
- 比较操作符:>, >= , <= , != , ==
- 模式匹配符:~ ,!~
- 逻辑操作符:&& || !
- 函数调用:function_name(argu1,argu2)
- 条件表达式:selector?if-yes:if-no
- 例如:
awk -F: '{$3>=500?usertype="Common user":usertype="System user"; printf "%15s:%s\n", $1,usertype}' /etc/passwd
- 例如:
- 算数运算操作符
- 5:PATTERN
- (1)empty:空模式,处理文本的每一行
- (2)/regular expression/:仅处理能够被模式匹配到的行
- (3)relational expression:关系表达式,结果有“真”有“假”,结果为“真”才会被处理,结果为非0 都是真,非空字符串
- 例如:
awk -F: '$3>=500{print $1,$3}' /etc/passwd,其中:$3>=500就是模式匹配的关系表达式 - 例如:
awk -F: '$NF=="/bin/bash"{print $1,$7}' /etc/passwd,找出shell是bash的用户 - 例如:
awk -F: '$NF~/bash$/{print $1,$7}' /etc/passwd找出shell是bash的用户
- 例如:
- (4)line ranges: 指定行范围
- /pat1/,/pat2/:
- 支持关系判断:
awk -F: '(NR>10&&NR<20){print $1}' /etc/passwd
- (5)BEGIN/END模式
- BEGIN{}:仅在开始处理文件中的文本之前执行一次
- END{}:仅在处理文件中的文本之后执行一次
- 6:常用的action
- (1)Expressions
- (2)Control statement: if ,while等等
- (3)Compound statements :组合语句
- (4)input statements
- (5)output statements
- 7:控制语句
- if(condition){statements}
- if(condition){statements} else {statements}
- while(condition){statements}
- do {statement} while (condition)
- for(){statement}
- break continue delete array[index]
- exit
- 7.1 if-else
- 语法:if(condition){statement}
- 例如:
awk -F: '{if($3<500) print $1,$3}' /etc/passwd - 例如:
awk -F: '{if($3>=500) {printf "common user:%10s\n",$1} else {printf "system user:%10s\n",$1}}' /etc/passwd - 使用场景:对awk取得的整行或某个字段做条件判断
- 例如:
- 语法:if(condition){statement}
- 7.2 while循环
- 语法:while(condition)statement
- 使用场景:对一行的多个字段逐一进行循环
- 7.3 do while 循环
- 语法:do {statement} while(condition)
- 7.4 for循环
- 语法:for(;;)statement
- 特殊用法:能够遍历数组中的元素
- 语法:for(var in array)
- 7.5 swhich语句
- 语法:swhich(expression){case VALUE1: STATEMENT1 ; case VALUE2: STATEMENT2 ; default STATEMENT}
- 7.6 break 和continue
- 7.7 next:能直接退出本行的处理,直接进行下一行
- array
- 关联数组:array[index-expression]
- index-expression:
- (1)索引可以使用任意字符串,字符串要加双引号
- (2)如果说某数组元素,事先不存在,在引用时,AWK会自己创建元素,并初始化为空
- (3)要判断数组中,是否存在某个元素,使用“index in array ” 格式进行
- 要遍历数组中的元素,要使用for循环
- for(var in array)
- awk ‘{ip[$1]++}END{for(i in ip) {print i, ip[i]}}’ /var/log/httpd/access_log
- index-expression:
- 关联数组:array[index-expression]
- 9:函数
- 9.1:内置函数
- 数值处理:
- rand(): 显示0-1之间一个随机数
- 字符串处理:
- length():返回字符串的长度
- sub(r,s,[t]):以r表示的模式来查找t所表示的字符串中的匹配的内容
- 数值处理:
- 9.1:内置函数
2、删除/boot/grub/grub.conf文件中所有行的行首的空白字符;
sed -r 's/^[[:space:]]+//' /boot/grub/grub.conf
3、删除/etc/fstab文件中所有以#开头,后跟至少一个空白字符的行的行首的#和空白字符;
sed -r 's/^#[[:space:]]+//' /etc/fstab
4、把/etc/fstab文件的奇数行另存为/tmp/fstab.3;
sed -rn '1~2w/tmp/fstab.3' /etc/fstab
5、echo一个文件路径给sed命令,取出其基名;进一步地,取出其路径名;
echo /var/log/massages | sed -r 's#(^.*)/(.*$)$#\1 \n\2#'
6、统计指定文件中所有行中每个单词出现的次数;?
-awk '{for(i=1;i<=NF;i++){count[$i]++}}END{for(i in count){print i,count[i]}}' /etc/fstab7、统计当前系统上所有tcp连接的各种状态的个数;?
netstat -tan | awk 'FNR>2{print $NF}' | sort| uniq -c
8、统计指定的web访问日志中各ip的资源访问次数:?
awk '{ip[$1]++}END{for(i in ip) {print i,ip[i]}}' /var/log/httpd/access_log
9、写一个脚本:定义一个数组,数组元素为/var/log目录下所有以.log结尾的文件的名字;显示每个文件的行数;?
#!/bin/bash
test=$(ls /var/log/*log)
for i in $test
do
wc -l $i
done
10、写一个脚本,能从所有同学中随机挑选一个同学回答问题;进一步地:可接受一个参数,做为要挑选的同学的个数;?
#!/bin/bash
#(一)写一个脚本,能从所有同学中随机挑选一个同学回答问题
declare -a students
declare -i k=0
declare -i j
# 给students数组赋值
for i in student1 student2 student3 student4 student5 student6 student7 student8 ; do
students[$k]=$i
let k++
done
# 随机取出数组的索引
j=$[ $RANDOM%${#students[*]} ]
# 根据随机取出的索引取出数组中的值
echo "${students[j]}"
#!/bin/bash
# (二)进一步地:可接受一个参数,做为要挑选的同学的个数
# 必须输入的是{1|2|3|4|5|6|7|8}中的其中一个
read -p "Please input one number, USEAGE {1|2|3|4|5|6|7|8}: " number
while [ "$number" != "1" -a "$number" != "2" -a "$number" != "3" -a "$number" != "4" -a "$number" != "5" -a "$number" != "6" -a "$number" != "7" -a "$number" != "8" ];do
read -p "Please input one number, USEAGE {1|2|3|4|5|6|7|8}: " number
done
declare -a students
declare -i k=1
for i in student1 student2 student3 student4 student5 student6 student7 student8 ; do
students[$k]=$i
let k++
done
echo "${students[$number]}"
11、授权centos用户可以运行fdisk命令完成磁盘管理,以及使用mkfs或mke2fs实现文件系统管理;
centos ALL=(root) /sbin/fdisk, /sbin/mke2fs, /sbin/mkfs
12、授权gentoo用户可以运行逻辑卷管理的相关命令;
gentoo ALL=(root) lvm
13、基于pam_time.so模块,限制用户通过sshd服务远程登录只能在工作时间进行;
在/etc/pam.d/sshd文件中添加
account required pam_time.so
在/etc/security/time.conf文件中设置
#表示工作时间9点到下午6点允许访问ssh
*;*;*;MoTuWeThFr0900-180014、基于pam_listfile.so模块,定义仅某些用户,或某些组内的用户可登录系统;
编辑 vim /etc/sshd_userlist文件
添加用户 yhy1 yhy2 yhy3
chmod 600 /etc/sshd_userlist
chown root /etc/sshd_userlist
编辑/etc/pam.d/sshd文件
auth required pam_listfile.so item=user sense=allow file=/etc/sshd_userlist onerr=succeed














 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









