






1.1 迁移学习
在机器学习领域,迁移学习(Transferlearning)是一个比较新的名词。目前国内做这个方面的很少,我目前只知道香港科技大学杨强教授及上海交大的机器学习小组在从事这方面的研究,他们的学生Erheng Zhong以及一帮人就建立了这个一个资源。近几年他们已经取得大量的成果,发表了十几篇AI领域顶级的会议论文。
Qiang Yang
SinnoJialin Pan
http://www.cse.ust.hk/~sinnopan/
转载于: http://apex.sjtu.edu.cn/apex_wiki/Transfer%20Learning
一个关于迁移学习(Transfer Learning)的资源,里面不管是code还是paper还是contest都很全面。
在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模 型;然后利用这个学习到的模型来对测试文档进行分类与预测。
然而,我们看到机器学习算法在当前的Web挖掘研究中存在着一个关键的问题:一些新出现的领域中的大量训练数据非常难得到。我们看到Web应用领域的发展 很快速。大量新的领域不断涌现,从传统的新闻,到网页,到图片,再到博客、播客等。传统的 机器学习需要对每个领域都标定大量训练数据,这将会耗费大量的人力与物力。而没有大量的标注数据,会使得很多与学习相关研究与应用无法开展。其次,传统的机器学习假设训练数据与测试数据服从相同的数据分布。然而,在许多情况下,这种同分布假设并不满足。通常可能发生的情况如训练数据过期。这往往需要我们去重新标注大量的训练数据以满足我们训练的需要,但标注新数据是非常昂贵的,需要大量的人力与物力。从另外一个角度上看,如果我们有了大量的、在不同分布下的训练数据,完全丢弃这些数据也是非常浪费的。
如何合理的利用这些数据就是迁移学习主要解决的问题。迁移学习可以从现有的数据中迁移知识,用来帮助将来的学习。迁移学习(Transfer Learning)的目标是将从一个环境中学到的知识用来帮助新环境中的学习任务。因此,迁移学习不会像传统机器学习那样作同分布假设。
我们在迁移学习方面的工作目前可以分为以下三个部分:
同构空间下基于实例的迁移学习,
同构空间下基于特征的迁移学习,
异构空间下的迁移学习。
我们的研究指出,基于实例的迁移学习有更强的知识迁移能力,基于特征的迁移学习具有更广泛的知识迁移能力,而异构空间的迁移具有广泛的学习与扩展能力。这几种方法各有千秋。
1.同构空间下基于实例的迁移学习
基于实例的迁移学习的基本思想是,尽管辅助训练数据和源训练数据或多或少会有些不同,但是辅助训练数据中应该还是会存在一部分比较适合用来训练一个有效的分类模型,并且适应测试数据。于是,我们的目标就是从辅助训练数据中找出那些适合测试数据的实例,并将这些实例迁移到源训练数据的学习中去。
在基于实例的 迁移学习方面,我们推广了传统的AdaBoost算 法,提出一种具有迁移能力的boosting算法:Tradaboosting [9],使之具有迁移学习的能力,从而能够最大限度的利用辅助训练数据来帮助目标的分类。我们的关键想法是,利用boosting的技术来过滤掉辅助数据中那些与源训练数据最不像的数据。其中,boosting的作用是建立一种自动调整权重的机制,于是重要的辅助训练数据的权重将会增加,不重要的辅助训练 数据的权重将会减小。调整权重之后,这些带权重的辅助训练数据将会作为额外的训练数据,与源训练数据一起从来提高分类模型的可靠度。
基于实例的迁移学习只能发生在源数据与辅助数据非常相近的情况下。但是,当源数据和辅助数据差别比较大的时候,基于实例的迁移学习算法往往很难找到可以迁移的知识。但是我们发现,即便有时源数据与目标数据在实例层面上并没有共享一些公共的知识,它们可能会在特征层面上有一些交集。因此我们研究了基于特征的迁移学习,讨论的是如何利用特征层面上公共的知识进行学习的问题。
2.同构空间下基于特征的迁移学习
在基于特征的迁移学习研究方面,我们提出了多种学习的算法,如CoCC算法[7],TPLSA算法[4],谱分析算法[2]与自学习算法[3]等。其中利用互聚类算法产生一个公共的特征表示,从而帮助学习算法。我们的基本思想是使用互聚类算法同时对源数据与辅助数据进行聚类,得到一个共同的特征表示,这个新的特征表示优于只基于源数据的特征表示。通过把源数据表示在这个新的空间里,以实现迁移学习。应用这个思想,我们提出了基于特征的有监督迁移学习与基于特征的无监督迁移学习。
1) 基于特征的有监督迁移学习
我们在基于特征的有监督迁移学习方面的工作是基于互聚类的跨领域分类[7],这个工作考虑的问题是:当给定一个新的、不同的领域,标注数据及其稀少时,如何利用原有领域中含有的大量标注数据进行迁移学习的问题。在基于互聚类的跨领域分类这个工作中,我们为跨领域分类问题定义了一个统一的信息论形式化公式,其中基于互聚类的分类问题的转化成对目标函数的最优化问题。在我们提出的模型中,目标函数被定义为源数据实例,公共特征空间与辅助数据实例间互信息的损失。
2)基于特征的无监督迁移学习:自学习聚类
我们提出的自学习聚类算法[3]属于基于特征的无监督迁移学习方面的工作。这里我们考虑的问题是:现实中可能有标记的辅助数据都难以得到,在这种情况下如何利用大量无标记数据辅助数据进行迁移学习的问题。自学习聚类的基本思想是通过同时对源数据与辅助数据进行聚类得到一个共同的特征表示,而这个新的特征表示由于基于大量的辅助数据,所以会优于仅基于源数据而产生的特征表示,从而对聚类产生帮助。
上面提出的两种学习策略(基于特征的有监督迁移学习与无监督迁移学习)解决的都是源数据与辅助数据在同一特征空间内的基于特征的迁移学习问题。当源数据与辅助数据所在的特征空间中不同时,我们还研究了跨特征空间的基于特征的迁移学习,它也属于基于特征的迁移学习的一种。
3.异构空间下的迁移学习:翻译学习
我们提出的翻译学习[1][5]致力于解决源数据与测试数据分别属于两个不同的特征空间下的情况。在[1]中,我们使用大量容易得到的标注过文本数据去帮助仅有少量标注的图像分类的问题,如上图所示。我们的方法基于使用那些用有两个视角的数据来构建沟通两个特征空间的桥梁。虽然这些多视角数据可能不一定能够用来做分类用的训练数据,但是,它们可以用来构建翻译器。通过这个翻译器,我们把近邻算法和特征翻译结合在一起,将辅助数据翻译到源数据特征空间里去,用一个统一的语言模型进行学习与分类。
实例
《Boostingfor Transfer Learning》论文解读:
小牛上海交大的Wenyuan Dai在2007年的ICML上发表
Boosting for transfer learning
Full Text:
Authors:
Shanghai Jiao Tong University, China
Hong Kong University of Science and Technology, Hong Kong
Shanghai Jiao Tong University, China
Shanghai Jiao Tong University, China
先介绍一下作者,Wenyuan Dai,上海交大ACM班的,2005年ACM的世界决赛的冠军,在本科貌似就开始做研究,在上交Yu Yong教授的APEX实验室里做了一些关于TransferLearning的研究和应用,ICML、NIPS等上面都有文章发表。硕士毕业被百度以高薪(相当高啊)聘请。
Transfer learning is what happens whensomeone finds it much easier to learn to play chess having already learned toplay checkers, or to recognize tables having already learned to recognizechairs; or to learn Spanish having already learned Italian。
今天看的这篇文章构思相对简单,就是对AdaBoost的扩展,called TrAdaBoost,因为AdaBoost的一个鲜明特点就是能够对训练集的不同instance进行weight,显然,weight高的那些instance其实数据属性和test集的数据属性(可以理解为分布)更相似。利用这个特点,可以做一下对于数据的迁移。
Transfer Learning,简单的理解就是由于标记的有效样本很少很少,所以可以将一些过时的或者其他类别的有效数据引进来进行模型的训练。就拿文章中的例子吧,对于web上的一些新闻等,现在训练处一个模型,那么等过一段时间,这个模型以及训练集可能已经过时了,对于最新的数据预测就不好。那么我们都知道标记新的数据是非常耗费精力和人力的,怎么利用使旧的数据也能够发挥作用呢?Adaboost迭代收敛之后那些weight大的旧数据就可以起作用了。
TrAdaBoost的实验效果还真是不错,和不能做迁移的SVM相比当然效果提高很大,但是当训练集中的本类数据达到20%的时候,其实就变成了监督学习,那么就和SVM等学习效果差不多了。但是当本类数据的比例小于10%的时候,Transfer 的效果就很明显了。
关于TrAdaBoost的收敛性以及泛化能力的证明其实都是扩展自AdaBoost了,不多说了。
1.2 概率图模型

我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
条件概率可以理解成下面的式子: 后验概率 = 先验概率 x 调整因子
这就是贝叶斯推断的含义。我们先预估一个"先验概率",然后加入实验结果,看这个实验到底是增强还是削弱了"先验概率",由此得到更接近事实的"后验概率"。
在这里,如果"可能性函数"P(B|A)/P(B)>1,意味着"先验概率"被增强,事件A的发生的可能性变大;如果"可能性函数"=1,意味着B事件无助于判断事件A的可能性;如果"可能性函数"<1,意味着"先验概率"被削弱,事件A的可能性变小。
使用Google的时候,如果你拼错一个单词,它会提醒你正确的拼法。
比如,你不小心输入了seperate。

Google告诉你,这个词是不存在的,正确的拼法是separate。

这就叫做"拼写检查"(spelling corrector)。有好几种方法可以实现这个功能,Google使用的是基于贝叶斯推断的统计学方法。这种方法的特点就是快,很短的时间内处理大量文本,并且有很高的精确度(90%以上)。Google的研发总监Peter Norvig,写过一篇著名的文章,解释这种方法的原理。
下面我们就来看看,怎么利用贝叶斯推断,实现"拼写检查"。其实很简单,一小段代码就够了。
一、原理
用户输入了一个单词。这时分成两种情况:拼写正确,或者拼写不正确。我们把拼写正确的情况记做c(代表correct),拼写错误的情况记做w(代表wrong)。
所谓"拼写检查",就是在发生w的情况下,试图推断出c。从概率论的角度看,就是已知w,然后在若干个备选方案中,找出可能性最大的那个c,也就是求下面这个式子的最大值。
P(c|w)
根据贝叶斯定理:
P(c|w) = P(w|c) * P(c) / P(w)
对于所有备选的c来说,对应的都是同一个w,所以它们的P(w)是相同的,因此我们求的其实是
P(w|c) * P(c)
的最大值。
P(c)的含义是,某个正确的词的出现"概率",它可以用"频率"代替。如果我们有一个足够大的文本库,那么这个文本库中每个单词的出现频率,就相当于它的发生概率。某个词的出现频率越高,P(c)就越大。
P(w|c)的含义是,在试图拼写c的情况下,出现拼写错误w的概率。这需要统计数据的支持,但是为了简化问题,我们假设两个单词在字形上越接近,就有越可能拼错,P(w|C)就越大。举例来说,相差一个字母的拼法,就比相差两个字母的拼法,发生概率更高。你想拼写单词hello,那么错误拼成hallo(相差一个字母)的可能性,就比拼成haallo高(相差两个字母)。
所以,我们只要找到与输入单词在字形上最相近的那些词,再在其中挑出出现频率最高的一个,就能实现 P(w|c) * P(c) 的最大值。
二、算法
最简单的算法,只需要四步就够了。
第一步,建立一个足够大的文本库。
网上有一些免费来源,比如古登堡计划、Wiktionary、英国国家语料库等等。
第二步,取出文本库的每一个单词,统计它们的出现频率。
第三步,根据用户输入的单词,得到其所有可能的拼写相近的形式。
所谓"拼写相近",指的是两个单词之间的"编辑距离"(edit distance)不超过2。也就是说,两个词只相差1到2个字母,只通过----删除、交换、更改和插入----这四种操作中的一种,就可以让一个词变成另一个词。
第四步,比较所有拼写相近的词在文本库的出现频率。频率最高的那个词,就是正确的拼法。
根据Peter Norvig的验证,这种算法的精确度大约为60%-70%(10个拼写错误能够检查出6个。)虽然不令人满意,但是能够接受。毕竟它足够简单,计算速度极快。(本文的最后部分,将详细讨论这种算法的缺陷在哪里。)
三、代码
我们使用Python语言,实现上一节的算法。
第一步,把网上下载的文本库保存为big.txt文件。这步不需要编程。
第二步,加载Python的正则语言模块(re)和collections模块,后面要用到。
import re, collections
第三步,定义words()函数,用来取出文本库的每一个词。
def words(text): return re.findall('[a-z]+', text.lower())
lower()将所有词都转成小写,避免因为大小写不同,而被算作两个词。
第四步,定义一个train()函数,用来建立一个"字典"结构。文本库的每一个词,都是这个"字典"的键;它们所对应的值,就是这个词在文本库的出现频率。
def train(features):
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] += 1
return model
collections.defaultdict(lambda: 1)的意思是,每一个词的默认出现频率为1。这是针对那些没有出现在文本库的词。如果一个词没有在文本库出现,我们并不能认定它就是一个不存在的词,因此将每个词出现的默认频率设为1。以后每出现一次,频率就增加1。
第五步,使用words()和train()函数,生成上一步的"词频字典",放入变量NWORDS。
NWORDS = train(words(file('big.txt').read()))
第六步,定义edits1()函数,用来生成所有与输入参数word的"编辑距离"为1的词。
alphabet = 'abcdefghijklmnopqrstuvwxyz'
def edits1(word):
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [a + b[1:] for a, b in splits if b]
transposes = [a + b[1] + b[0] + b[2:] for a, b in splits if len(b)>1]
replaces = [a + c + b[1:] for a, b in splits for c in alphabet if b]
inserts = [a + c + b for a, b in splits for c in alphabet]
return set(deletes + transposes + replaces + inserts)
edit1()函数中的几个变量的含义如下:
(1)splits:将word依次按照每一位分割成前后两半。比如,'abc'会被分割成 [('', 'abc'), ('a', 'bc'), ('ab', 'c'), ('abc', '')] 。
(2)beletes:依次删除word的每一位后、所形成的所有新词。比如,'abc'对应的deletes就是 ['bc', 'ac', 'ab'] 。
(3)transposes:依次交换word的邻近两位,所形成的所有新词。比如,'abc'对应的transposes就是 ['bac', 'acb'] 。
(4)replaces:将word的每一位依次替换成其他25个字母,所形成的所有新词。比如,'abc'对应的replaces就是 ['abc', 'bbc', 'cbc', ... , 'abx', ' aby', 'abz' ] ,一共包含78个词(26 × 3)。
(5)inserts:在word的邻近两位之间依次插入一个字母,所形成的所有新词。比如,'abc' 对应的inserts就是['aabc', 'babc', 'cabc', ..., 'abcx', 'abcy', 'abcz'],一共包含104个词(26 × 4)。
最后,edit1()返回deletes、transposes、replaces、inserts的合集,这就是与word"编辑距离"等于1的所有词。对于一个n位的词,会返回54n+25个词。
第七步,定义edit2()函数,用来生成所有与word的"编辑距离"为2的词语。
def edits2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1))
但是这样的话,会返回一个 (54n+25) * (54n+25) 的数组,实在是太大了。因此,我们将edit2()改为known_edits2()函数,将返回的词限定为在文本库中出现过的词。
def known_edits2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS)
第八步,定义correct()函数,用来从所有备选的词中,选出用户最可能想要拼写的词。
def known(words): return set(w for w in words if w in NWORDS)
def correct(word):
candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word]
return max(candidates, key=NWORDS.get)
我们采用的规则为:
(1)如果word是文本库现有的词,说明该词拼写正确,直接返回这个词;
(2)如果word不是现有的词,则返回"编辑距离"为1的词之中,在文本库出现频率最高的那个词;
(3)如果"编辑距离"为1的词,都不是文本库现有的词,则返回"编辑距离"为2的词中,出现频率最高的那个词;
(4)如果上述三条规则,都无法得到结果,则直接返回word。
至此,代码全部完成,合起来一共21行。
import re, collections
def words(text): return re.findall('[a-z]+', text.lower())
def train(features):
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] += 1
return model
NWORDS = train(words(file('big.txt').read()))
alphabet = 'abcdefghijklmnopqrstuvwxyz'
def edits1(word):
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [a + b[1:] for a, b in splits if b]
transposes = [a + b[1] + b[0] + b[2:] for a, b in splits if len(b)>1]
replaces = [a + c + b[1:] for a, b in splits for c in alphabet if b]
inserts = [a + c + b for a, b in splits for c in alphabet]
return set(deletes + transposes + replaces + inserts)
def known_edits2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS)
def known(words): return set(w for w in words if w in NWORDS)
def correct(word):
candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word]
return max(candidates, key=NWORDS.get)
使用方法如下:
>>> correct('speling')
'spelling'
>>> correct('korrecter')
'corrector'
四、缺陷
我们使用的这种算法,有一些缺陷,如果投入生产环境,必须在这些方面加入改进。
(1)文本库必须有很高的精确性,不能包含拼写错误的词。
如果用户输入一个错误的拼法,文本库恰好包含了这种拼法,它就会被当成正确的拼法。
(2)对于不包含在文本库中的新词,没有提出解决办法。
如果用户输入一个新词,这个词不在文本库之中,就会被当作错误的拼写进行纠正。
(3)程序返回的是"编辑距离"为1的词,但某些情况下,正确的词的"编辑距离"为2。
比如,用户输入reciet,会被纠正为recite(编辑距离为1),但用户真正想要输入的词是receipt(编辑距离为2)。也就是说,"编辑距离"越短越正确的规则,并非所有情况下都成立。
(4)有些常见拼写错误的"编辑距离"大于2。
这样的错误,程序无法发现。下面就是一些例子,每一行前面那个词是正确的拼法,后面那个则是常见的错误拼法。
purple perpul
curtains courtens
minutes muinets
successful sucssuful
inefficient ineffiect
availability avaiblity
dissension desention
unnecessarily unessasarily
necessary nessasary
unnecessary unessessay
night nite
assessing accesing
necessitates nessisitates
(5)用户输入的词的拼写正确,但是其实想输入的是另一个词。
比如,用户输入是where,这个词拼写正确,程序不会纠正。但是,用户真正想输入的其实是were,不小心多打了一个h。
(6)程序返回的是出现频率最高的词,但用户真正想输入的是另一个词。
比如,用户输入ther,程序会返回the,因为它的出现频率最高。但是,用户真正想输入的其实是their,少打了一个i。也就是说,出现频率最高的词,不一定就是用户想输入的词。
(7)某些词有不同的拼法,程序无法辨别。
比如,英国英语和美国英语的拼法不一致。英国用户输入'humur',应该被纠正为'humour';美国用户输入'humur',应该被纠正为'humor'。但是,我们的程序会统一纠正为'humor'。
1.2.1 贝叶斯的网络结构
(1)定义:贝叶斯网络(Bayesian Networks, BNs)也称作贝叶斯网(Bayesian Nets)或者信念网络(Belief Networks)。它是表示变量之间相互作用的图形模型。贝叶斯网络由节点和节点之间的弧组成,每个节点对应一个随机变量X,并且具有一个对应该随机变量的概率P(X)。如果存在一条从节点X到节点Y的有向弧,则表明X对Y有直接影响,该影响被条件概率P(Y/X)所指定。另外,贝叶斯网络是一个有向无环图,即图中没有环。节点和节点之间的弧定义了网络的结构,而条件概率是给定结构的参数。
上述概念也许从文字上不好理解,我们通过图形来理解。下图中图(a)表示朴素贝叶斯网络,图(b)表示一般情形的贝叶斯网络。
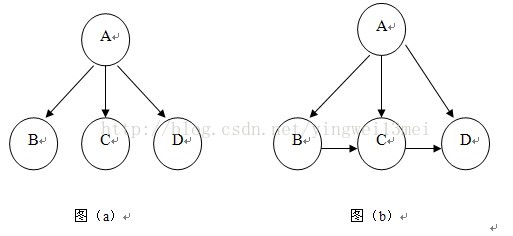
对于图(a)中朴素贝叶斯网络而言,假定特征属性B、C、D之间是相互独立的,所以他们之间没有边相连。也就是说,在给定A的情况下特征属性B的发生与给定A的情况下特征属性C的发生是相互独立的。由于各个属性都有一条从A指向其的边,所以所有的属性都依赖于类别变量A。而对于图(b)中贝叶斯网络而言,B到C和C到D之间是有边相连的,这也意味着他们之间是有关联的。这在很大程度上减轻了条件独立性的假设。也就是说给定A的情况下特征属性C的发生还与给定A情况下B的发生是有联系。
上面我们提到,节点之间如果有边表示他们之间是有联系的,而因为该边是有向的,如果有一条A到B的有向弧,其含义我们暂时可以理解为A“causes”B,后面我们还会详细介绍它。这个信息可以指引我们建立一个图的结构。
对于贝叶斯网络而言,我们必须定义每个节点的条件概率分布(Conditional Probability Distribution, CPD)。如果该变量是离散的,那么他们可以用条件概率表(CPT)来表示。 条件概率表列出了每个节点对于父节点不同组合取值时,它取不同值的概率。下面我们来看一个具体的例子,假定每个节点都只有两种取值,即T(true)或者F(false)。
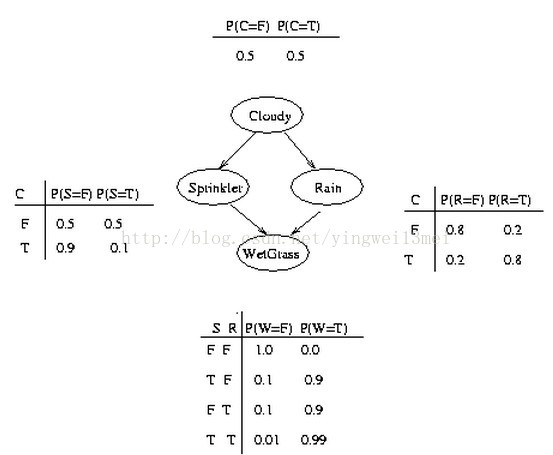
从上图中,我们可以看到,事件“草地湿了”(W = true)发生有两种原因:要么是洒水器开了(S = true),要么是下雨了(R = true)。各个节点之间的关系列在了表中。例如,在上图最下方的一个CPT中,P(W=true | S=true, R=false) = 0.9 (第二行), 从而P(W=false | S=true, R=false) = 1 - 0.9 = 0.1(因为每一行的值加起来必须等于1)。另外由于C节点没有父节点,其CPT定义了该节点的先验概率。
上述图中,所有节点的联合概率的表达式如下:
P(C, S, R, W) = P(C) * P(S|C) * P(R|C,S) * P(W|C,S,R)
通过利用节点间的条件独立性关系,对于上式倒数第二项,R的发生仅与C有关而与S的发生无关;同样的,最后一项W的发生仅与S和R的发生有关,而与C无关。所以上式可以改写为:
P(C, S, R, W) = P(C) * P(S|C) * P(R|C) * P(W|S,R)
值得一提的是,尽管上面这个例子中,由于条件独立性为我们带来的计算量的减少不大,但是在大多数场合下,它的功效是非常大的。
至此,也许你会问,既然是贝叶斯网络,为什么到现在我还没有看到任何关于贝叶斯的影子呢?事实上,你说的没错,上述条件概率分布(CPD)通常我们是通过频率计算方法得到的。而称作其为贝叶斯网络,实际上,我们应用的是其概率的推理,让我们继续往下看。
(2)推理(Inference)
使用贝叶斯网络通常我们希望通过它得到概率推理。例如对于上述网络,假如我们已经观察到“草地湿了”,我们知道有两种可能,但是,哪一种更有可能是的呢?利用贝叶斯定理我们可以得到如下计算(1表示true,0表示false)。
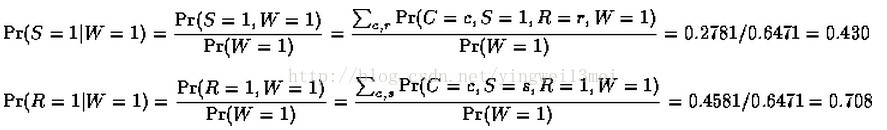
上式中Pr(W = 1)的计算如下:
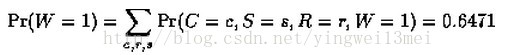
所以根据上面的计算,我们可以推断,事件“草地湿了”的发生更可能是因为下雨了。
上面我们给出了计算,我们也称为诊断或者“bottom up”reasoning,因为直观上他是从底部到上面,根据结果来推断原因。除了这个以外,我们还可以计算,如果天气是cloudy,那么“草地湿了”的概率?这也称为“top down”reasoning。
(3)因果性(Causality)
前面我们提到过,贝叶斯网络中,从A指向B的有向弧,我们可以理解为A导致B的发生。一个有趣的问题是:我们能区分出变量之间的因果性和纯粹的关联性吗?答案是,有时候,并且你需要测量至少三个变量之间的关系才行。所以在利用贝叶斯网络来做推理之前,我们还必须学习其结构,也就是将节点之间的关系通过图来建模。这就是第四部分我们要将的内容。
到这里,我们可以知道,贝叶斯网络描述了一种概率分布,它通过指定一些条件独立的假定和一组条件概率来管理一组变量(A Bayesian network describes the probability distribution governing a set of variables by specifying a set of conditional independence assumptions along with a set of conditional probabilities)。另外,对于条件独立性的假定仅仅应用在其子集变量中。
(4)学习贝叶斯网络结构
有些时候,我们根本不知道网络的结构或者说只是知道结构的一部分,这个时候我们就需要学习贝叶斯网络的结构。
有两种方法学习贝叶斯网络的结构:参数学习和结构学习。
参数学习适用于网络结构是已知的。它又有2种情况:第一种情况是网络结构是已知的,并且网络结构中没有隐藏或者丢失变量;另一种是网络结构也是已知的,但是有隐藏或者丢失的变量。在第一种情况下,主要的任务是估计条件概率;而在第二种情况下,需要一个本地优化解决方案,例如期望最大化算法(Expectation Maximization, EM)。
当数据集D潜在的结构未知的时候,此时应该运用结构学习。结构学习的任务可以表述如下:给定一个训练集D,找到一个与D最相匹配的网络B,此时D是一个独立的实例。结构学习也有两种不同的从数据集中找到接近图概率模型学习的方法。即基于依附分析的方法(dependency-analysis-based methods)和搜索计分方法(search and score methods)。
基于依附分析的方法依赖于这样一个假定,即所研究的潜在的网络中节点之间有很多依赖关系。算法通过对训练集来尝试着发现这些依附节点集的依赖性和独立性,从而利用它们推出网络的结构。依附关系可以通过一些条件独立(Conditional Independence, CI)性测试来计算(也叫基于受限的方法)。
尽管基于依附分析方法有很多优点,但是,当CI测试有很大的条件集时,该方法就不那么可靠了。更流行的做法是搜索记分法。寻找计分方法通过搜索过程来找到能够满足数据集的结构。它试着寻找能最大化选择计分函数的图。这种方法由最简单的图开始,初始不加任何边,然后利用一些搜索算法递归的来加上或者减去一些边。关于结构学习有很多非常实用和著名的实例方法,例如The K2 Algorithm、The MDL length method、The Construct-TAN Algorithm等。
1.2.2 概率图分类
概率图是一类用图的形式表示随机变量之间条件依赖关系的概率模型, 是概率论与图论的结合。图中的节点表示随机变量,缺少边表示条件独立假设。根据图中边的有向、无向性,模型可分为两类:有向图、无向图。
G(V,E):变量关系图
V:顶点or节点,表示随机变量
E:边or弧
两个节点邻接:两个节点之间存在边,记为Xi ~Xj ,不存在边,表示条件独立。
路径:若对每个i,都有Xi-1 ~ Xi ,则称序列(X1, X2 ... XN )是一条路径。
几种概率图模型:
- 朴素贝叶斯分类器(NBs:Naive Bayes)
- 最大熵模型(MEM:Maximum Entropy Model)
- 隐马尔可夫模型(HMM:Hidden Markov Models)
- 最大熵马尔可夫模型(MEMM:Maximum Entropy Markov Model)
- 马尔可夫随机场(MRF:Markov Random Fields)
- 条件随机场(CRF:Conditional Random Fields)
1.NBs
贝叶斯定理
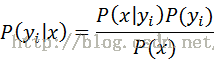
一般来说,x已给出,P(x)也是一个定值(虽然不知道准确的数据,但因为是恒值,可以忽略),只需关注分子P(x|yi)P(yi)。P(yi)是类别yi的先验概率,P(x|yi)是x对类别yi的条件概率。
贝叶斯定理说明了可以用先验概率P(yi)来估算后验概率P(x|yi)。
贝叶斯分类器
设x∈Ω是一个类别未知的数据样本,Y为类别集合,若数据样本x属于一个特定的类别,那么分类问题就是决定P(yi|x),即在获得数据样本x时,确定x的最佳分类。所谓最佳分类,一种办法是把它定义为在给定数据集中不同类别yi先验概率的条件下最可能的分类。贝叶斯理论提供了计算这种可能性的一种直接方法。
举一个简单的例子:
yi 是一个包含了整数的数据集合yi=(1,1,1,2,2,5,...,86),每个yi中的数据数量不一定相同,一共有N个这样的yi数据集合,最终组成了一个拥有整数集合的数组。把这个数组当成已经划分好的不同类别。现在给出一个整数,比如1,问这个1属于哪一个集合或者说由某个类别yi产生该整数的可能性是多少?!
利用以上的贝叶斯定理可知,给定整数1的条件下,问属于yi类别,就等同于求解先验概率P(yi)与P(x|yi)的概率乘积大小。P(yi)表示类别yi的分布概率,在这里可以简单地定义为"每个类别yi的数据量/总数据量"(这种定义是有意义的,某个类别包含数据量越大,那么产生这个数据的可能性就越大)。另外,除了这个先验概率P(yi)之外,还要考虑条件概率P(x|yi)。在这个例子中,不同的yi类别可能都包含了1这个整数,但是每个类别中1出现的概率不一样。所以,最后1属于yi类别的概率=类别yi发生的概率×1在类别yi中的出现概率。
贝叶斯网络(Bayesian Network)
贝叶斯网络是最基本的有向图,是类条件概率的建模方法。贝叶斯网络包括两部分:网络拓扑图和概率表。贝叶斯拓扑图的有向边指定了样本之间的关联。
概率图示意
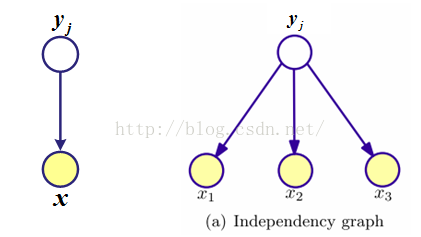
每个节点的条件概率分布表示为:P(当前节点|它的父节点)。
联合分布为:
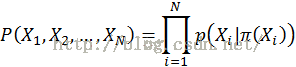
举例:
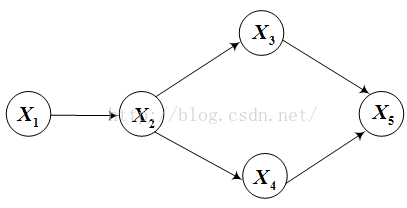
联合分布为
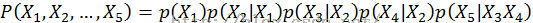
2.MEM
最大熵模型主要是在已有的一些限制条件下估计未知的概率分布。最大熵的原理认为,从不完整的信息(例如有限数量的训练数据)推导出的唯一合理的概率分布应该在满足这些信息提供的约束条件下拥有最大熵值。求解这样的分布是一个典型的约束优化问题。
概率图示意
最大熵推导过程省略,直接给出最后的模型公式——指数形式
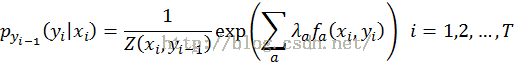
其中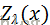
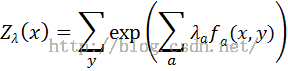
最大熵模型公式中的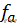
3.HMM
状态集合Y,观察值集合X,两个状态转移概率:从yi-1到yi的条件概率分布P(yi | yi-1),状态yi的输出观察值概率P(xi | yi-1),初始概率P0(y)。
概率示意图
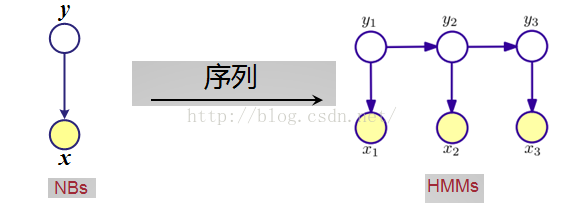
状态序列和观察序列的联合概率
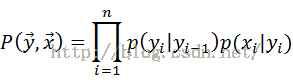
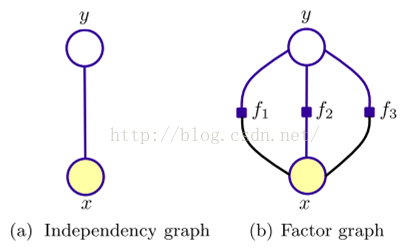
4.MEMM
用一个分布P(yi | yi-1,xi)来替代HMM中的两个条件概率分布,它表示从先前状态yi-1,在观察值xi下得到当前状态的概率,即根据前一状态和当前观察预测当前状态。每个这样的分布函数都是一个服从最大熵的指数模型。
概率图示意
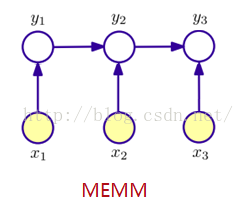
状态yi 的条件概率公式(每个i 的状态输出都服从最大熵的指数模型)
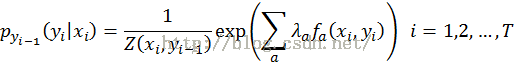
5.MRF
随机场可以看成是一组随机变量(y1, y2, …, yn)的集合(这组随机变量对应同一个样本空间)。当然,这些随机变量之间可能有依赖关系,一般来说,也只有当这些变量之间有依赖关系的时候,我们将其单独拿出来看成一个随机场才有实际意义。
马尔可夫随机场是加了马尔可夫性限制的随机场,一个Markov随机场对应一个无向图。定义无向图G=(V,E),V为顶点/节点, E为边,每一个节点对应一个随机变量,节点之间的边表示节点对应的随机变量之间有概率依赖关系。
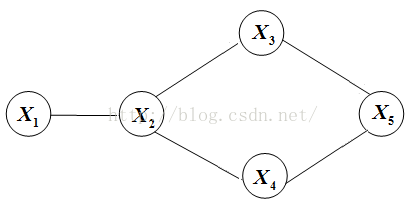
马尔可夫性:对Markov随机场中的任何一个随机变量,给定场中其他所有变量下该变量的分布,等同于给定场中该变量的邻居节点下该变量的分布。即:

其中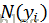
Markov随机场的结构本质上反应了我们的先验知识——哪些变量之间有依赖关系需要考虑,而哪些可以忽略。
马尔可夫性可以看成是马尔科夫随机场的微观属性,而宏观属性就是联合分布。假设MRF的变量集合为Y={y1, y2,…, yn}, CG有是所有团Yc的集合。
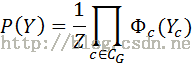
其中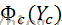
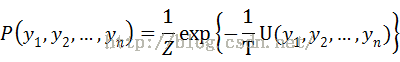
其中Z是归一化因子,是对分子的所有ys = y1, y2,…, yn求和得到。T是个温度常数(一般取1)。U(y1, y2,…, yn)一般称为能量函数(energy function),定义为在MRF上所有团势(clique-potential)之和。
在MRF对应的图中,每一个团(clique)对应一个函数,称为团势(clique-potential)。这个联合概率形式又叫做Gibbs分布(Gibbs distribution)。
Hammersley-Clifford定理给出了Gibbs分布与MRF等价的条件:一个随机场是关于邻域系统的MRF,当且仅当这个随机场是关于邻域系统的Gibbs分布。关于邻域系统δ(s)的MRFX与Gibbs分布等价形式表示为
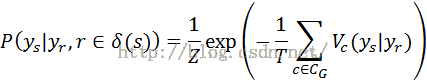
在图像处理中,对先验模型的研究往往转换为对能量函数的研究。C表示邻域系统δ 所包含基团的集合,Vc(·)是定义在基团c上的势函数(potential),它只依赖于δ(s),s∈c的值。δ={δ(s)|s∈S}是定义在S上的通用的邻域系统的集合。
上式解决了求MRF中概率分布的难题,使对MRF的研究转化为对势函数Vc(x)的研究,使Gibbs分布与能量函数建立了等价关系,是研究邻域系统 δ(s) MRF的一个重要里程碑。
6.CRF
如果给定的MRF中每个随机变量下面还有观察值,我们要确定的是给定观察集合下MRF的分布,也就是条件分布,那么这个MRF就称为CRF(Conditional Random Field)。它的条件分布形式完全类似于MRF的分布形式,只不过多了一个观察集合X=(x1, x2,…, xn),即
条件随机场可以看成是一个无向图模型或马尔可夫随机场,它是一种用来标记和切分序列化数据的统计模型。
理论上,图G的结构可以任意,但实际上,在构造模型时,CRFs采用了最简单和最重要的一阶链式结构。
一阶链式CRF示意图(不同于隐马尔科夫链,条件随机场中的xi 除了依赖于当前状态,还可能与其他状态有关)
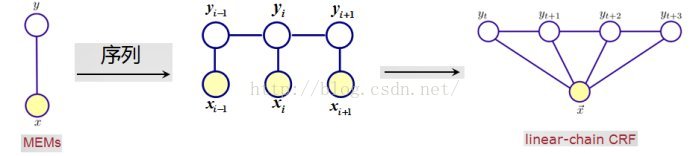
令 X=(x1, x2,…, xn)表示观察序列, Y=(y1, y2,…, yn)是有限状态的集合。根据随机场的基本理论,无向图中关于顶点的标记条件概率
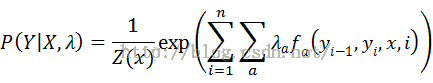
其中归一化因子
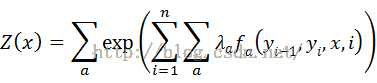
以上的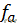
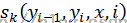
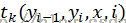
几种比较
条件随机场和隐马尔科夫链的关系和比较
条件随机场是隐马尔科夫链的一种扩展。
- 不同点:观察值xi不单纯地依赖于当前状态yi,可能还与前后状态有关;
- 相同点:条件随机场保留了状态序列的马尔科夫链属性——状态序列中的某一个状态只与之前的状态有关,而与其他状态无关。(比如句法分析中的句子成分)
MRF和CRF的关系和比较
条件随机场和马尔科夫随机场很相似,但又说不同,很容易弄混淆。最通用角度来看,CRF本质上是给定了观察值 (observations)集合的MRF。
在图像处理中,MRF的密度概率 p(x=labels, y=image) 是一些随机变量定义在团上的函数因子分解。而CRF是根据特征产生的一个特殊MRF。因此一个MRF是由图和参数(可以无数个)定义的,如果这些参数是输入图像的一个函数(比如特征函数),则我们就拥有了一个CRF。
图像去噪处理中,P(去噪像素|所有像素)是一个CRF,而P(所有像素)是一个MRF。
1.2.3 如何应用PGM
- 拥有噪音数据或者不确定性比较大的时候
- 拥有很多先验知识的时候,要比普通的机器学习有效
- 多个变量的推理,特别是多个变量之间存在内在联系
- 从较小的模块化的模型中建立复杂的模型,疾病诊断或者错误诊断
概率图模型能够发现和分析复杂分布的结构,提取原本非结构化的数据,使得这些分布能够被有效地重构和利用。
1.3 杂项
学习途径:http://deeplearning.net/reading-list/
吴恩达:http://cs.stanford.edu/people/ang/
http://ufldl.stanford.edu/wiki/index.php/UFLDL教程
http://cloudacademy.com/blog/aws-machine-learning/
http://www.huxiu.com/article/109035
参考:http://blog.csdn.net/tiandijun/article/details/40261895
http://www.ruanyifeng.com/blog/2011/08/bayesian_inference_part_one.html














 2658
2658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









