







Storm能处理高频数据和大规模数据的实时流计算解决方案将被应用于实时搜索,高频交易和社交网络上。而流计算并
不是最近的热点,金融机构的交易系统正是一个典型的流计算处理系统,它对系统的实时性和一致性有很高要求。
与Hadoop比较:
数据来源:HADOOP是HDFS上某个文件夹下的可能是成TB的数据,STORM是实时新增的某一笔数据;
处理过程:HADOOP是分MAP阶段到REDUCE阶段,STORM是由用户定义处理流程,流程中可以包含多个步骤,每个步骤可以是数据源(SPOUT)或处理逻辑(BOLT);
是否结束:HADOOP最后是要结束的,STORM是没有结束状态,到最后一步时,就停在那,直到有新数据进入时再从头开始;
处理速度:HADOOP是以处理HDFS上大量数据为目的,速度慢,STORM是只要处理新增的某一笔数据即可,可以做到很快;
适用场景:HADOOP是在要处理一批数据时用的,不讲究时效性,要处理就提交一个JOB,STORM是要处理某一新增数据时用的,要讲时效性;
Storm的设计思想:
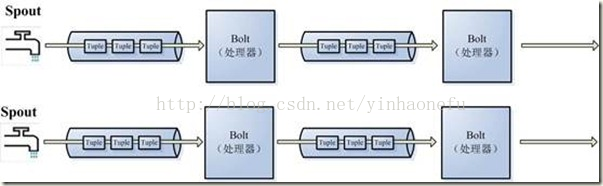
在Storm是对流Stream的抽象,流是一个不间断的无界的连续tuple,注意Storm在建模事件流时,把流中的事件抽象
为tuple即元组。
Storm将流中元素抽象为Tuple,一个tuple就是一个值列表value list,list中的每个value都有一个name,并且该value
可以是基本类型,字符类型,字节数组等,当然也可以是其他可序列化的类型。
Storm认为每个stream都有一个stream源,也就是原始元组的源头,所以它将这个源头称为Spout。
有了源头即spout也就是有了stream,那么该如何处理stream内的tuple呢。将流的状态转换称为Bolt,bolt可以消费任
意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的
spout(管口)再将spout中流出的tuple导向特定的bolt,又bolt对导入的流做处理后再导向其他bolt或者目的地。
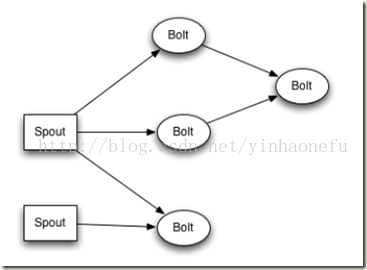
以上处理过程统称为Topology即拓扑。拓扑是storm中最高层次的一个抽象概念,它可以被提交到storm集群执行,一
个拓扑就是一个流转换图,图中每个节点是一个spout或者bolt,图中的边表示bolt订阅了哪些流,当spout或者bolt发
送元组到流时,它就发送元组到每个订阅了该流的bolt(这就意味着不需要我们手工拉管道,只要预先订阅,spout就
会将流发到适当bolt上)。
拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
单机下单词计数示例:
<span style="font-size:18px;">public class WordCountTopology {
public static void main(String[] args) {
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("1", new MySourceSpout());//綁定自定义spout
topologyBuilder.setBolt("2", new SplitBolt()).shuffleGrouping("1");//绑定自定义bolt,在id为1的任务之后执行
topologyBuilder.setBolt("3", new CountBolt()).shuffleGrouping("2");//绑定自定义bolt,在id为2的任务之后执行
//本地集群
LocalCluster localCluster = new LocalCluster();
Map<String,String> config = new HashMap<String,String>();
localCluster.submitTopology(WordCountTopology.class.getSimpleName(), config, topologyBuilder.createTopology());
}
}
class MySourceSpout extends BaseRichSpout{
/**
*
*/
private static final long serialVersionUID = 1L;
private TopologyContext context = null;
private SpoutOutputCollector collector = null;
private Map conf = null;
//永不停止,一直监听,然后处理数据
public void nextTuple() {
//读取目标文件夹中新产生的文件
//遍历F://text目录下后缀是txt的文件,true代表也遍历子目录
Collection<File> files = FileUtils.listFiles(new File("F:\\text"), new String[]{"txt"}, true);
try {
//解析每一行数据
for (File file : files) {
List<String> readLines = FileUtils.readLines(file);
//把每一行数据发射给bolt
for (String line : readLines) {
this.collector.emit(new Values(line));
}
FileUtils.moveFile(file, new File(file.getAbsolutePath() + System.currentTimeMillis()));
}
TimeUnit.SECONDS.sleep(1);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//本实例运行时,首先被调用
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
this.conf = conf;
}
//告诉下一个bolt输出的字段
public void declareOutputFields(OutputFieldsDeclarer declarer) {
Fields fields = new Fields("line");
declarer.declare(fields);
}
}
class SplitBolt extends BaseRichBolt{
private TopologyContext context = null;
private OutputCollector collector = null;
private Map conf = null;
public void execute(Tuple tuple) {
System.out.println("SplitBolt execute");
//读取tuple
String line = tuple.getStringByField("line");
//拆分每一行数据,得到一个个单词
String[] words = line.split("\t");
//把每个单词发射给下一个bolt
for (String word : words) {
this.collector.emit(new Values(word));
}
}
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.context = context;
this.collector = collector;
this.conf = conf;
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
Fields fields = new Fields("word");
declarer.declare(fields);
}
}
class CountBolt extends BaseRichBolt{
private TopologyContext context = null;
private OutputCollector collector = null;
private Map conf = null;
//保存单词出现次数
private Map<String,Integer> wordMap = new HashMap<String,Integer>();
public void execute(Tuple tuple) {
//读取tuple
String word = tuple.getStringByField("word");
//对每个单词计数
Integer value = wordMap.get(word);
if(value == null){
value = 0;
}
value++;
wordMap.put(word, value);
System.out.println("=========================================");
//把统计结果写出去
for (Entry<String, Integer> entry : wordMap.entrySet()) {
System.out.println(entry);
}
}
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.context = context;
this.collector = collector;
this.conf = conf;
}
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
}</span>Storm集群搭建:
Storm集群表面类似Hadoop集群。但在Hadoop上你运行的是”MapReduce jobs”,在Storm上你运行的
是”topologies”。”Jobs”和”topologies”是大不同的,一个关键不同是一个MapReduce的Job最终会结束,而一个
topology永远处理消息(或直到你kill它)。
Storm集群有两种节点:控制(master)节点和工作者(worker)节点。
控制节点运行一个称之为”Nimbus”的后台程序,它类似于Haddop的”JobTracker”。Nimbus负责在集群范围内分发代
码、为worker分配任务和故障监测。
每个工作者节点运行一个称之”Supervisor”的后台程序。Supervisor监听分配给它所在机器的工作,基于Nimbus分配
给它的事情来决定启动或停止工作者进程。每个worker进程执行一个topology的子集(也就是一个子拓扑结构);一
个运行中的topology由许多跨多个机器的工作者进程组成。
Storm集群搭建步骤详见:http://blog.csdn.net/yinhaonefu/article/details/42616593
集群启动之后可以将自己的程序打成jar包上传到storm集群中,执行storm jar jar包位置 main函数所在类的包名类名
storm jar /usr/local/storm/test/jar.jar storm.ClusterStormTopology
上传之前topology的提交方式需要在代码里改为集群而不是本地模式:
public static void main(String[] args) throws Exception {
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("1", new MyClusterSourceSpout());//綁定自定义spout
topologyBuilder.setBolt("2", new ClusterSplitBolt()).shuffleGrouping("1");//绑定自定义bolt,在id为1的任务之后执行
topologyBuilder.setBolt("3", new ClusterCountBolt()).shuffleGrouping("2");//绑定自定义bolt,在id为2的任务之后执行
//分布式集群
Config config = new Config();
StormSubmitter.submitTopology(ClusterStormTopology.class.getSimpleName(), config, topologyBuilder.createTopology());
}成功上传后可以在UI界面http://hadoop1:8080/看到Topology信息
如果想删掉以前上传的jar 可以执行storm kill ClusterStormTopology
(ClusterStormTopology是UI界面上Topology的name)
Storm通过UI查看日志:
在每个storm节点上执行storm logviewer >/dev/null 2>&1 &
通过http://hostname:8000/查看
命令说明:
>/dev/null 日志写到/dev/null中
2>&1 控制台日志到垃圾箱中
& 后台运行
进入zookeeper中查看storm下的supervisor数量 执行zkCli.sh 然后 ls /storm/supervisors
Storm并行度:
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1
个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台
物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的
task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序
调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用
该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该
component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实
例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情
况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
总体来说,Storm并行度的四个范畴:supervisor(节点)-worker(进程)-executor(线程)-task(实例)
并行度配置:
1.supervisor数量,也就是集群从节点数量
2.worker进程数量,可以在storm.yaml中配置。supervisor.slots.ports项配置的是worker进程的端口,端口数量决定
worker进程数量。也可以通过config.setNumWorkers设置。
3.executor线程数量可以在java api中设置。TopologyBuilder在setSpout或setBolt时最后一个参数可以指定开启线程数量。
4.在setSpout或setBolt时再调用setNumTasks,可以设置对应的spout或bolt启动几个task实例。
默认情况下,每个supervisor会启动4个worker进程,每个worker进程启动1个executor线程,每个executor线程会启
动1个task实例。
storm rebalance 命令优化调整storm运行。storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
理解下图:
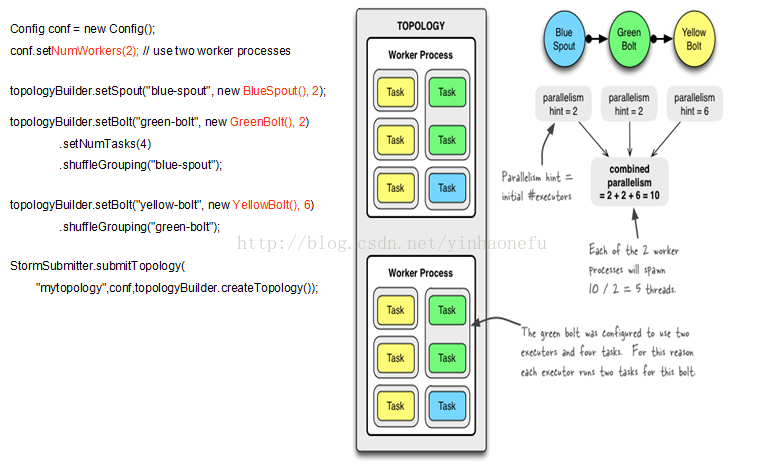
整个topology设置为两个worker运行,蓝色的spout设置为两个executor执行。绿色的bolt也设置为两个executor,但是两个executor中设置启动四个task。黄色的bolt设置为六个executor。
worker内部消息通信

conf.put(Config.TOPOLOGY_RECEIVER_BUFFER_SIZE, 8);
conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 32);
conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384);
conf.put(Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE, 16384);
worker调优选项,可在工作中适当调整。
stream grouping 分类
1.Shuffle Grouping: 随机分组, 随机派发stream里面的tuple, 保证每个bolt接收到的tuple数目相同.
2.Fields Grouping:按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts, 而不同的userid则会被分配到不同的Bolts.
3.All Grouping: 广播发送, 对于每一个tuple, 所有的Bolts都会收到.
4.Global Grouping: 全局分组,这个tuple被分配到storm中的一个bolt的其中一个task.再具体一点就是分配给id值最低
的那个task.
5.Non Grouping: 不分组,意思是说stream不关心到底谁会收到它的tuple.目前他和Shuffle grouping是一样的效果,有
点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程去执行.
6.Direct Grouping: 直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者由消息接收者的哪个
task处理这个消息.只有被声明为Direct Stream的消息流可以声明这种分组方法.而且这种消息tuple必须使用emitDirect
方法来发射.消息处理者可以通过TopologyContext来或者处理它的消息的taskid (OutputCollector.emit方法也会返回
taskid)
Storm的可靠性
spout向bolt发送tuple时,为了保证数据传输的完整性,Storn提供了验证机制。当bolt接收数据时发生异常,可以调用
this.collector.fail(tuple);方法通知tuple本次tuple接受失败,这时spout中的fail方法同时会被调用,可以重写该方法重新
发送该tuple。同样,bolt中执行this.collector.ack(tuple);方法时,代表正常接收,向spout反馈接收成功,这时spout中
的ack方法会被调用,可以重写该方法实现自己的逻辑,例如记录成功接收日志等。
Storm中的事务
1.ack/fail tuple级别的控制,粒度过于细。事务处理的时间过长
2.batch 一个批次一个批次处理。但是如果某个batch处理时间很长,后面的bolt会等待,不能满足高的并行度。
3.在2的基础上进行改进,类似各batch有自己的事务编号,同时发送到各bolt中执行,执行的过程中杂乱无序,但是
最后所有执行完的batch是按原始事务编号顺序发送出去。
Storm框架--trident
http://storm.apache.org/documentation/Trident-tutorial.html














 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









