










 本文深入探讨了Multi-Paxos算法的工作原理,包括选主与保持、正式工作过程及重选和数据恢复等内容,旨在解决分布式系统中数据一致性问题。
本文深入探讨了Multi-Paxos算法的工作原理,包括选主与保持、正式工作过程及重选和数据恢复等内容,旨在解决分布式系统中数据一致性问题。
(接上文《架构设计:系统存储(24)——数据一致性与Paxos算法(中)》)
2-3. Paxos算法变种
上文(架构设计:系统存储(24)——数据一致性与Paxos算法(中))我们提到,Paxos算法的设计是为了解决多个Proposer针对一个具体提案产生的多个赋值,并最终帮助多个Proposer确定一个大家一致认可的赋值,最终达到一致性。从理论层面上说,如果多个Proposer一直不产生竞争起来,那么算法研究就没有意义。例如上文中提到的一个Proposer A的投票轮次编号始终从1000开始,其它Proposer的投票轮次编号始终从100开始,那样的话Paxos算法系统中其它Proposer发起的提案申请在第一轮就会被拒绝(在Proposer A的第一次提案申请到达Acceptor之前,可能会有其它Proposer发起的提案进入第二轮,但最终也会被大多数Acceptor决绝),所以这样的Proposer编号设定实际上就会让所有Proposer都听命于Proposer A的提案决断。
可是从实际应用的角度出发,却刚好相反——让Paxos算法过程尽可能少的产生竞争有利于提高算法效率。在Basic-Paxos算法中,任何一个提案要被通过都至少需要和单独的Acceptor通讯两次(这里还不考虑多Proposer抢占的问题),如果有N个Acceptor则至少进行 (N/2 + 1)× 2次网络通讯。如果在一个完整的Paxos算法中,网络通讯占去了相当的时间,那么Paxos算法的性能自然不会好。所以Paxos算法会产生了很多变种形式。本节我们就对一些主要的变种形式进行说明
2-4. Paxos变种:Multi-Paxos算法
介绍Basic-Paxos时我们只针对了一个议题形成多数派达成一致的值的算法过程进行了说明,无论有多个Proposer参与了抢占Acceptor赋值权的过程,无论为了形成这个多数派决议发起了多少轮Prepare投票申请,也无论Acceptor拒绝了多少次Acceptor赋值请求。所有这一切都只是为了处理一个议题,如:关于K的赋值是多少、关于你爸的名字是A还是B、关于下一次事件触发时间是在1000秒以后还是2000秒以后。
但实际业务场景往往不是这样的,在分布式存储环境中,拥有Paxos算法功能的整个系统需要在生命周期内对多种议题进行一致性处理,例如日志编号X的操作是将编号K的值赋为A还是赋为B;下一个日志编号X+1的操作,是将K的值赋为Y还是赋为W……
为了将Basic-Paxos算法用于实际应用中,Basic-Paxos算法有一种变种算法叫做Multi-Paxos,其中的“Multi”当然就代表在Paxos算法系统存活的整个生命周期需要处理的多个提案。Multi-Paxos算法的工作过程大致可以概括为选主保持、正式工作、重选恢复,本节我们就和大家一起讨论一下Multi-Paxos算法这几个工作步骤。
2-4-1. Multi-Paxos:选主与保持
Multi-Paxos算法核心过程的工作原则和Basic-Paxos算法核心工作原则是相同的,即多数派决定、Acceptor第一轮只接受更大的投票编号、Acceptor第二轮只接受和目前第一轮授权相同的投票编号。但是为了提高对每一个议题的判定效率,Multi-Paxos算法在第一投票过程中做了一个调整:首先通过一个完整的Paxos算法过程完成一次选主操作,从多个Proposer中选出一个Proposer Leader,待所有Proposer都确认这个Proposer Leader后,后续的带有业务性质的提案,都只由这个Proposer Leader发起和赋值。这样的做法至少有两个好处:
其它Proposer在确定自己不是Proposer Leader后,就不再发起任何提案的投票申请,而只是接受Learner(最终结果学习者)传来的针对某个提案的最终赋值结果。而往往Learner和Proposer都存在于同一个进程中,所以这基本上消除了这些Proposer的网络负载。
一旦Proposer Leader被选出,且后续的提案只由它发起和赋值。那么就不存在投票申请冲突的情况了——因为没有任何其它的Proposer和它形成竞争关系。Acceptor所接受的投票轮次编号也都由它提出,那么这些后续提案的第一阶段都可以跳过,而直接进入提案的赋值阶段。这样类似Basic-Paxos算法中要确定一个提案的赋值至少需要和每个Acceptor都通讯两次的情况就被削减成了只需要一次通讯。
请注意,Multi-Paxos算法的选主过程和上一篇文章(架构设计:系统存储(24)——数据一致性与Paxos算法(中))我们提到的直接决定一个起始投票编号最大的Proposer方式的本质区别是:前者是投票决定的,而后者是被固定的,一旦后者那个投票编号最大的Proposer宕机了,其它Proposer在提案投票过程中就会一直出现冲突。另外,由于多个Proposer中并没有Leader的概念,所以这些Proposer就算提案投票申请被拒,也会不停的再发起新一轮投票申请,而这样并不会减少网络通信压力。
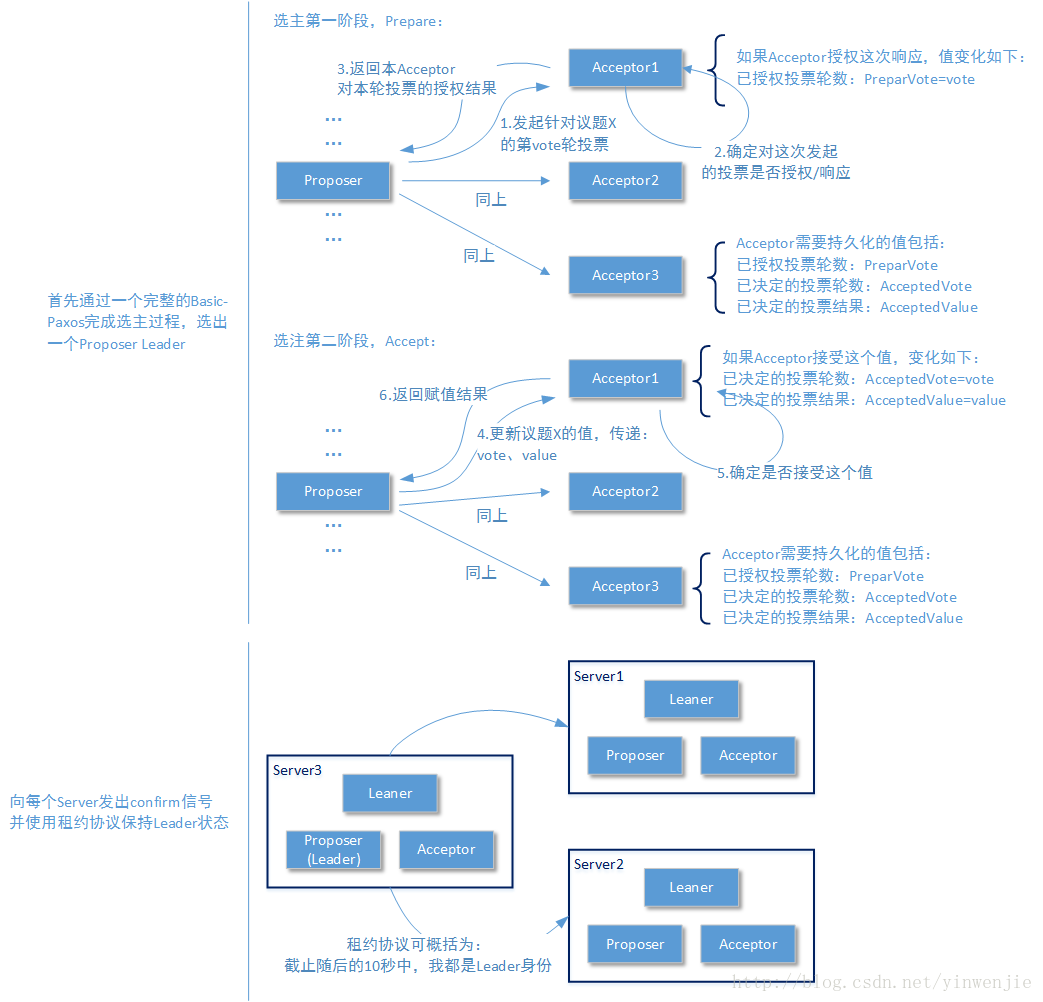
要说明整个Multi-Paxos算法的可行性,就需要明确一个事实。当我们介绍Basic-Paxos算法时,为了读者能够腾出所有精力缕清它的工作步骤,所以将Paxos算法中的Proposer、Acceptor、Leaner等角色分开介绍。但实际情况是,分布式系统中的每个节点都同时具备这几种角色,例如工作在Server 1节点的Acceptor角色能够实时知晓这个节点上Proposer角色的工作状态;Proposer角色也实时知晓同一节点上Leaner角色对提案最终结果的学习状态。这也是为什么我们讨论Paxos算法时经常会将属于Leaner角色的部分公论讨论到Proposer角色中去的原因。
回到Multi-Paxos算法的选主过程来,这个过程就是一个完整的Basic-Paxos过程,这里就不再赘述了。主要需要说明的是保持方式,其它Proposer角色可以从Basic-Paxos过程了解到“已经选出一个Proposer Leader”这个事实,但是并不能知晓这个Proposer Leader仍然是“工作正常的”。所以一旦Proposer Leader被选出,它就会向所有其它Proposer发出一个“Start Working”指令,明确通知其它Proposer节点,自己开始正常工作了,并且在后续的工作中定时更新自己在各个Proposer节点上的租约时间(本文不介绍租约协议,有兴趣的读者可以自行查找该协议的介绍,这里可以简单理解为心跳)。
2-4-2. Multi-Paxos:正式工作过程
为了说清楚Multi-Paxos对多个业务提案的赋值投票过程,我们举一个连续进行日志写入的业务场景,这里每一条日志都有一个唯一且全局递增的log id——实际上一条日志就对应了一个提案即一个Paxos instance,提案内容就是“针对log id为X的日志,完成日志内容的持久化记录”。
这里有读者会问,这个唯一的log id是怎么被确认的呢?这个问题在Multi-Paxos中就很简单了,因为整个系统中只有一个Proposer Leader能进行提案的投票申请和赋值操作,所以这个来自于外部客户端的log id完全可以由Proposer Leader赋予一个唯一的Paxos instance id,并作为内部存取顺序的依据。如果这个log id来源于分布式系统内部那么这个问题就更简单了,直接由Proposer Leader赋予一个唯一且递增的log id即可。而后者的场景占大多数——试想一下这个基于Multi-Paxos算法工作的系统本来就是一个分布式存储系统……
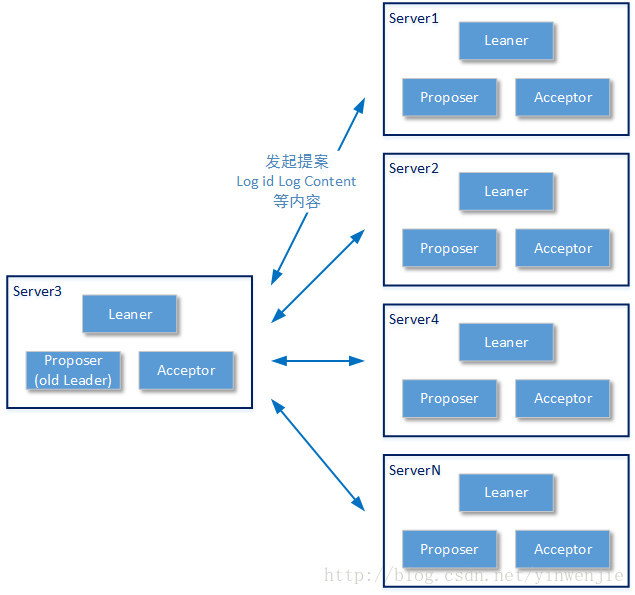
由于Proposer Leader对业务数据的一致性处理跳过了Basic-Paxos算的第一个Prapare阶段,所以对于一条日志Log id,Proposer Leader会直接携带log id(可能还有Paxos instance id)和日志内容,向所有节点发起提案赋值操作。每一个Acceptor在收到赋值请求后,会首先在本地持久化这个日志内容。如果持久化成功,则对这个提案的赋值结果为“完成”,其它任何情况都是“未完成”。
Multi-Paxos的正式工作可以保证一批要进行投票的操作,其序号一定由小到大排列(对于这个日志业务的实例,就是日志的log id一定全局唯一且单调递增)。而且由于只存在一个Proposer Leader能够处理发起投票和赋值操作,所以也避免了操作竞争的问题,这直接导致每一个Paxos instance id都省去了Basic-Paxos的第一阶段,减少了花费在网络上的耗时。但是Multi-Paxos并非没有缺点,最显著的一个问题就是,由于Multi-Paxos中只有一个Proposer在工作,那么当这个Proposer由于任何原因无法在继续工作时怎么办?Multi-Paxos的解决办法是从剩下的Proposer,再重新选择一个Proposer Leader,让整个Multi-Paxos系统继续工作。
话虽简单,但实现起来却并不容易,这也是Multi-Paxos算法的难点所在。为什么呢?我们首先应该思考一下当原有的Proposer Leader宕机时,整个系统的可能处在什么样的状态,如下图所示:
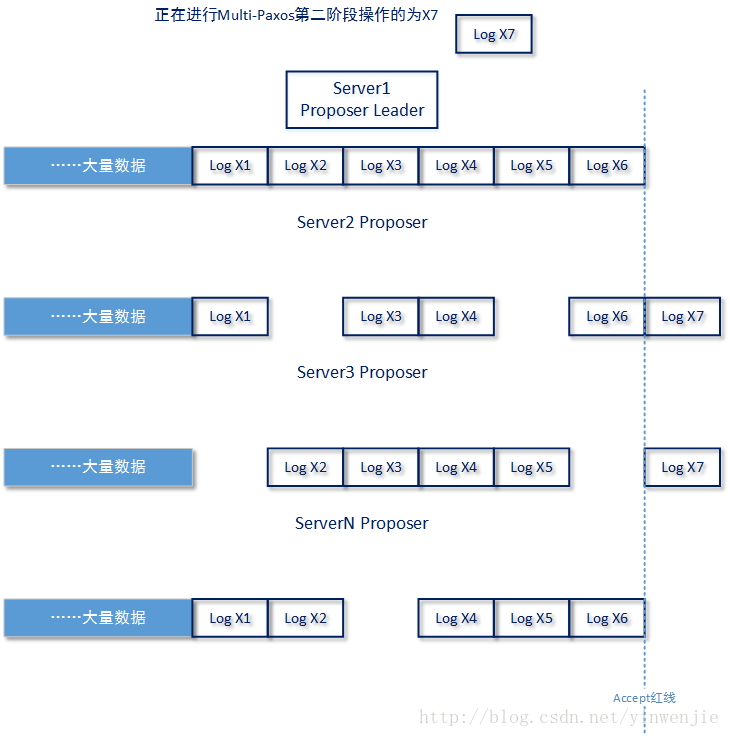
(宕机前夜)
首先由于Paxos算法的多数派原理,所以除了当前Proposer Leader(后文称为old leader)所在Server节点上的Log数据是完整的以外,整个系统不能保证任何一个其它Proposer所在Server节点上的Log数据是完整的。既然Log数据不完整,那么怎么做数据恢复呢?
分布式系统的一般要力争 7 × 24小时不间断工作,也就是说即使整个系统连续工作1周时间,积累的LOG数据也是非常庞大的,10GB、100GB、1TB、10TB甚至更庞大的日志数据规模都有可能。
当old leader宕机时,唯一可以确认的一件事情是:当前通过Multi-Paxos第二阶段操作,并持久化存储在Proposer Leader上的每一条日志数据,在整个Paxos算法算法系统中,至少存在N/2 + 1的多数派份额。在Proposer Leader宕机后,多数派需要达到的数量变成了(N - 1) / 2 + 1.
最后,如上图所示Proposer Leader正在对log id为X7的数据进行Multi-Paxos第二阶段操作,且还没有拿到多数派确认。那么这样的数据在另一个Proposer Leader拿到控制权后,是恢复呢还是不恢复呢?
所谓重新恢复一个Proposer Leader(后文件称new leader),要达到的目的可不是简单的重新选举一个就行了。而是要让这个new leader尽量恢复到old leader宕机时的工作状态,当Client查询第X条日志信息时,new leader能够给出正确的值,而不是向Client回复not found或者错误的值。所以要保证new leader能够接替old leader继续工作,在old leader存活期和new leader恢复阶段,它们至少要做以下工作:确认赋值、确保old leader真正下线、重选leader和恢复数据。
2-4-3. Multi-Paxos:确认赋值过程(confirm)
确认赋值过程的目的主要是帮助Paxos系统在恢复阶段尽可能少做无用功,其做法是按照一定规则周期性的批量的发送Proposer Leader上log id的confirm信息。
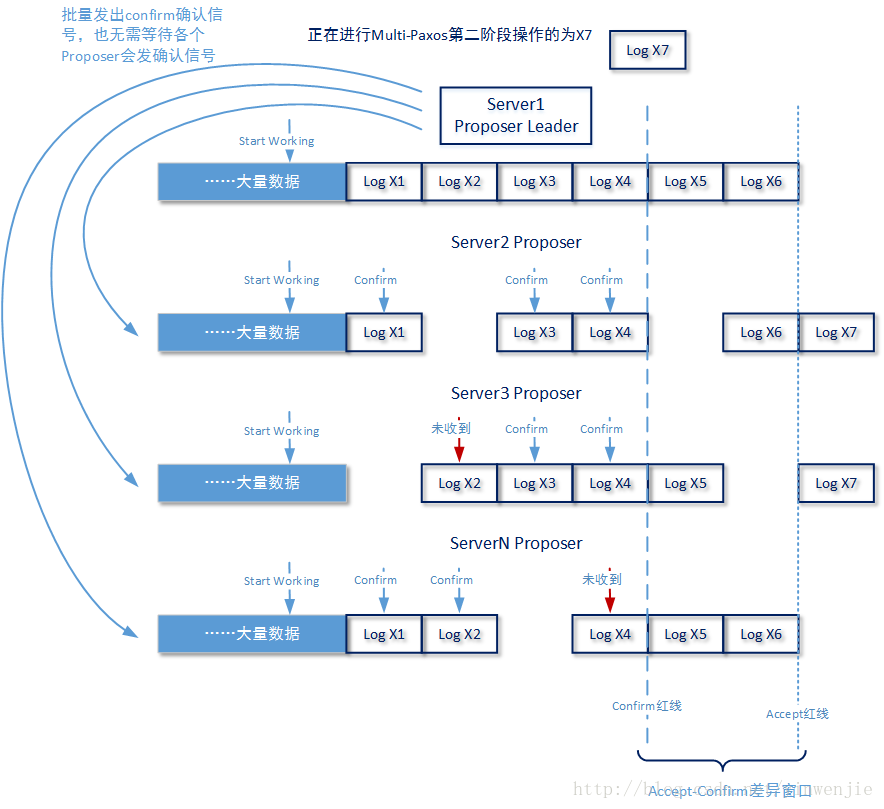
如上图所示,所谓log id的confirm信息是指满足这样条件的log id信息,这个log id通过进行Multi-Paxos的第二阶段操作后,已经得到了大多数Acceptor的赋值确认,并且已经在Proposer Leader完成了持久化存储的log id。confirm信息还可以是乱序,甚至还可以是跳跃的。而且Proposer Leader发送一批og id的confirm信息后,也无需等待Proposer都回发确认信息,甚至可以设定Proposer成本身就不回发确认信息。
Proposer在收到这些confirm信息后,会检查(会可以不检查)log id confirm信息所对应的log id是否存在,如果存在则将这个log id confirm信息进行持久化保存;如果不存在也可以进行log id confirm信息的持久化保存(只是那样做没有意义),所以才会有“可以不预先检查”的说明。为什么要这样做,我们在后续4-4-5介绍数据恢复的小节会进行说明。
2-4-4. Multi-Paxos:确认下线
请考虑这样一个问题:当分布式系统中A节点收不到B节点“工作正常”的信息时,是A节点下线了,还是B节点下线了?答案是根本说不清楚,可能B节点还在正常工作,A节点收不到信息只是由于暂时的网络抖动;由于分布式系统存在分区隔离的问题,虽然A节点收不到B节点“工作正常”的信息,但是整个系统中还可能有大部分节点能够收到这样的信息,所以都不会认为B节点下线了;最后,也可能B节点真的已经下线。
在分布式系统中,对于节点X(既是本文一直在讨论的Proposer Leader节点)是否下线了这个问题很明显不是一个节点能够决定的,而最好是由多数派节点投票确认。在节点X被认定下线的时候,整个分布式系统至少需要保证两件事:
多数派认为节点X下线了:这个原因已经在上一段落进行了描述,这里就不再赘述了。
原来的节点X真的下线了:这是因为如果原有的节点X没有下线,在新的节点X1接替它工作后,就可能出现两个节点都在完成相同的工作职责,而它们接受到的传入数据又可能不完全一致,最终影响数据的一致性。要解决这个问题,只需要在各个节点实现租约协议。当节点X无法向多数派节点续租时即认为自己下线,这时即使自己工作是正常的,也会强制自己停止服务。
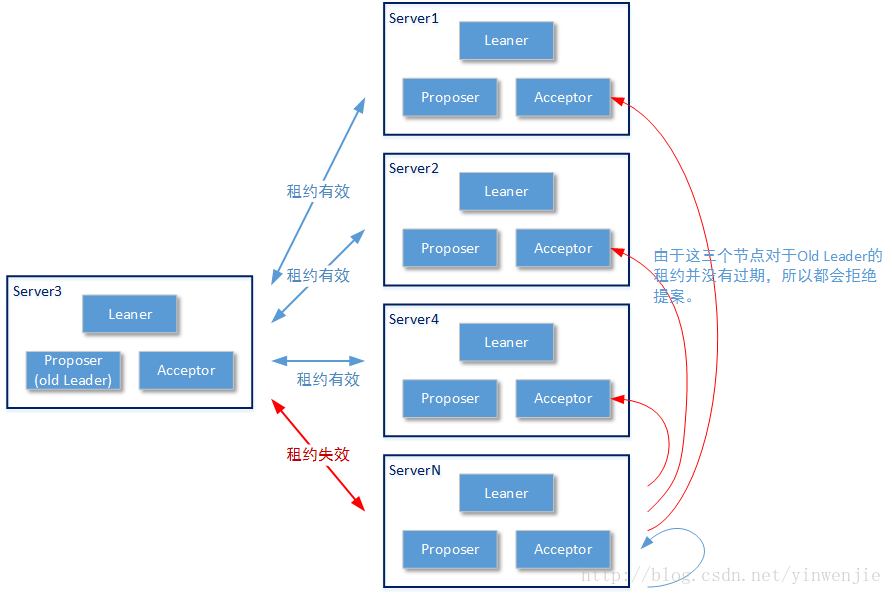
如上图所示,当节点Server N上关于Old Proposer Leader的租约信息过期后,Server N会发起一轮新的议题,议题内容为“Old Proposer Leader已经下线”。分布式系统中的其它节点在收到这个议题后,会检查自己和Old Proposer Leader的租约是否过期,如果没有过期,则可以在Basic-Paxos算法的第一阶段拒绝授权或者在Basic-Paxos算法的第二阶段拒绝赋值
当节点Server N关于“Old Proposer Leader已经下线”的议题通过,确确实实知晓不是由于自身的原因误认为“Old Proposer Leader已经下线”后,才会开始重新选主过程。这里有一个细节,当Server N的议题“Old Proposer Leader已经下线”通过后,Old Proposer Leader也会真实离线。这是因为在Old Proposer Leader上和多数派节点的租约都已经过期,即使Old Proposer Leader工作是正常的,也会强制自己停止服务。
需要注意的是,确认下线这个过程实际上并不是Multi-Paxos算法所独有的,而是所有分布式系统需要具备的功能。确认下线这个过程也并不是一定要使用Basic-Paxos算法进行,其原则是保证多数派确认下线和Old Proposer Leader确实下线这个事实。由于Multi-Paxos算法的特点,在正式工作时只能有一个Proposer Leader,所以在进行Proposer Leader重选前就必须确保原有的Proposer Leader真实下线。
2-4-5. Multi-Paxos:重选和数据恢复
重新选主的过程实际上和2-4-1小节描述的选主过程是一致的,甚至为了简化工作过程也可以将重新选主的提议和确认下线的提议合并在一起。重选步骤的关键并不在于如何选主,而在于如何恢复数据——因为Multi-Paxos的工作过程,我们不能保证任何一个Server节点上拥有完整的数据,所以一个New Proposer Leader在开始工作前就需要对数据完整性进行检查,对缺失的数据进行恢复,这样才能保证客户端在查询第Y条日志数据时,New Proposer Leader会返回正确的查询结果,而不是返回Not Found!下图展示了一种New Proposer Leader被选出后,整个Paxos集群所处理的数据状态
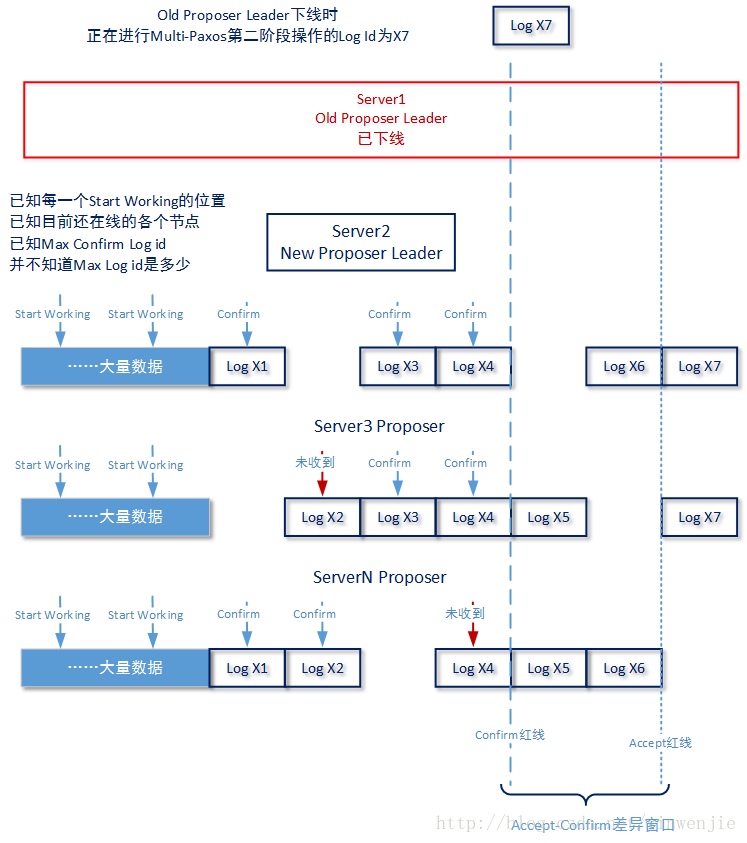
好消息是在Old Proposer Leader工作阶段,已经向潜在的成为新主的多个Proposer节点写入了不少的信息。例如,在Old Proposer Leader正式工作开始之前,会向其它Proposer节点写入一个start work的位置,记录前者开始工作时所用的log id的开始编号位置,经历了多少次Proposer Leader选主确认过程,就会有多个start work位置。例如一个月前由于Old Proposer Leader宕机,进行了一次选主,上周5由于Old Proposer Leader宕机又进行了一次选主。期间工作的各个Proposer上就会有两个start work位置。新加入的节点和恢复正常工作的历史节点,也应在加入/重新加入分布式环境时同步这些start work位置。
在Proposer Leader工作工程中,直接使用Basic-Paxos算法的第二阶段进行log id和内容的赋值操作,所以每一条操作成功的log内容都会记录在多个Proposer节点上,且这些节点的数量是多数派。最后,Proposer Leader工作过程中还会批量发送confirm信息,告知所有Proposer节点,哪些log id的内容已经得到了多数派确认。
所以在New Proposer Leader被选出,且开始进行数据恢复前。这个New Proposer Leader至少知道三类信息:一个或者多个Old Proposer Leader的strat working的位置、目前还在线的节点以及在Old Proposer Leader上已经得到多数派确认的若干log id信息。但是New Proposer Leader并不知道全局最大的log id,虽然在New Proposer Leader节点上会有一个max log id,但它并不知道后者是不是就是全局最大的log id。原因是之前Old Proposer Leader下线时,正在等待多数派确认的那个log id还没有得到多数派赋值确认又或者虽然多数派确认了但Old Proposer Leader本身还没有拿到响应信息,而New Proposer Leader自己并不清楚自己是否属于多数派。
数据恢复的原理说起来很简单,既是从数据恢复的开始点,到数据恢复的结束点,将本节点缺失的数据补全。那么问题来了:数据恢复的起点在哪?数据恢复的结束点在哪?哪些数据需要补全?数据来源在哪里?又应该如何进行补全?
数据恢复的开始点很好确定,即是还没有开始恢复的第一个start work位置所对应的log id。
数据恢复的结束点稍微麻烦一点,需要发起一轮Paxos投票来确认由多数派认可的那么全局最大的log id。不过,由于这时整个系统中已经确认了一个唯一的Proposer Leader,所以不存在投票冲突的问题,可以直接进行Basic-Poxos的第二阶段。
从数据恢复的起点到终点,每一条log数据都需要进行一次完整的Basic-Poxos操作用以确保恢复的数据是历史上以形成多数派的正确数据,最终目的是为了保证数据最终一致性。但是之前已存在于New Proposer Leader上,且被标记为confirm的log数据则无需进行这样的操作了,因为Old c已经在之前确定了这些数据是正确的。这样就大量减少了需要恢复的数据规模,加快了数据恢复过程。
注意,如果在数据恢复过程中,某一条Log id无法形成多数派决议,则这条数据就是在Old Proposer Leader中还没有被确认的数据,这样的数据不能进行恢复。即使在New Proposer Leader上有这条记录,如果没有形成多数派决议也不能使用,否则就会出现一些的错误。请看如下所示的极端例子:
==================================
(接后文)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











