




 本文深入解析了关系数据库的工作原理,包括日志管理、预写日志系统(WAL)、ARIES算法等内容。介绍了如何通过事务日志确保数据的完整性和一致性,以及在数据库崩溃后如何利用日志进行数据恢复。
本文深入解析了关系数据库的工作原理,包括日志管理、预写日志系统(WAL)、ARIES算法等内容。介绍了如何通过事务日志确保数据的完整性和一致性,以及在数据库崩溃后如何利用日志进行数据恢复。
本文翻译自Coding-Geek文章:《 How does a relational database work》。
原文链接:http://coding-geek.com/how-databases-work/#Buffer-Replacement_strategies
紧接上一篇文章,本文翻译了如下章节:
<
一、 Log manager(日志管理)
通过前面的章节,我们已经知道,为了提升性能,数据库会将数据缓存在内存中。但是,如果在事务提交过程中,数据库服务器崩溃了。缓存在内存的数据就会丢失,这破坏了数据库的Durability特性。
也可以把所有数据都直接写到存储磁盘,万一在写的过程中服务器崩溃了,就只有一部分数据写到了磁盘。这也破坏了事务的Atomicity特性。
事务的完整性要求要么所有操作都执行,要么什么也不做。
有两种方式达到这样的目的:
Shadow copies/pages(影像拷贝/影像页面): 每个事务拷贝一份自己的数据库(或者是数据库的一部分),在这份拷贝上操作。出错了,就删除这份拷贝。成功后,使用文件系统的功能 做一下文件交换,替换掉旧的数据。
Transaction log (事务日志):Transaction log是这样一块存储区域–在事务将数据写到磁盘之前先将信息写到Transaction log文件。这样,如果服务发生崩溃、事务被取消;数据库清楚如果根据日志删除数据,或者继续完成未完成的操作。
二、 WAL(Write Ahead logging 预写日志系统)
在大型数据库上存在众多事务,Shadow copies/pages 需要消耗大量的磁盘空间。这也是现代数据库都使用 Transaction Log的原因。Transaction Log必须存储在可靠的位置。我不打算深入介绍存储技术,我假设使用的RAID盘是可靠的。
大多数据库(Oracle、SQL Server、DB2、PostgreSQL、MySQL和SQLite)处理Transaction Log是用的WAL协议。本协议包含三条规则:
- 每一次数据库的修改操作都产生一条日志记录。并且日志信息一定要在数据写到磁盘之前先写到事务日志文件中。
- 事务日志必须按顺序存储。操作A先于操作B执行,那么操作A的日志必须先写。
- 事务提交时,提交命令必须在事务结束之前写到Transaction Log文件中。
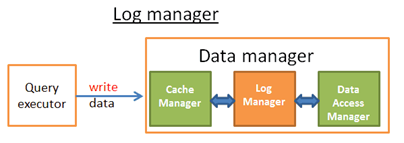
上面这些规则由Log Manager保证。一种简单的理解:在Cache manager与Data Acccess Manager增加一层Log Manager,Log Manager将每一次操作(包含update/delete/create/commit/rollback)都先写到Transaction Log,再将数据写到磁盘。足够简单不?
错!,我们已经看过的所有,与数据库相关的东西都受到了“诅咒”– 数据库性能(Database effect)。 更麻烦的问题是 如何找到一种写Transaction Log的高效方式。如果写Transaction log很慢,它将拖所有数据库操作的后腿。
三、 ARIES (IBM数据恢复的原型算法)
在1992年,IBM研究中心“发明”了增强版的WAL叫ARIES。现代数据库都或多或少 用到了ARIES算法。实现逻辑或许不同,但背后的原理都是ARIES。我之所以在“说明”上面加引号,是因为根据MIT思维、IBMS研究中心并没有开发出一种更好的数据恢复软件。停留在理论。
“我5岁的时候,ARIES算法就已经发布”,我不在意这种少数苦逼研发人员的八卦。实际上我把这个作为一个中场休息,在开始最后一段技术章节之前的中场休息。我已阅读了大量关于ARIES的文档,我发现它很有趣。在这,我只给你们讲一下ARIES的大概含义。如果你想了解ARIES的详细的信息,我建议读一下相关的论文。
AREIS的意思是“Algorithms for Recovery and Isolation Exploiting Semantics”。
ARIES的目的旨在两个方面:
- 提升写Transaction Log的性能。
- 拥有快速、可靠的恢复能力。
有多种原因会导致数据库事务回滚:
- 用户取消了。
- 服务器崩溃或者网络中断。
- 事务操作违反了数据库的约束条件(例如:某个字段要求数据唯一,而事务插入了重复的数据)。
- 出现了死锁。
有时(比如网络出现故障),数据库可以恢复事务。它是如何做到的呢? 要回答这个问题,我们需要理解日志中记录了哪些信息。
四、 The Logs
事务中的任何操作都会产生日志,包括添加、删除、修改。一条日志由如下信息构成:
1. LSN:Log Sequence Number, 日志记录的唯一编号。LSN按时间顺序生成。这意味着,如果操作A在操作B之前执行,那么A的LSN编码将小于B。
2. TransID:事务ID。记录当前操作所属的事务。
3. PageID:分页ID,记录修改数据在磁盘上存储的位置。分页是数据在磁盘上存储的最小单位,所以数据在磁盘上的存储位置即指包含该数据的分页在磁盘上的位置。
4. PreLSN:同一个事务中的上一条日志。
5. UNDO:回滚操作。
例如,对于数据修改操作。UNDO将存储修改操作的值或者状态,在正式修改磁盘上的数据之前。回滚时执行反向操作回到前一个状态。
6. REDO:重操作。
有两种方式实现可实现REDO,存储操作的值和状态,或者操作自身。REDO时重执行操作。
7. …仅供参考:ARIES日志还要另外两个字段:UndoNxtLSN 和 Type。
此外,存储数据的磁盘分页上还存储了最后一次修改该分页数据的LSN。
备注:根据我的了解,只有PostgreSQL不使用UNDO。它有一个垃圾回收线程,用于清除旧版本数据。这是PostgreSQL的data version的一种应用场景。
这里给一个简单示例,“UPDATE FROM PERSON SET AGE = 18;”修改生成的日志记录。
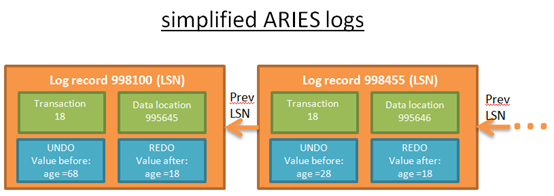
每一条日志都有唯一的LSN。同一个事务中所有日志构成链表结构,链表中日志按时间先后顺序排列。
五、 Log Buffer
为避免写日志成为性能瓶颈,Log Buffer派上用场。
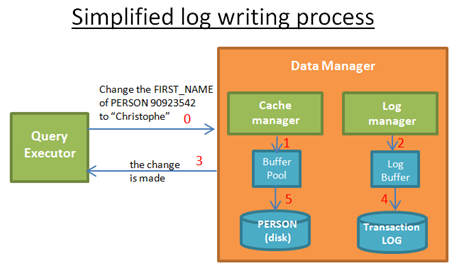
当query excutor执行一次数据库修改操作时:
- Cache manager保存修改后的数据到缓存区。
- Log manager保存相关的日志信息到缓存区。
- 到这一步,Query Excutor任务修改操作已经完成。可以接收下一次操作请求。
- 然后,Log manager将日志信息写到transaction log。决定什么时候写日志有一个算法。
- 然后, Cache manager将数据写到磁盘。决定什么时候写数据到磁盘也有一个算法。
当一个事务提交成功了,就意味为事务中的所有操作都已经完成了上面1~5步操作。写事务日志是非常快的,因为只需要把事务日志信息加到日志文件的末尾。反之,写数据到磁盘上要复杂得多,写数据的时候要考虑怎么快速读取(译者注:作者的意思应该是说,为了提升读取性能,数据库都会有索引。写数据将涉及到存储索引B+树的调整。时间很长,算法很复杂。)
六、 STEAL and FORCE policies (窃取和强制策略)
为了提升性能,上面的第5步(将数据写到磁盘)可能会被放在事务提交后再执行,因为即使万一出现了什么问题,也能通过事务日志的REDO来恢复。这种方式被称为NO-FORCE Policy。
数据库也可以选择 Force Policy(第5步必须在事务提交前完成),以降低数据库恢复的负担。
另一个问题是选择采用一步一步往磁盘上写数据的方式(STEAL Policy)还是等事务提交时,一次性将缓存的数据写到磁盘的方式(NO-STEAL Policy)。选择哪种方式,取决于应用场景:快速的写,但需要采用UNDO日志缓慢的恢复,或者快速恢复。
不同的策略对数据恢复有哪些影响:
- STEAL/NO-FORCE需要UNDO和REDO:性能最好,也带来更复杂的日志设计和恢复处理(如ARIES)。大多数数据库都采用这种方式。
- STEAL/ FORCE:仅需要 UNDO能力。
- NO-STEAL/NO-FORCE:仅需要REDO能力。
- NO-STEAL/FORCE:什么也不需要,性能最差。需要大量内存。
七、 The recovery part
OK,我们已经构建出了完美的数据库日志,下来看应该如何使用它。
假如,一个实习生把数据库搞挂了。你重启了数据库,然后数据库恢复工作就开始了。
ARIES使数据库从崩溃中恢复有三个步骤:
1. The Analysis pass (分析阶段):恢复程序读取所有的事务日志,重建灾难发生时现场环境。以决定哪些事务需要回滚,哪些数据需要写到磁盘。
2. The Redo pass (重做阶段):这个阶段根据分析的日志,执行REDO操作更新数据库,使数据库回到灾难前的状态。
在REDO阶段,REDO日志按时间顺序先后执行(根据LSN)。针对每一条日志,恢复程序将从磁盘包含数据的分页中读取LSN。
IF(磁盘分页上的LSN) >= IF(事务日志中LSN):这意味着数据在发生灾难前已经写到了磁盘上(并且,数据被后面(发生灾难前)执行的操作覆盖)。针对这条操作日志什么也不用做。
F(磁盘分页上的LSN) < IF(事务日志中LSN):说明磁盘上的数据被修改。将执行REDO操作,写数据库。哪怕后面事务又回滚了(这样是为了使恢复程序简单化,现代数据库是不会这么处理的)。
3. The Undo pass:这个阶段将回滚在灾难发生时未完成的事务。回滚操作从事务的最后一条日志开始,按时间从后往前的方式执行Undo操作(通过日志的PreLSN往前遍历)。
在数据恢复过程中,事务日志作为恢复程序执行任务的依据,以保证数据写到磁盘顺序与事务日志记录顺序同步。应该有一种方案可以移除事务中未完成操作相关的日志,但这很困难。相反,ARIES采用添加修正日志的方式,以达到理论上删除事务中未完成操作的目的。
当某个事务被取消了,取消的原因可能是用户取消,Lock manager取消(防止死锁)或者因为网络中断的原因。出现这些情况不需要考虑通过日志恢复。实际上,关于如何REDO和UNDO的信息已经存储在两张内存表中:
事务表-transaction table(存储当前正在执行的所有事务状态)。
脏页表-dirty page table(存储哪一块数据需要写到磁盘)。
每来一个新的事务,这两张表将被cache manager和transaction manager更新。由于这两张表是存储在内存中的,数据库崩溃时数据就丢失了。
使用 transaction log做数据库故障恢复, 在分析阶段要做的事情就是重建这两张表。为了加快分析阶段处理,ARIES创造了检查点(CheckPoint)的概念。其思路是,不时将transaction table和dirty page table写到磁盘,并且将当时的最后一条LSN写到磁盘;这样,在分析阶段就只有该LSN后面的日志需要分析。
八、 To Conclude 最后一句话
在写下这边文章之前,我已经知道这个主题很大,写深入 要花很多时间。实际证明,我还是过于乐观了,我花了预期两倍的时间。在这个过程中也学到很多东西。
如果你想更深入的了解数据库,我建议你研读一下论文“Architecture of a Database System”。这是一篇介绍数据库很好的文章,非计算机专业人士也能看得懂。这篇论文帮助我规划本文要写的内容,这是一篇关于架构理念的文章,不像本文,本文主要描述数据结构和算法。
如果你仔细阅读了本文,你就了解了数据库是多么强大。由于文章很长,再梳理一下重点内容。
- B+树索引概述
- 数据库整体概述
- 数据表连接操作性能优化概述
- 缓存池管理
- 事务管理
实际数据库能力更加强大,例如:我还未介绍数据库是如何解决这些更麻烦的问题的:
- 数据库集群和全局事务
- 数据在运行过程中如何创建快照
- 高效数据压缩
- 内存管理
因此,当你需要在充满BUG的NO SQL和坚如磐石的关系型数据库之前选择时,慎重思考。不要误解我的意思,一些NO SQL数据库也很伟大。但是,他们还太嫩,而且只关注解决很少的一部分特定问题。
总之,当有人问你关系型数据库是如何工作的时,你不必撒腿跑路,现在你能回答这个问题了。

或者,你也可以直接把这篇文档丢给他。


















 2986
2986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









