







第四章
1、对现有普通表进行分区
2、对现有分区表进行添加一个分区
3、对现有分区表进行删除一个分区
4、对现有分区表进行修改分区
5、把现有分区表改回原普通表
----------------------------------------华丽的分割线-----------------------------------------
1、对现有普通表表进行分区
创建普通表a,为表a添加数据,代码如下:
--创建数据库表a
if object_id('[a]') is not null drop table [a]
go
create table [a]
(
[ID] int,
[品名] varchar(6),
[入库数量] int,
[入库时间] datetime
CONSTRAINT [PK_a] PRIMARY KEY CLUSTERED --创建主键
(
[Id] ASC
)
)
--为表a添加测试数据
insert [a]
select 1,'矿泉水',100,'2014-01-02' union all
select 2,'方便面',60,'2014-01-03' union all
select 3,'方便面',50,'2014-01-03' union all
select 4,'矿泉水',80,'2014-01-04' union all
select 5,'方便面',60,'2014-01-05' union all
select 6,'方便面',50,'2014-01-06' union all
select 7,'矿泉水',80,'2014-01-06' union all
select 8,'方便面',60,'2014-01-07' union all
select 9,'方便面',50,'2014-01-09' union all
select 10,'矿泉水',80,'2014-01-11'
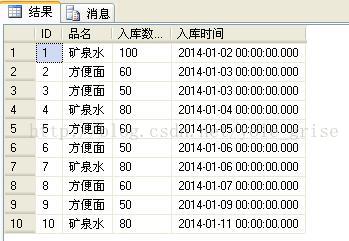
select * from a
查询结果如图1所示
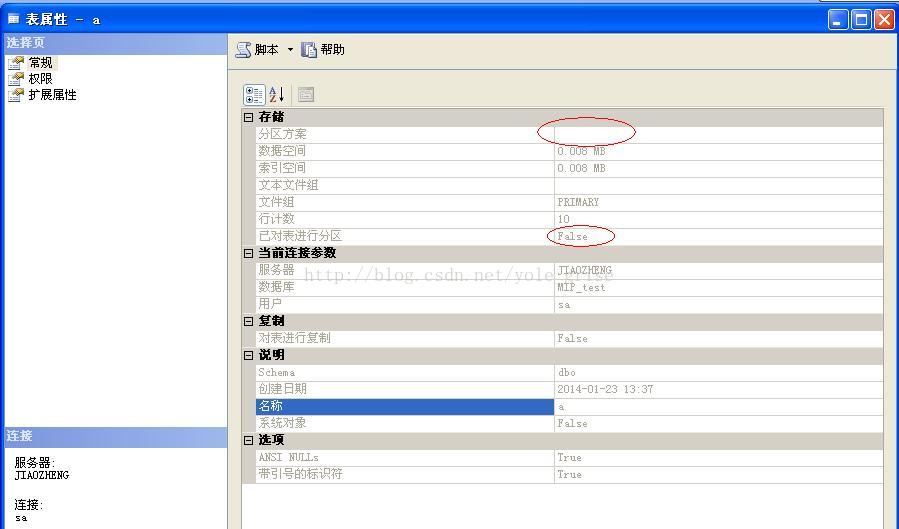
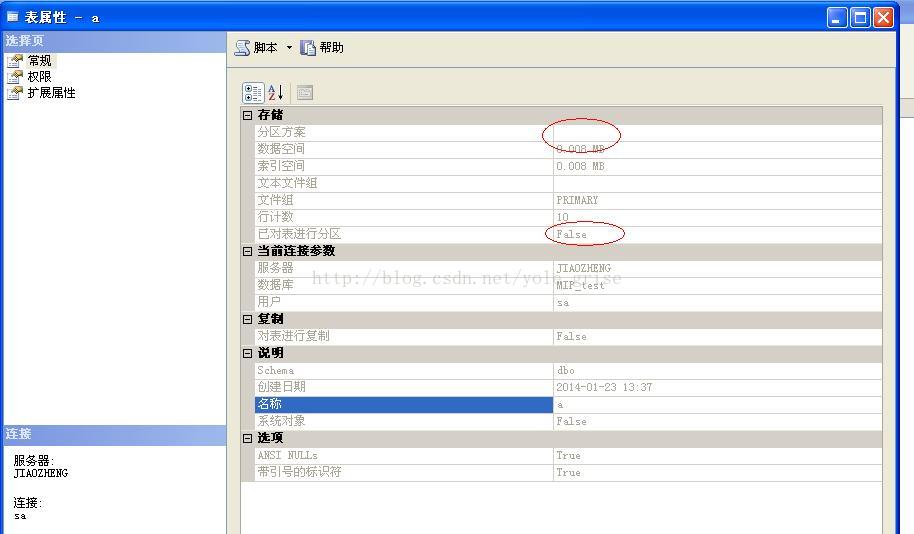
右键表a属性查看,如图2所示,表a为普通表,并未分区。
下面是为表a进行分区:
①、删除表a主键(聚集索引)
②、创建一个新的聚集索引,在此聚集索引中使用分区方案
③、创建主键,只能设定为非聚集索引
【这里是参考代码:第一章 分区函数 和 分区方案 代码】
代码如下:
--删除主键(聚集索引)
ALTER TABLE a DROP constraint PK_a
--创建一个新的聚集索引,在该聚集索引中使用分区方案
create CLUSTERED INDEX PK_a ON a([id])
ON partschA([id])
--创建主键,但不设为聚集索引
ALTER TABLE a ADD CONSTRAINT PK_a1 PRIMARY KEY NONCLUSTERED
(
[ID] ASC
) ON [PRIMARY]
查看表a,如图3所示:
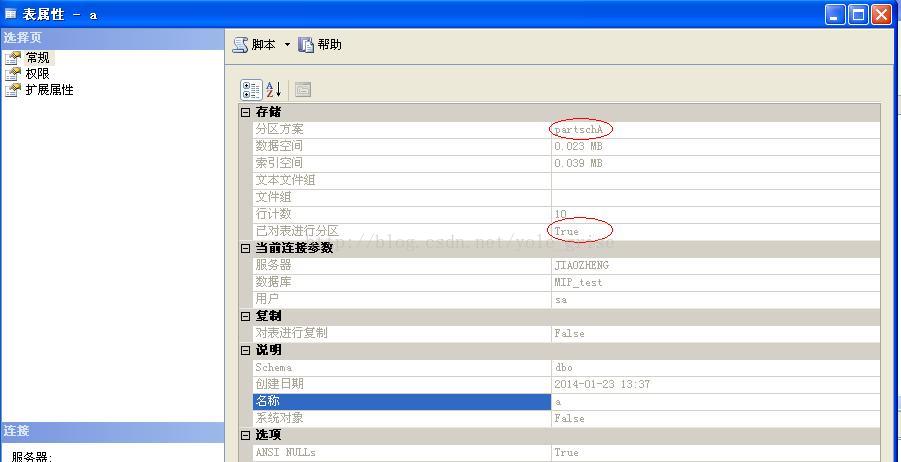
表a现在是分区表了。
----------------------------------------华丽的分割线-----------------------------------------
首先来看一下分区表a的分区方案和分区函数,代码如下:
--创建分区函数(分成三个区,1区小于等于3的、2区大于3小于等于6的、3区大于6的)
CREATE PARTITION FUNCTION partfunA (int)
AS RANGE LEFT FOR VALUES (3,6)
--创建分区方案(将已分区的数据放在主文件里,三个区都放在主文件里)
CREATE PARTITION SCHEME partschA
AS PARTITION partfunA
TO ([Primary],[Primary],[Primary])
①、修改分区方案,指定下一个分区的文件组
②、修改分区函数
代码如下:
--修改分区方案,指定下一个分区的文件组为[Primary]
ALTER PARTITION SCHEME partschA
NEXT USED [Primary]
--修改分区函数,修改后为4个区(1区小于等于3的、2区大于3小于等于6的、3区大于6小于等于8的、4区大于8的)
ALTER PARTITION FUNCTION partfunA()
SPLIT RANGE (8) 注释:
①、 NEXT USED [Primary]:指定下一个分区的文件组为[Primary]
②、SPLIT RANGE (8) :类似于开始创建时的
CREATE PARTITION FUNCTION partfunA (int)
AS RANGE LEFT FOR VALUES (3,6,8)
修改后为4个区(1区小于等于3的、2区大于3小于等于6的、3区大于6小于等于8的、4区大于8的)
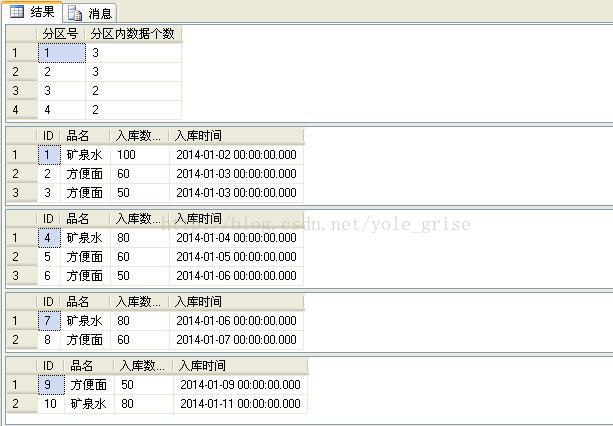
查看分区及分区数据:
代码如下:
--查看分区
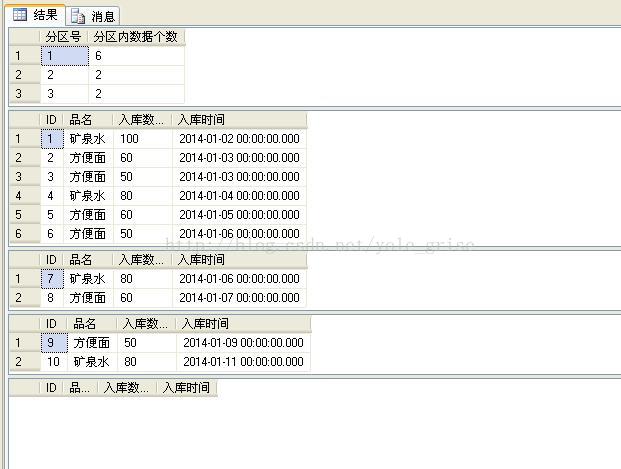
select $partition.partfunA(id) as '分区号',count(*) as '分区内数据个数'
from a group by $partition.partfunA(id)
--查看各分区数据
select * from a where $partition.partfunA(id)=1
select * from a where $partition.partfunA(id)=2
select * from a where $partition.partfunA(id)=3
select * from a where $partition.partfunA(id)=4
----------------------------------------华丽的分割线-----------------------------------------
3、对现有分区表进行删除一个分区
修改分区函数,代码如下:
--删除一个分区(即剩下3个分区,1区小于等于6的、2区大于6小于等于8的、3区大于8的)
ALTER PARTITION FUNCTION partfunA()
MERGE RANGE (3)
查看分区及分区数据:
代码如下:
--查看分区
select $partition.partfunA(id) as '分区号',count(*) as '分区内数据个数'
from a group by $partition.partfunA(id)
--查看各分区数据
select * from a where $partition.partfunA(id)=1
select * from a where $partition.partfunA(id)=2
select * from a where $partition.partfunA(id)=3
select * from a where $partition.partfunA(id)=4
如图5所示,表a只剩下3个分区。
----------------------------------------华丽的分割线-----------------------------------------
4、对现有分区表进行修改分区
修改分区,其实就是重复操作2和3,,即删除原有分区再添加新的分区。
----------------------------------------华丽的分割线-----------------------------------------
5、把现有分区表改回原普通表
这里我利用的是聚集索引和表分区冲突的原理,进行的把分区表改成普通表。
①、删除分区索引(因为一个表只能有一个聚集索引,这里分区索引就是聚集索引;所以我们想新建一个聚集索引是做不到的,只能先把分区索引删掉)
②、删除主键(非聚集索引),之前我们在ID上设置了主键,但生成的是非聚集索引。这里我们要在这个主键ID上建立新的聚集索引,所以要先把之前的非聚集索引删掉。
③、重建聚集索引
代码如下:
--删除分区索引
drop index a.PK_a
--删除主键(非聚集索引)
ALTER TABLE a DROP constraint PK_a1
--重建聚集索引
ALTER TABLE a ADD CONSTRAINT PK_a PRIMARY KEY CLUSTERED
(
[ID] ASC
) ON [PRIMARY]
----------------------------------------华丽的分割线-----------------------------------------
折腾的差不多了,我也仅仅是个SQL的爱好者,如有不正确的地方,欢迎批评指正。















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









