







此博客停止更新迁移至SnailDove's Blog,查看本文点击此处
决策树学习
决策树学习通常包含三个方面:特征选择、决策树生成和决策树剪枝。决策树学习思想主要来源于:Quinlan在1986年提出的ID算法、在1993年提出的C4.5算法和Breiman等人在1984年提出的CART算法。
特征选择
为了解释清楚各个数学概念,引入例子
表5.1 贷款申请样本数据表
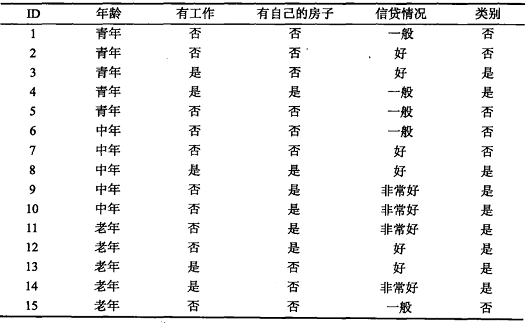
上表有15个样本数据组成的贷款申请训练数据D。数据包括贷款申请人的4个特征:年龄、有工作与否、有房子与否、信贷情况,其中最后一列类别的意思是:是否同意发放贷款,这个就是决策树最后要给出的结论,即目标属性——是否发放贷款,即决策树最末端的叶子节点只分成2类:同意发放贷款与不同意发放贷款。
- 信息熵(entropy)
引入概念,对于第一个要用到的概念:信息熵在另外一篇博客——数据压缩与信息熵中详细解释了信息熵为什么度量的是不确定性,下文也不再赘述,直接引用。
设D为按照目标类别(或称目标属性)对训练数据(即样本数据)进行的划分,则D的信息熵(information entropy)表示为:
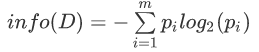
其中pi表示第i个类别在整个训练数据中出现的概率,可以用属于此类别元素的数量除以训练数据(即样本数据)总数量作为估计。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









