







这个系列的文章是一只试图通过产品角度出发去理解复杂庞大搜索引擎的汪写出来的,不足之处很多,欢迎广大技术、非技术同学阅读后指正错误,我们一起探讨共同进步
本章主要讲的是搜索引擎的优化,包括提高搜索效率(云存储、缓存机制)、提高搜索质量(网页去重、用户搜索意图识别、网页反作弊)及搜索的发展方向。这三个方面是在网页抓取&搜索排序的基础上发展起来的。
一、提高搜索效率
1.1云存储
基本假设:存储机由大量廉价pC构成、机器节点故障时常态、水平增量扩展、弱数据一致性、多读少写型服务。
常见的云存储评价标准
CAP(consistency/availability/partitiontolerance):一致性、可用性、区分容忍性。一般来说一个数据系统不可兼得CAP三个要素。
ACID(atomicity/consistency/isolation/durability):原子性、一致性、事物独立、持久性。是关系型数据库采纳的原则。可获得可靠性和强数据一致性。
BASE(basicallyavailable/soft state/eventual consistency):基本可用、柔性状态、最终一致性。云存储大多采用BASE原则,通过牺牲强数据一致性来获得高可用性。
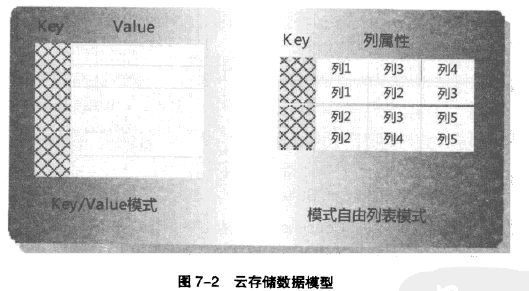
常见数据模型:Kay/value模式和模式自由(schemafree)列表模式。都是由主key和数据值组成,不同的是自由列表模式的数据值由若干列属性组成。云存储数据模型如下:
1.2缓存机制
因为正常搜索计算量大耗时较长,所以建立缓存的主要目的就是提高搜索速度。基本原理就是在高速内存硬件设备内开辟一块数据存储区,用来容纳常见的用户查询及搜索结果,同时采取一定的管理策略来维护存储区内的数据。用户查询时,先到缓存中查找,若有则直接返回搜索结果,否则采取正常搜索流程。好处是快速响应查询请求,且减少搜索引擎后台计算时间。
搜索引擎缓存系统架构如下:
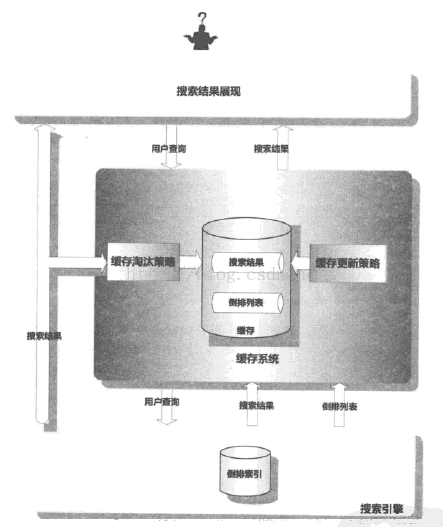
从上图看出,当用户进行查询时,引擎会首先在缓存系统中查找,若存在搜索结果则将缓存内结果展现;若没有结果,则将查询转入正常查询流程,并将该条查询搜索结果及中间数据根据一定的策略调入缓存中,这样下次遇到同样的查询可以直接在缓存中读取。
缓存系统包括缓存存储区和缓存管理策略。缓存管理策略包含两个子系统,缓存淘汰策略和缓存更新策略。优秀的缓存系统希望有两个特质:最大化缓存命中率、缓存内容与索引内容保持一致。
主要说一下缓存淘汰策略(Evict Policy),从宏观角度,可将其分为动态策略和静态动态混合策略。
动态策略思想是对缓存项保留一个权重值,且权重值随查询命中情况动态调整,当出现缓存已满的情况,则优先淘汰权重值最低的缓存项。常见的动态策略包括LRU策略、LandLord策略、SLRU等改进策略。
混合策略的缓存数据一部分来自于在线用户查询一部分来自于搜索日志的历史数据。效果较好的混合策略包括SDC策略和AC策略。
二、提高搜索质量
2.1 网页去重
为什么要网页去重?
互联网页面中有相当大比例的内容是完全相同或大体相近的,保留这些内容会对存储空间、爬虫速度、搜索质量产生影响。实际工作中去除重复网页是在爬虫阶段进行的,若判断为近似重复网页,则直接抛弃,若为全新内容,则将其加入网页索引中。
通用去重算法,简单来说就是抽取文档特征,对特征进一步压缩后生成文档指纹,利用相似性计算判断网页间是否重复。
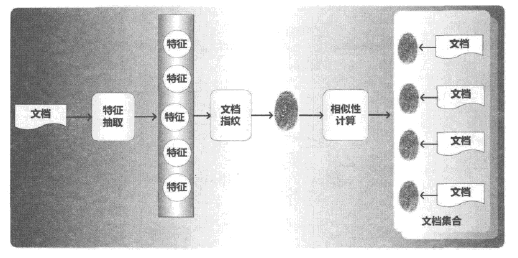
常用去重算法有shingling算法、I-Match算法、SimHash算法、SpotSig算法等(具体算法太复杂没看)。能够快速处理海量数据是搜索引擎对去重算法的内在要求,所以去重算法必须兼顾准确性与运行效率,在两者之间取得平衡。
2.2用户搜索意图识别
同样的搜索query,不同用户的需求也可能不同。搜索意图识别的主要目的就是探究用户查询背后隐藏的搜索意图。常用搜索意图分类有导航型搜索(Navigational)、信息型搜索(informational)、事物型搜索(transactional)。雅虎研究人员在此基础上做了细化,可分为:导航类、信息类(直接型、间接型、建议型、定位型、列表型)、资源型(下载型、娱乐型、交互型、获取型)。
下面介绍几种用户搜索意图识别的方法。
2.2.1搜索日志挖掘
搜索日志是搜索引擎对用户行为的记录,可从中挖掘有价值的数据帮助搜索引擎改善搜索质量。使用前需将查询日志转换为中间数据,常用中间数据包括:查询会话、点击图、查询图。
查询会话(query session):记录用户在短时间内发出的连续多个查询的日志被称为查询会话。这些查询见具有一定语义相关性,能被应用到相关推荐等搜索应用中。
点击图(click graph):用户搜索与点击网址对应构建点击图。这是一种二分图,查询节点与网址节点间的有向边,一般用点击次数作为边的权重。可以从点击图中挖掘出大量语义相关信息。
查询图(query graph):构建查询之间相互关系的数据表示。可以用查询间的重合单词数目、同属会话关系、点击图中共同的点击网址、点击图中网址的链接关系、点击图中页面主题内容相近,来发现查询之间的相似性。
2.2.2相关搜索
相关搜索即查询推荐,向用户推荐与输入查询语义相关的其他查询,引导用户更准确地表达查询需求。常见的推荐方法有基于会话的方法和基于点击图的方法。
基于查询会话的方式就是将搜索日志转化为大量的查询会话,采用关联规则对会话做统计处理,挖掘出相关搜索结果。缺点是会话难以准确切割,难以区分不同用户间的查询关联。
基于点击图的方法思想:若两个查询对应的点击网址中有很大比例相同,则查询可作为相互推荐。
2.2.3查询纠错
自动纠正用户的错误查询,提升搜索结果质量。纠错分为两个步骤,首先调用词典识别错误,然后进行错误纠正。常见的错误纠正方法有两种:编辑距离(Edit Distance)和噪声信道模型(Noise Channel Model)。
2.3网页反作弊
网页作弊主要指通过更改或调控网页内容,使网页在搜索引擎排名中获得与其网页不相称的高排名。常说有白帽、黑帽方法。
作弊方式:关键词重复(影响词频计算)、无关查询词作弊(0词频增加到非0词频)、图片alt标签文本作弊(利用不显示文本提高词频)、网页标题作弊(文不对题)、网页重要标签作弊(html标签插入作弊关键词)、网页元信息作弊(内容描述区和内容关键词区插入作弊关键词)。
作弊意图:增加目标作弊词影响排名;增加主题无关内容或热门查询吸引流量;关键位置插入目标作弊词影响排名。
2.3.1介绍几种常见的作弊方式
链接作弊:考虑搜索引擎使用的链接分析技术,操纵页面间的链接关系或链接锚文字,增加链接排序因子得分,从而影响搜索结果排名。
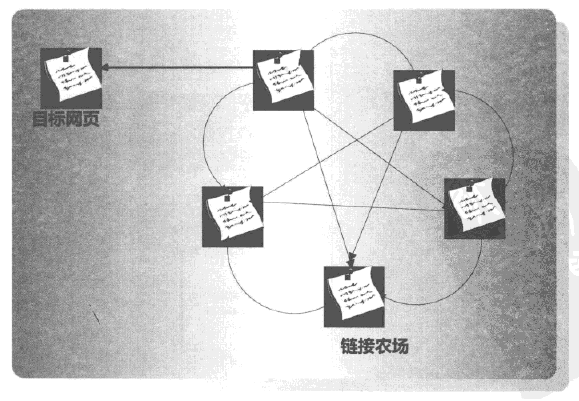
常见作弊方式有链接农场(Link Farm)——构建大量相互紧密链接的网页集合,通过互链来提高排名,如下图所示。Google轰炸(googlebombing):锚文字是指向某个网页的链接描述文字,通过设计锚文字能诱导引擎给予目标网页较高排名;交换友情链接:与其他站点交换链接,增加网页排名;购买链接:花钱让排名较高的网站链接指向自己,提高排名;购买过期域名:刚过期域名本身pagerank排名较高,购买域名可以获得高价值外链;“门页”作弊:由大量链接构成,链接指向同一网站内页面,提升站点排名。
页面隐藏作弊:通过手段使得引擎抓取的页面内容和用户点击查看的内容不同,影响引擎搜索结果。
常见作弊方法有IP地址隐藏作弊:记录搜索引擎爬虫IP地址,发现是搜索则推送伪造网页,如果是其他IP地址,则推送另外的网页;HTTP请求隐形作弊(useragent cloaking):根据http协议区分网络爬虫,推送不同的页面;网页重定向:利用引擎索引某个页面内容,用户访问则重定向到新页面;页面内容隐藏:利用html标签设置,隐藏一些与网页无关的热搜词。
web2.0作弊方法,常见作弊方法有博客作弊:常见的是作弊博客、博客评论作弊和TrackBack作弊;点评作弊:在商品评论里加入无关广告或虚假点评;标签(tag)作弊:标签插入广告内容;Sns作弊:建立虚拟个人描述信息,利用色情等信息引诱用户点击链接或发送群组广告;微博作弊:微博发广告。
2.3.2 反作弊思路
根据以上的作弊思路,常见的反作弊主要有三种思路:信任传播模型、不信任传播模型、异常发现模型。
信任传播模型:通过某种手段筛选出白名单赋予信任度值,利用其余页面与白名单页面的链接关系传递信任值,最后得到的信任度高于一定阈值则认为没问题,否则被认为是作弊网页。
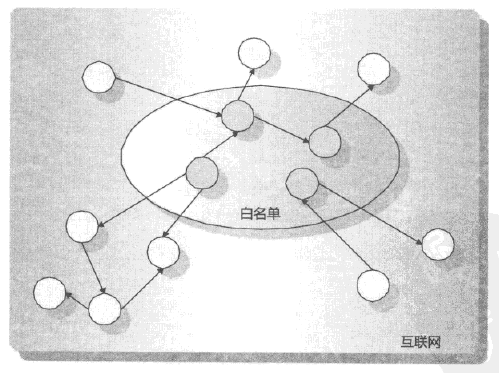
不信任传播模型:可以理解为将信任传播模型中的白名单换成了黑名单,其余基本思路相同。
异常发现模型:找到一些作弊网页集合,分析其异常特征,利用异常特征来识别作弊网页。有两种思路,第一种从作弊网页包含的独特特征来构建算法;第二种则是统计正常网页特征,不具备这种特征即为作弊网页。
常用的链接反作弊方法根据以上思路来有TrustRank算法(信任传播模型)、BadRank算法(不信任传播模型)和SpamRank算法(异常发现模型)。
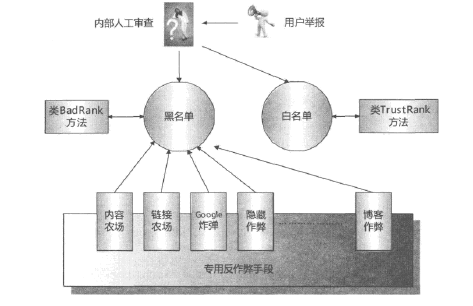
实际上作弊与反作弊是相互抑制相互促进的过程,纯粹靠技术手段无法彻底解决作弊问题,必须将人工手段与技术手段结合才能取得较好的反作弊效果。有效的搜索引擎是个综合系统,融合了人工因素、通用技术手段和专用技术手段。框架如下:
三、搜索发展方向
搜索引擎发展到现阶段有几个主要的发展方向,包括但不限于个性化搜索、社会化搜索、实时搜索、移动搜索、地理位置感知搜索、跨语言搜索、多媒体搜索(图片、音频、视频搜索)、情境搜索等。
社会化搜索:本质是信息过滤和推荐,即对用户的搜索需求,社会化搜索系统推荐合适的人回答疑问,或通过社交关系过滤不可信内容,推荐可信内容。社会化搜索关注的四类关系:直接有社交联系的成员;有相同兴趣的成员;用户所加入网络社区的成员;领域专家。
实时搜索:强调快,即用户发布的信息能够第一时间被搜索引擎发现、索引并搜索到。完整的实时搜索排序算法考虑4个方面的因子:内容相关性、时效性、信息重要性、社交性。
后记:至此,这就是搜索引擎系列就结束了。也有相关技术同学反馈,三篇博文里缺少了很多内容,比如仅关于用户搜索query的处理就包括切词、fuzzy、改写等很多步骤,而博文中并没有展开详细说明。因为这一系列文章本就是个渣产品试图理解复杂而庞大的搜索引擎才写的读书笔记,更多专注于框架部分,具体技术细节可能随着工作经验及学习深入再做补充,欢迎大家一起探讨互相学习。














 1341
1341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









