







最近邻居法(KNN算法,又译K-近邻算法)是ML最简单分类的方法之一。需要分类的样本依据k个最邻近的样本分类。
K的选择:
理论上说如果样本无限多,那么k越大越好。但是这些邻居必须相近。而且,样本怎么可能无限多呢。所以,一般来说
k< sqrt(n)
k=1计算效率高,但是超级会被noise影响
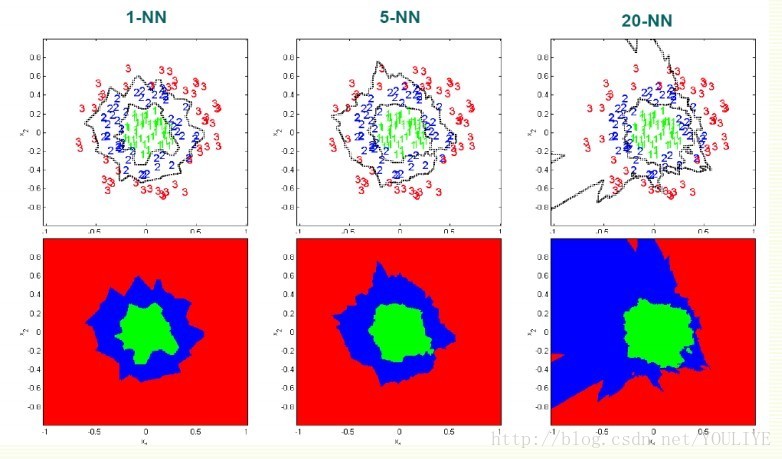
理论上最佳error会是Bayes rate E* (• Bayes error rate 是分类算法最佳最小的error rate),但是要无限样本,所以还是会高于E*。随着k变大,error减小,error = cE*, k越大c越小。就算k =1, 如果样本无限大error rate 也会小于2E*
knn 在样本大的时候效果好。
Euclidian Distance to find the nearest neighbor:
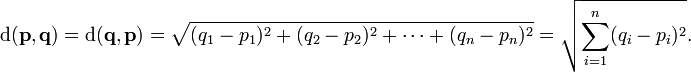
这个算法把每个feature认为一样重要,但是其实有些feature是更有区分力的
极端个例:
feature 1 就是答案: 1 or 2
feature 2 毫不相关的数字100 to 200(scale大)
• dataset:
[1 150]
[2 110]
• classify
[1 100] 会被分到2去。
如果样本密集度高就不容易出现,但是样本往往太过稀疏。
解决方法:normalize features to be on the same scale
1)
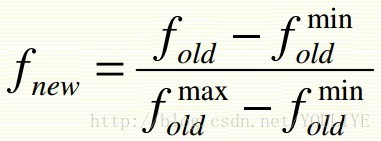
2)
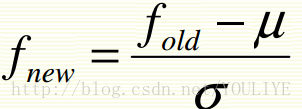
但是如果是高dimension空间,而且大部分features是噪声,那normalization也没救。如果好feature没有废物feature多,那么欧几里得距离会是噪声的天下。所以要考虑feature加权。要么就看背景条件知道哪个feature更重要,要么就cross validation来看。
计算复杂度
基本kNN算法存储全部的examples。假设dimensiond有n个example:
O(d) 计算1个example 的距离
O(nd) 寻找一个nearest neighbor
O(knd) 寻找k个最近examples
所以总的复杂度O(knd) ,如果大样本就很费电脑,但是矛盾的是kNN又需要大样本才能做得好。
两种降低复杂度的办法:
1)删减掉不对边缘做出贡献的那种中心的点点,减少样本量,不改变决策边界
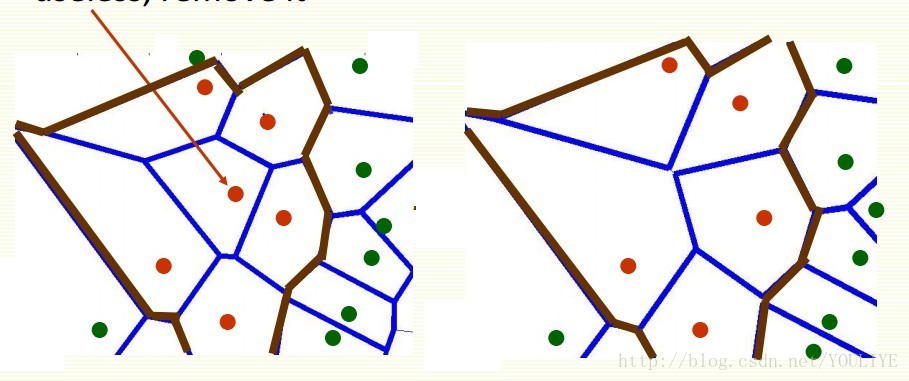
2)部分距离
如果已经有了k个接近的样本,那么算到一半距离就已经比第k个还大,就不用接着算了(这不是废话吗)
好处就是肯定还是能拿到最接近的k个,坏处就是到底能降低多少复杂度全看运气了。
3) 其他
降低数据的dimensionality
使用其他 data structures, 例如kd trees
小结
Advantages
• 可以用于任何分布的数据: 不需要线性可分割
• 简单直观
• 如果样本够大是很好的分类法
Disadvantages
k值选择可能不容易
测试阶段很费电脑
没有训练阶段,全部都在test完成,这样不好是因为我们可以花得起training时间,但是test需要快
• 需要大样本才好














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









