







Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包。
现在最新的lucene已经更新到6.0版本了。但是这个最新版,需要适配jdk1.80以上的版本。
所以我这里用的5.5.1的版本的,它对jdk没有这么高的要求,比较适应开发。下面分三步简单的将lucene的建立索引,搜索,中文分词,介绍给大家。
用到的包:
一,建立索引:
1,定义三个字符串数组,分别对应:id,content,city。
2,写个getWriter(),在里面建立分析器analyzer。
3,通过IndexWriter将目录,将分析器绑定在一起。
4,将字符串数组,写入到文档,再通过有分析器流写出。
通过以上步骤,lucene就会帮我将索引建立好了。
代码:
import java.nio.file.FileSystems;
import java.nio.file.Path;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
public class IndexFile {
protected String[] ids={"1", "2"};
protected String[] content={"Amsterdam has lost of add cancals", "i love add this girl"};
protected String[] city={"Amsterdam", "Venice"};
private Directory dir;
/**
* 初始添加文档
* @throws Exception
*/
@Test
public void init() throws Exception {
String filePath = "F:/1/index";
Path path = FileSystems.getDefault().getPath(filePath);//得到系统文件的路径
dir = FSDirectory.open(path);//通过系统打开目录
IndexWriter writer=getWriter(); //得到写出流
for(int i=0; i < ids.length; i++) {
Document doc=new Document(); //将内容写入文本中
doc.add(new StringField("id", ids[i], Store.YES));
doc.add(new TextField("content", content[i], Store.YES));
doc.add(new StringField("city", city[i], Store.YES));
writer.addDocument(doc); //将文本写出
}
System.out.println("init ok?");
writer.close();
}
/**
* 获得IndexWriter对象
* @return
* @throws Exception
*/
public IndexWriter getWriter() throws Exception {
Analyzer analyzer=new StandardAnalyzer();
IndexWriterConfig iwc=new IndexWriterConfig( analyzer); //加入分析器,建立索引
return new IndexWriter(dir, iwc);
}
}
产生的结果:
二,搜索:
通过上面已经将文件建好了索引,现在我们要做的就是通过这个索引,去搜索对应的内容。
1,找对应的文件夹,打开文件将文件读入
2,将文件加入到搜索器中,指定对应的索引,这里是content中的单词add作为搜索条件。注意设置最大输出结果,search(query, 10)就是这个方法中的数字。
代码:
import java.nio.file.FileSystems;
import java.nio.file.Path;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
public class IndexSearch {
/**
* 查询
*
* @throws Exception
*/
@Test
public void testSearch() throws Exception {
String filePath = "F:/1/index";
Path path = FileSystems.getDefault().getPath(filePath);
Directory dir = FSDirectory.open(path);
IndexReader reader = DirectoryReader.open(dir); //注意这里用的是读入
IndexSearcher searcher = new IndexSearcher(reader);//将目标文件加入搜索器
Term term = new Term("content", "add");//content==》key add===>value
TermQuery query = new TermQuery(term);
TopDocs topdocs = searcher.search(query, 10);//这个数字输出的最多记录数
ScoreDoc[] scoreDocs = topdocs.scoreDocs;
System.out.println("查询结果总数---" + topdocs.totalHits + "---最大的评分--" + topdocs.getMaxScore());
for (int i = 0; i < scoreDocs.length; i++) {
int doc = scoreDocs[i].doc;
Document document = searcher.doc(doc);
System.out.println("content====" + document.get("content"));
System.out.println("id--" + scoreDocs[i].doc + "---scors--" + scoreDocs[i].score + "---index--"
+ scoreDocs[i].shardIndex);
}
reader.close();
}
}
结果展示:

三,中文分词:
lucene自带分词,考虑到中英文分词,这里我们选用的是lucene-analyzers-smartcn-5.5.1.jar包,它能较好的支持中英文分词。
1,定义一段话,含中英文。
2,写入自定义,停用词,所谓停用词,就是lucene在分词时,会自动过滤这些词,不会对其进行分割,直接将其忽略。
3,将这些自定义停用词加入到系统。
4,将文本加入分词器,就会将词分好了。
代码:
import java.util.Iterator;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.util.CharArraySet;
import org.apache.lucene.util.Version;
public class SmartChineseAnalyzerTest {
public static void main(String[] args) {
try {
// 要处理的文本
String text = "lucene分析器使用分词器和过滤器构成一个“管道”,文本在流经这个管道后成为可以进入索引的最小单位,因此,一个标准的分析器有两个部分组成,一个是分词器tokenizer,它用于将文本按照规则切分为一个个可以进入索引的最小单位。另外一个是TokenFilter,它主要作用是对切出来的词进行进一步的处理(如去掉敏感词、英文大小写转换、单复数处理)等。lucene中的Tokenstram方法首先创建一个tokenizer对象处理Reader对象中的流式文本,然后利用TokenFilter对输出流进行过滤处理";
// 自定义停用词
String[] self_stop_words = { "的", "了", "呢", ",", "0", ":", ",", "是", "流" };
CharArraySet cas = new CharArraySet( 0, true);
for (int i = 0; i < self_stop_words.length; i++) {
cas.add(self_stop_words[i]);
}
// 加入系统默认停用词
Iterator<Object> itor = SmartChineseAnalyzer.getDefaultStopSet().iterator();
while (itor.hasNext()) {
cas.add(itor.next());
}
// 中英文混合分词器(其他几个分词器对中文的分析都不行)
SmartChineseAnalyzer sca = new SmartChineseAnalyzer( cas);
TokenStream ts = sca.tokenStream("field", text);
CharTermAttribute ch = ts.addAttribute(CharTermAttribute.class);
ts.reset();
while (ts.incrementToken()) {
System.out.println(ch.toString());
}
ts.end();
ts.close();
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
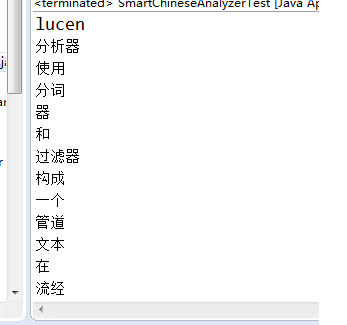
部分结果展示:















 5311
5311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









