






原SQL,执行了6.8小时后报ora-01555错误无法完成:
select t.operid || '|' || sum(score) || '|' ||
nvl((select sum(score)
from cs_score_operdayscore t1
where t1.operid = t.operid
and t1.scoredate > to_date(20120801, 'yyyymmdd')
and t1.scoreid in
(select dictname
from dict_item
where groupid in ('SHOPSCOREEXCHG',
'SCOREEXCHGFEE',
'SCOREEXCHGSELFBUSI',
'SCOREEXCHGSUPPERPRESENT',
'SCOREEXCHGXHNEWS',
'SCOREEXCHGMIFI',
'SCOREEXCHGTEMPPRESENT'))),
0) || '|' ||
nvl((select sum(score)
from cs_score_operdayscore t1
where t1.operid = t.operid
and t1.scoredate > to_date(20120801, 'yyyymmdd')
and t1.scoreid in
(select dictname
from dict_item
where groupid = 'NEWBUSISCORE')),
0)
from cs_score_operdayscore t
where scoredate > to_date(20120801, 'yyyymmdd')
group by operid;
sql monitor采集的执行计划如下:
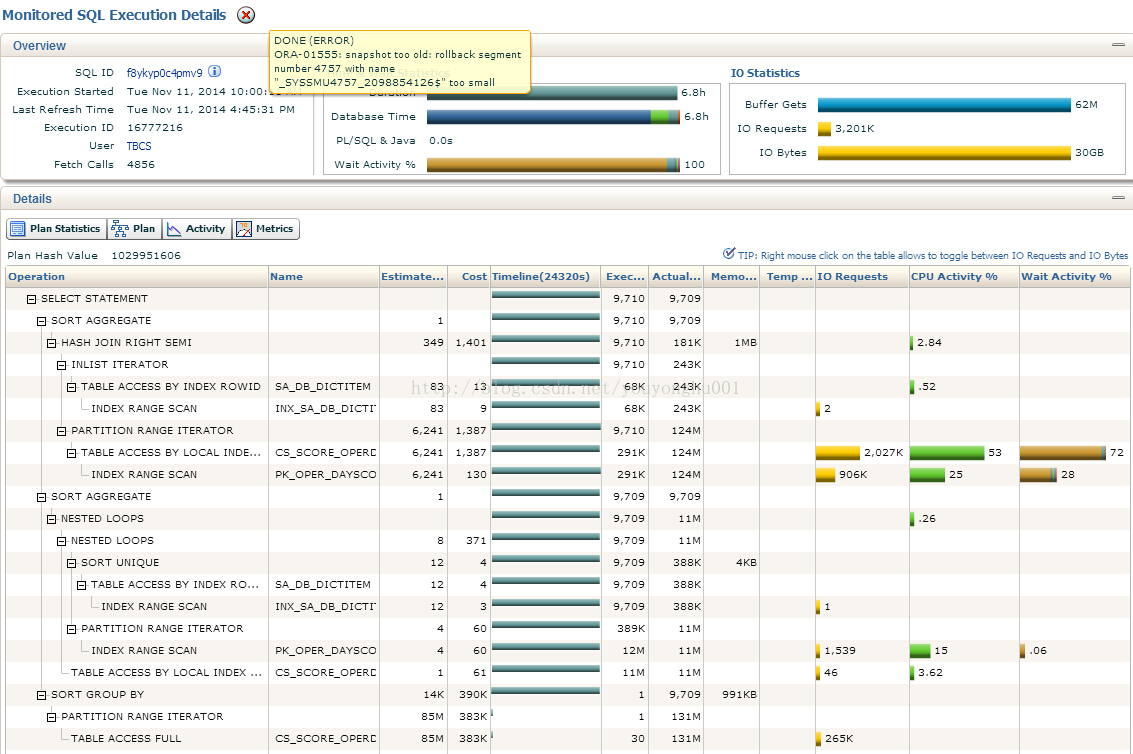
问题:
cs_score_operdayscore是一张大表(1亿条以上),从谓词条件看,将近3年的数据基本上不会过滤掉多少记录,在如此大的一张表上,使用标量子查询(即select 的column列表中使用了select子句),性能是非常非常差的,需要通过外关联的方式进行改写才能提高性能。
而同一张表在标量子查询里面又被用到,这种情况可以使用WITH来进行改写;因为这个SQL是大表做统计分析,一般是DW系统或是OLTP系统晚上操作,为了缩短响应时间和资源消耗,一般建议增加并行操作,最终改写后的SQL如下:
with main as
(select operid,score,scoreid from cs_score_operdayscore where scoredate > to_date(20120801, 'yyyymmdd') )
select /*+ parallel(8) */
t.operid || '|' || sum_t || '|' ||nvl(sum_t1,0) || '|' ||nvl(sum_t2,0) from
(select operid,sum(score) sum_t from main group by operid) t,
(select operid,sum(score) sum_t1 from main where scoreid in
(select /*+ full(dict_item) */dictname
from dict_item
where groupid in ('SHOPSCOREEXCHG',
'SCOREEXCHGFEE',
'SCOREEXCHGSELFBUSI',
'SCOREEXCHGSUPPERPRESENT',
'SCOREEXCHGXHNEWS',
'SCOREEXCHGMIFI',
'SCOREEXCHGTEMPPRESENT')
)group by operid
) t1,
(select operid,sum(score) sum_t2 from main where scoreid in
(select /*+ full(dict_item) */dictname
from dict_item
where groupid = 'NEWBUSISCORE')
group by operid
) t2
where t.operid=t1.operid(+) and
t.operid=t2.operid(+) ;
这个SQL最终的执行时间是4分钟(并行度设置为8),下面是部分执行计划的内容:
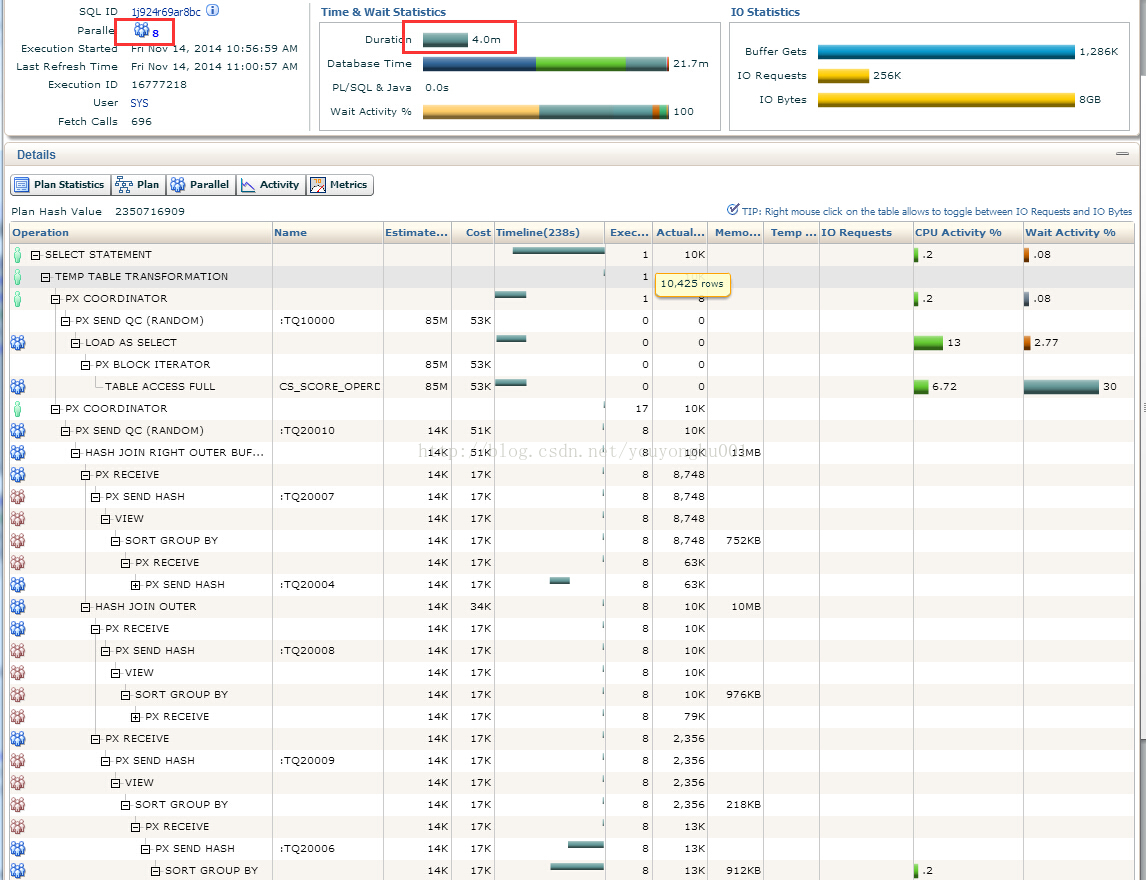














 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









