







1.pos收单流程
从POS机的角度看,一个典型的收单交易流程为:
1. 根据报文格式进行组包,向后台发起交易请求;
2. 后台收到请求后解包进行验证,验证完成后重新组包返回应答报文;
3. POS终端收到应答报文后解包,得到最终交易结果,整个流程结束。
其中,组包就是编码的过程,解包就是解码的过程。
2.计算机编码基础
计算机可以存储数字、字母、中文、特殊符号、图像等等各种复杂的数据,但不管是何种数据,最终都是通过底层的二进制数字(0和1)来表示,那计算机是怎么通过0和1的一长串组合来表示那么多复杂的数据呢?
2.1整型的存储
首先,我们来看一下最简单的数据:整型,在计算机中如何表示。
计算机通过补码来表示一个整型值,补码是在原码的基础上取反码加1。
- 原码:一个数在计算机中的二进制表示形式,其中最高位存放符号,正数为0,负数为1。比如-3用一个字节(8位)来表示就为10000011
- 反码:反码是在原码的基础上变化而来的,正数的反码和原码相同,负数的反码是在原码的基础上,符号位不变,其余各个位取反。比如-3的反码表示为11111100
- 补码:正数的补码和原码相同,负数的补码是在原码的基础上,符号位不变,其余各个位取反,最后+1。比如-3的补码表示为11111101
//原码转成补码的过程(正数不变,负数取反加1)
[+1] = [00000001]原 => [00000001]反 => [00000001]补
[-1] = [10000001]原 => [11111110]反 => [11111111]补
从以上可以看出,原码更接近人类的理解方式,那为什么不直接用原码而用补码表示数字的存储呢?
通过补码表示方式,可以让符号参与运算,统一数的加减法运算。此外,补码和原码相互转换,其运算过程是相同的,不要额外的硬件电路。
//补码方式展现3-2的运算过程
//第一步,将减法变成假发3-2转成3 + (-2)
-2的补码 [10000010]原 => [11111101]反 => [11111110]补
//第二步, 进行3 + (-2)的运算
[00000011]3
+[11111110]-2
=[00000001]运算结果
//将运算转成数字
[00000001] => +1
2.2字符的存储
字符是指计算机中使用的文字和符号,比如1,2,3,a,b,c,空格,换行,标点符号,中文,日文,图片等。
可以把字符的存储理解成一个“翻译”的过程,因为计算机只能存储一个个的字节数据,不能识别字符,所以我们需要将字符翻译成计算机可以理解的字节数据,这个将字符翻译成字节的过程我们称为编码。
举例来说ASCII码:
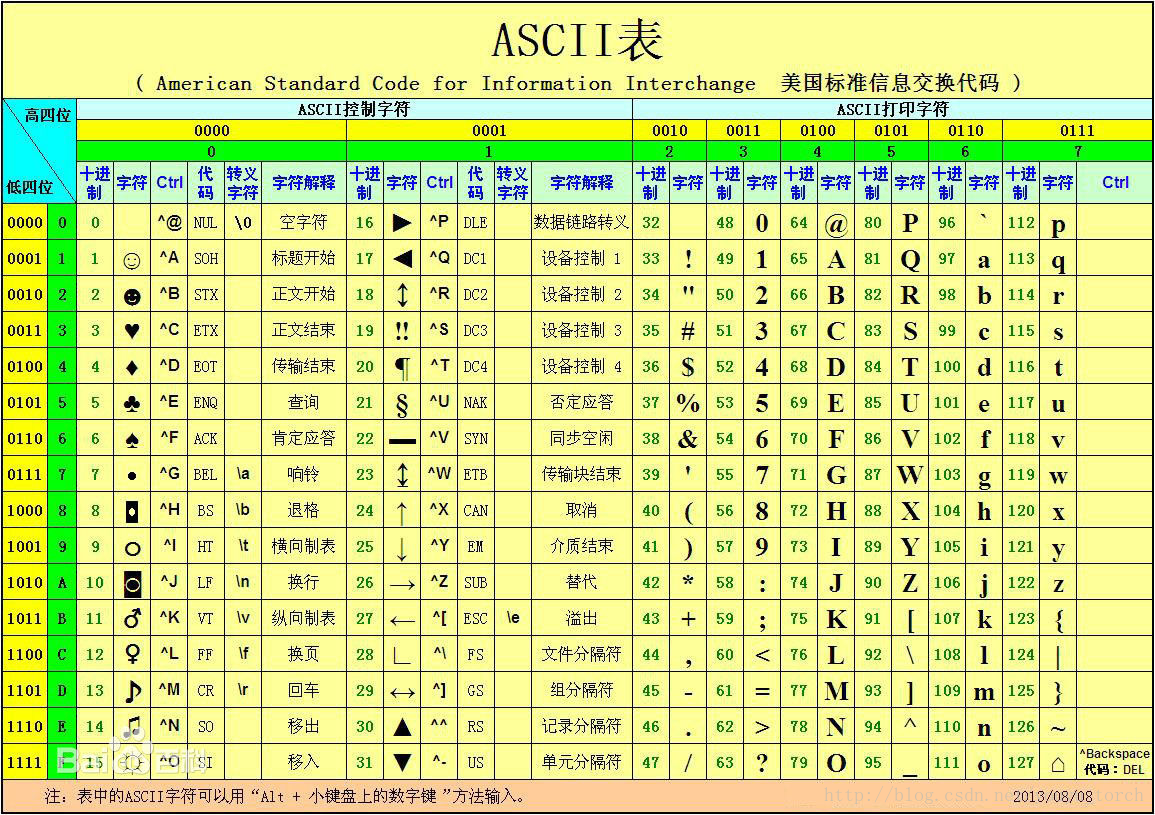
这是单字节的ASCII码表,可以表示0~127个字符数据,其中0~31是控制字符如回车、换行、删除等;32~126是打印字符,可以通过键盘输入并且能够显示出来。
现在,通过字节来存储不同字符的方法解决了,但人类有各种不同的语言,如英语、中文、拉丁文等等,需要用不同的编码方式来表示,不同的语言还要在计算机上同时显示,这就需要统一的编码格式规范了。
2.3常见的编码格式
ISO-8859-1
128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,在所有编码中应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。
GB2312
它的全称是《信息交换用汉字编码字符集 基本集》,它是双字节编码,总的编码范围是 A1-F7,其中从 A1-A9 是符号区,总共包含 682 个符号,从 B0-F7 是汉字区,包含 6763 个汉字。
GBK
全称叫《汉字内码扩展规范》,是国家技术监督局为 windows95 所制定的新的汉字内码规范,它的出现是为了扩展 GB2312,加入更多的汉字,它的编码范围是 8140~FEFE(去掉 XX7F)总共有 23940 个码位,它能表示 21003 个汉字,它的编码是和 GB2312 兼容的,也就是说用 GB2312 编码的汉字可以用 GBK 来解码,并且不会有乱码。
GB18030
全称是《信息交换用汉字编码字符集》,是我国的强制标准,它可能是单字节、双字节或者四字节编码,它的编码与 GB2312 编码兼容,这个虽然是国家标准,但是实际应用系统中使用的并不
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









