





6.2 System development is model building
6.2 系统研发即模型构建
6.2.1 Models
6.2.1 模型
System development is a complex task. Several different aspects must be taken into consideration. What we wish to achieve is a reliable computer program that performs its tasks properly. But typically system development is such a complex task that we cannot cope very well with handling so many requirements simultaneously. It may be the case that for very small programs we can take the requirements and write the program directly, but this is utterly implausible for the systems discussed here. What we need to do is to handle the complexity in an organized way. We do this by working with different models, each focusing on a certain aspect of the system. By introducing the complexity gradually in a specific order in successive models, we are able to manage the system complexity. We work with five different models:
• The requirements model aims to capture the functional requirements.
• The analysis model aims to give the system a robust and changeable object structure.
• The design model aims to adopt and refine the object structure to the current implementation environment.
• The implementation model aims to implement the system.
• The test model aims to verify the system.
系统的研发是一个复杂的工作. 与程序开发相关的一些不同方面都必须充分的加以考虑.我们希望最终获得的是一个可靠的计算机程序,他可以正确的执行自己的任务. 然而在现实的开发过程中,典型的系统研发工作是一个如此复杂的工作,这样一来我们很难科学的应对cope多个不同的系统需求的要求,把他们并行的处理的很好. 可能在面向那些小型的程序开发情况下,我们可以非常容易的分析好项目需求并直接开始设计程序,然而这种情况对于本书中讨论的大型系统开发过程是完全难以置信的(utterly implausible). 在面向大型系统的开发任务下,我们需要针对复杂的开发过程采用一种科学的组织方式.我们利用不同的模型来进行有组织的开发工作, 其中每一个模型都聚焦于系统的一个特定的方面. 基于一种特定顺序由简到繁逐步引入一组连续的实施模型.我们就有可能有效的管理好复杂系统的开发过程.在OOSE中,我们主要需要利用5种不同的模型.
• 需求模型(The requirements model)的目标在于捕获系统的功能性需求.
• 分析模型(The analysis model)的目标是在于为系统提供一个强壮而易于变化的对象结构.
• 设计模型(The design model的)目的在与把前期设计的对象结构进行适配和优化到当前的开发环境中..
• 实施模型(The implementation model)的目的是在于指导系统的实现.
• 测试模型(The test model)的目的是在于验证系统的功能.
Each model tries to capture some part or aspect of the system to be built. These models are the output of the activities shown in Figure 6.2 which are discussed in the forthcoming chapters. We will discuss in more detail later how the models relate to the different activities.
每一个模型构建的目标在于努力的捕获到系统需要构建的一个方面或者是一个部分.这些模型是OOSE开发过程中不同阶段建模活动的输出制品, 详细的阶段划分和输出制品见图6.2, 而在后续的章节中我们将进一步详细的进行讨论. 我们还将进一步的讨论更多的细节关于每一个模型是如何与不同的活动关联起来的.
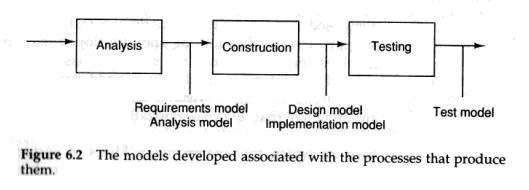
/ 图6-2 模型开发以及和他们创建相关联的开发过程
Actually, other types of model may be appropriate and thus also be used (for example, specific hardware models) and some of the models can be merged or only used as working models and not saved. However, we have found these models appropriate to several different kinds of applications of varying size. When discussing the different activities in subsequent chapters we will also give some comments on how this model structure can be modified for certain reasons.
事实上,其他类型的模型也可能是合适的,这样一来也可以引入到开发过程中应用(举个例子来说,特定的硬件模块设计模型);同时有一些模型可能会被合并,并且仅仅会作为工作过程模型使用而不会被永久保留.然而,在实践的过程中我们已经发现这些模型适用于来自不同领域的,规模大小不同的应用项目. 当我们在后续章节中讨论这些不同的开发过程,我们也会给出我们的观点来阐述在不同的应用领域中,如何都模块的结构进行修改来适配不同的应用领域.
The basic idea with these models is to capture right from the start all the functional requirements of the system from a user perspective. This is accomplished in the requirements model. Here we describe how a potential user will use the system. This model is often developed in close participation with end users and orderers. When this model becomes stable, the system is structured from a logical perspective into a form that is robust and, above all, maintainable during the system life cycle. This is done in the analysis model. Here, we assume an ideal implementation environment; that is, we do not take into consideration which DBMS to use, hardware, the current implementation language, whether t he-system should be distributed or not, real-time requirements and so on. We have two main reasons for this. The first is that it is much easier to work with ideal circumstances: it allows us to reduce complexity and thus focus efforts on giving the application a stable, robust and logical structure. Secondly, the implementation environment will change during the life cycle - think what has happened with hardware technology in the past ten years - and we do not want the current circumstances to affect the system structure. However, the world is not ideal. When we have developed an ideal structure, we adopt this maintainable structure with as little violation as possible in the design model. The reason for this is that we want the design model to be maintainable as well. In this model we decide, for instance, how to integrate a relational DBMS into the application or how to handle a distributed environment. Whereas the analysis model mostly cannot be implemented straightforwardly, the design model should be. When all of these decisions are made and the application further refined and formalized, the implementation model is gradually developed. This is the actual code to be composed and/or written. Finally the test model is developed to support the verification of the developed system. This mainly involves documentation of test specifications and test results.
关于这些模型最基本的想法是能够在项目的建设前期就能够正确的捕获所有的功能性需求, 而这些功能性需求都必须要求站在用户的观点.在这里我们描述是一个潜在的用户将如何使用这个系统. 需求模型的开发过程通常需要最终用户和他的订购者密切的参与.当需求模型逐渐变得清晰和明确, IT系统将进一步从一个抽象的逻辑视图构建成为一个健全可靠的边界(a form that is robust), 而最重要的一点是这个边界在系统的生命周期中是可以维护的和管理的.这个工作是在分析模型中完成的. 在分析的过程中,我们假设一个理想的IT集成环境;也就是说我们不会考虑那些数据库系统将会被使用, 系统部署的硬件环境, 具体的程序开发语言, 目标系统将会是集中方式还是分散方式,是否有实时应用的需求,等等诸如此类的考虑. 我们采用这样的开发过程主要是基于两点理由. 首先在理想的集成环境下进行分析设计工作可以简化分析工作的复杂度, 他可以帮助我们减低分析的复杂性并能够专注在如何为应用系统提供一个可靠,健壮,合乎逻辑的结构.第二点是在于在IT系统的生命周期中真实的集成环境通常是在不断的发展和改变之中;大家可以回顾以下最近10年之中硬件系统的发展情况,;而同时我们也不希望因为当前事实环境的限制来影响系统的结构. 然而,真实的开发工作并不是非常理想. 当我们在分析模型中设计了理想的结构, 我们将在后续的设计模型中将尽可能的采用这种可维护的结构,并尽量少的违背这种结构. 我们这样做的原因是在于我们希望相关的设计模型也是非常易于维护的. 在设计模型中,我们需要具体决定和实施环境相关的一些细节,举个例子说,如何集成一个关系型数据库到一个具体的应用当中去, 如何处理分布方式的应用环境. 通常分析模型是无法直接进行IT开发继承的,而设计模型必须要能够直接进行开发集成. 当上面所以的细节都已经做好决策,同时具体的应用被进一步的优化和标准化,相关的实施模型也逐渐的开发完成. 这就是那些真实的程序代码来被引用,或者是被书写. 最后,我们会完成相关的测试模型来支持对研发系统的功能验证工作. 测试模型主要是包括和测试定义,以及测试结果相关的文档资料.
The system is gradually refined using these models. The models should not be viewed as sacred or 'the final answer' or anything like that. Every organization must decide which models are appropriate to use. We have found that these models form a sound base on which to develop many kinds of systems, and that it is possible to manage the complexity as it is introduced step by step in the models. By Incusing on the more important aspects early, a base which enables I he system structure to be modifiable is laid.
利用这些模型, 目标IT系统被逐步进行优化和具体化. 这一系列的模型不应该被看成是神圣的金科玉律sacred,或者是”最后的答案” 'the final answer' ,或者其他任何这样类似的想法.每一个开发团队都必须决定那些模型是合适应用的.在具体的应用中,我们发现这些模型构建了一个良好的基础(a sound base), 基于这个良好的基础可以方便的研发出多样化的系统,同时采用OOSE的这一套方法我们有可能管理IT系统的复杂性,因为在开发的过程中,这些模型是一步一步的序列化引入的.通过在IT项目集成前期提前关注这些更加重要的方面,我们提前大奠定了一个基础平台,基于这个基础平台我们可以保障未来IT系统拥有一个可以方便调整的体系结构.
The relations between these models are of course important. The transitions between the models are seamless. By seamless we mean that we are able to tell, in a foreseeable way, how to get from objects in one model to objects in another model. This is absolutely crucial for an industrial development process since the result must be repeatable. The method layer will define these transformation rules. To be able to maintain the system it is also necessary to have traceability between the models. By this we mean that we are able to trace objects in one model to objects in another model. Traceability will in our case actually come as a side-effect of the seamless nature of model transformations.
这些模型之间的相互关系当然是非常重要的.这些模型之间的转化是无缝seamless和平滑的. 在这里我们使用无缝seamless这个单词的用意是想表达我们有能力来描述, 而这种描述是基于一种可以预见的方式, 如何将一个模型中的对象进行抽取并转换另外一个模型中特定对象.这一点在一个工业化的IT系统研发过程中显得尤其关键crucial,因为开发的结果必须具有可重复性..在后续开发方法的层面将会定义这些模型之间的转化规则. 为了能够有效的维护系统, 我们同时需要能够保持模型之间的可追踪性.. 这种可追踪性意味着我们有能力跟踪一个模型中的对象是如何映射到另外一个模型中的对象.在我们的OOSE应用场景中, 可追踪性也带来了额外的开发工作量,这一点也是模型之间无缝转换要求的一个副作用.
The models are tightly coupled to the architecture, and our aim is to find concepts which:
• are simple to learn and use;
• simplify our understanding of the system;
• provide us with a changeable model of the system;
• are sufficiently powerful to express the information which is required to model the system;
• are sufficiently defined that different people can discuss the system in terms of these concepts without being misunderstood.
这些模型和IT系统的体系结构有非常密切的联系,而我们的目标是想阐述如下的核心理念:
• 易于学习和使用;
• 简化我们对系统的理解;
• 为我们提供了一个可以改变的模型a changeable model来描述IT系统.
• 模型必须是足够强大来表达相关的信息,利用这些信息可以用来构建系统模型.
• 模型必须是能够完备的进行定义,这样不同的人可以能够参与讨论,并保证这些与系统体系相关的概念能够被大家正确的理解.
We will discuss these topics in this chapter. In the box on expressable information spaces we give a theoretical perspective to the problems associated with these issues.
我们将在这一个章节中讨论这些主题.在下面的可表达信息空间Expressible information spaces的补充阅读材料中,我们针对与信息模型相关的一些问题给出了一个基于理论视角答案.
Expressible information spaces
可表达信息空间
This discussion is aimed at giving an intuitive understanding of the problems of system development. We draw an analogy with different areas in mathematics and computer science. It should nevertheless only be read as a presentation of ideas, since the basics are not fully expanded. Neither have we handled the terminology very strictly and we make no attempt to be detailed. However, we believe that the analogy can help to improve your understanding.
这一部分的讨论的目标在于帮助读者能够对IT系统研发中可能遇到的问题形成一个直观的理解an intuitive understanding.我们利用数学和计算机科学的不同领域的理论进行类比说明. 不过这些补充阅读材料仅仅是用来进行观念的介绍,因为很多基本概念并没有展开进行描述.在这里我们既没有针对这些专业术语进行严格的处理和定义, 也没有试图进行详细的描述.然而,我们相信这些类比说明可以帮助大家提升对IT系统开发中的问题进行理解.
An information space is a space where information can be expressed. It consists of a certain number of dimensions and, in order to create models in this space, it uses concepts that have meaning within this information space. These concepts allow us to express models in this space. The concepts are thus the tools with which to express oneself, and the success of any software engineering technique depends on the appropriateness of the concepts chosen.
一个信息空间是一个用于表达信息的空间. 这个信息空间包含特定数量的信息维度,同时,为了能够在这个信息空间中创造模型,他使用一些在信息空间中具有含义的概念concepts. 这些概念允许我们在信息空间中进行模型表达.这些概念就是一组工具可以用来表达自己,同时也能够成功表达任何依赖合适选择的概念concepts.的软件工程科技.
We can consider the systems we construct as systems to solve problems; for example, a telephone exchange will connect together a number of subscribers, a banking system will control the accounts of the customers, a process control system will control a critical process. If a problem can be solved within a finite time, it is called deterministic. The problems we shall solve may therefore be placed in the information space for deterministic problems (otherwise it is not even worth trying). (This information space is often called the set of NP-complete problems. NP is an abreviation for non-deterministic polynomial and means that one can at least determine whether the problem is solvable in polynomial time.) Amongst these deterministic problems exist the most difficult problems that we can hope to solve within a predetermined time. There are problems that lie outside this space, which are thus not certain of a solution within a predetermined time. An example is 'Guess which number I'm thinking of. You have one try. '
我们可以把我们构造的系统当作是可以用来解决问题(to solve problems),举例来说一个程控交换系统可以汇聚一定数量的电话线路, 一个银行系统可以管理用户的帐户,一个过程控制系统可以用来控制一个重要的过程.假如一个问题能够在给定的时间内解决,我们把他叫做确定性问题.那些我们计划解决的问题因此能够放置在信息空间中作为确定性问题(否则,这些问题甚至不值得去尝试) (这通常被称为信息空间的NP -完全问题集,NP是非确定性多项式的简写, 同时他意味着我们可以至少决策是否一个问题可以在多项式时间内可以解决). 在这些确定性问题的存在的最困难的问题,是我们可以希望预定时间内解决当然在这个信息空间之外也存在着问题, 这些问题在预先给定的时间内是否有解就是不确定的. 一个例子就是’猜测我正在思考哪个数字,你仅仅有一次回答的机会.’
This can feel safe so long as we confine our attention to deterministic problems, and this relates to (nearly) all of the systems we develop. Now, it has been proved that all deterministic problems can be solved with a Turing machine. A computer has the same power of expression as a Turing machine, with the exception of not having infinite memory, but that is seldom the critical problem. So, the question is: why do we have such difficulty in building a system to solve a problem, when the problem has been proved to be solvable? The answer is that we do not fully master the complexity. Our understanding is too limited. What we want from the concepts is, as you now may realize, to manage the complexity of the information space. We can unquestionably do this with the concepts a Turing machine offers (an infinitely long tape where we can read and write symbols accompanied with a state transition graph). Even if these concepts can express our space, they are so primitive to work with that they can hardly help us. We can compare this with unit vectors in a space or with symbols to count with. If we have only one symbol to count with, we would have to print the symbol 1000 times to express the number 1000; if we have two symbols we can combine these symbols and thus have a length of only 10 symbols (210 = 1024). It is therefore insufficient to have concepts theoretically able to express the information space; they must also be powerful to work with. Another computational tool is lambda calculus. This is just as powerful as a Turing machine, but in order to work out, for instance, 4 x 5, a whole page of calculations would be required. Owing to this problem, certain reduction rules have been added to the lambda calculus, but it is still too complex to work with for larger problems.
只要我们能够集中我们的注意力确定性问题deterministic problems,这会让人感到安全和放心,同时这一点和我们计划开发大所有系统都有联系.现在,它已被证明了所有的确定性问题可以用一个图灵机a Turing machine来解决。一台计算机具有同样的能力利用图灵机的模式进行表达, 但有一种例外假如计算机的内存出现不足, 然而在现实的场景中很少有因为内存缺乏所引发的图灵机表达异常问题. 所以,我们面临的问题是:为什么我们有如此多的困难在构建一个系统来解决一个问题,而且前提是这个问题已经被证明是可以解决的..答案是在于我们没有完全掌握问题的复杂性.我们的理解还是非常有限的.希望大家从这些观念中收获的道理是,你现在可以认识到的是,能够有效管理复杂的信息空间是非常重要的. 毫无疑问我们可以的利用图灵机提供的概念来管理信息空间的复杂性.(一个无限长的磁带,其中我们可以读写一组伴随着状态转移图的符号) .即使这些概念能够有效表达我们的信息空间, 他们还是过于原始导致难以应用,这样一来很难帮助我们解决问题. 我们可以利用在空间单位矢量数或等待计数的符号数进行比较说明.如果我们只有一个符号来计数,我们必须把这个符号打印1000次来表达数字1000,假如我们拥有2个符号, 我们可以组合这两个符号,这样一来在仅有的10个符号长度就能够表达(210 = 1024).因此仅仅在理论上有概念能够完备的表达信息空间是不够的;这些概念必须能够足够强大来方便在工程应用中使用.另外一个计算工具是λ演算.这个工具和图灵机一样强大,然而为了能够快速的算出结果, 举个例子, 4 x 5,一页完整的计算过程都需要.由于这个问题,特定的删除规则被添加到λ演算中,然而面向大型问题的时候,这还是过于复杂.
The development of programming languages also aims to solve these problems. Initially, computers were programmed with very primitive languages using ones and zeros to represent the state of some switches. This was at a very low level and the number of errors made increased exponentially with the size of the programs. Assembly languages developed to represent these ones and zeros in a more human way. Although this was of great help, it was still too low a level for larger programs. Still higher-level languages, more readable for humans, were developed to cope with this increase of complexity in the larger programs that were being developed. Compilers were invented to translate automatically from the high-level language to a lower-level machine language. One of the goals for programming language developers is to develop a suffienciently expressive programming language, often for some family of applications, and at the same time keep this language as small and simple as possible. Preferably the language concepts should be close to the way people think of a problem.
.程序设计语言发展的目标在于解决这些问题.. 在计算机发展的初期, 计算机通常是利用一些非常原始的编程语言进行程序设计, 这一些原始的程序设计语言仅仅利用1和0来表达一些开关的状态(the state of some switches).This was at a very low level and the number of errors made increased exponentially with the size of the programs. 应用早期编程语言是在一种非常低的层面进行程序设计,这样一来程序中的缺陷会随着程序规模的增加成倍的增长.Assembly languages developed to represent these ones and zeros in a more human way. 后续发展的汇编语言采用一种更加人性化的方式来表达这些0和1.Although this was of great help, it was still too low a level for larger programs. Still higher-level languages, more readable for humans, were developed to cope with this increase of complexity in the larger programs that were being developed. 虽然汇编语言的发展对程序设计者提提供了更多的帮助,但是针对一些大型程序开说这种编程模式还是太低层了.更高层次的编程语言,具有更加方便的可读性的编程语言被研发出来,以便应对正在被开发大型程序复杂度的增长.另外,编译器被发明出来用于实现把高级程序语言自动的转换为一种低层次的机器语言. 程序语言研发者的一个目标是在于发展一种具有充分表达能力的程序设计语言, 可以适用于特定应用领域的程序设计,同时这种程序设计语言要尽可能保持简单和规模微小.程序设计的理念最好能够和人类思考问题的方式
The family of object-oriented programming languages is no exception to this; quite the opposite, as they try to follow the way people think and directly map this onto an executable program. Although this is a tremendous improvement for software developers, it is still too low-level to manage the complexity and understanding of large systems, the development of which we are discussing in this book.
面向对象家族的程序设计语言的设计目标也不例外;然而恰恰相反,因为面向对象的程序设计语言试图模仿人的思考方式,并且能够直接把人的思考方式映射为可执行的语言. 虽然这对于软件程序设计者来说是一种巨大的提高,利用这种OO程序设计语言来管理软件的复杂性,和理解大型的系统还是显得太过于底层,而研发和理解大型IT系统正是我们这本书讨论的重点.
Actually, much of the development of programming languages has been to increase linearly the level of abstraction of the computers. Starting with the von Neumann architecture for the first computers (von Neumann (1945)), the basic principle was to build the computer out of five parts: memory, central control, arithmetical unit, input and output. Computers have since then in most cases been built in basically this way (often called the von Neumann architecture). The first programming languages were naturally designed to cope with this architecture and this forced programmers to think the way computers do, that is, to use control statements that manipulated data in the memory. In the early days it was necessary, for reasons of efficiency, to think in the same way as computers, but higher-level languages have also kept this division of data and programs. However, with the benefit of hindsight it is even more galling to accept that we have also kept this division at the higher levels of analysis and design, as in the function/data methods of software development. In object-oriented languages and methods this tradition is finally broken to incorporate data and programs, and to encapsulate the data into the programs. We should not blame John von Neumann for us being on the wrong track for so many years, quite the opposite; he is one of the greatest mathematicians of our century and has contributed a lot to the evolution of our field. It is the rest of us who lacked the creativity to realize that programming paradigms should not be developed in the same way as computer hardware paradigms, but rather as people think.
确切的来说,大多数的程序设计语言的演进是能够线性的提升计算机程序设计的抽象水平,进而提升程序设计的效率. 从冯诺依曼体系结构开始的第一代计算机von Neumann (1945) , 最基本的原则就是将计算机构建成5个部分, 内存, 中央控制,计算单元,输入单元,输出单元.(这样一来计算机在大多数场景下也是基于这种方式来组成和发展,我们称之为冯诺依曼结构.) 最早的程序设计语言也非常自然的需要适配冯诺依曼结构来设计,这样一来他强迫程序设计者遵循计算机的工作方式来思考,换句话说需要控制语句来操控内存中的数据. 早期的阶段中, 出于程序效率的考虑, 程序设计员需要模范计算机的思维这种设计方式是非常必要的, 然而后续高级别的程序设计语言也保持了这种数据和程序的分离设计. 然而, 可以算是我们的后见之明, 更为难堪的是在于我们不得不接受这样的事实,我们后续保持了这种程序和数据的分离模式直到更高层次的分析和设计过程,因为在功能/数据这种设计方式中就沿用了这种设计方式. 在面向对象的程序设计语言和方法中,这种传统的设计传统被打破来实现程序和数据的合并(incorporate ), 并进一步将数据封装到程序之中. 我们不应该抱怨冯诺依曼体系结构对IT程序设计过程的误导了很多年, 恰恰相反,他是我们这个世纪最伟大的数学家之一,并且为计算机科学领域的发展做出了巨大的贡献. 后续缺乏创造力的程序设计人员无法认识到程序设计范式不应该遵循计算机硬件设计的范式来发展,而应该更加接近人类的思考方式.
6.2.2 Architecture
System development thus includes the development of different models of a software system. Our goal is to find a powerful modeling language, notation, or as we will call it, a modeling technique, for each of these models. Such a set of modeling techniques (one for each model) defines the architecture upon which the system development method is based. Another, more formal way to express this is: the architecture of a method is the denotation of its set of modeling techniques. Here we use the term 'denotation' in the way it Ls traditionally used in the area of formal semantics for programming languages; the denotation of a language construct is what the construct stands for, or the semantics of the construct. Intuitively, you may also think of architecture as the set of all (good) models you can build using the method-defined modeling technique. We may thus view the architecture as the class of models that can be built with a certain modeling notation.
系统开发过程包括针对一个软件系统不同模型的开发过程.我们的目标在于发现一种强有力的建模语言, 一种符号notation,或者我们将称之为一种建模技巧,用于描述系统开发过程中需要的各种模型. 这样的一套建模技巧(每种模型一个)定义了软件系统研发方法赖以实施的基础架构.另外一种更加正式的说法来表达这种含义就是, 一种方法的体系结构就是这种建模技术的外延和意义.在这里,我们使用'denotation'(意义)这个术语来表达上下文的含义. 通常在传统的应用中,'denotation'(意义)这个单词用来在针对程序设计语言的标准语意描述领域应用. 举例来说,关于一个编程语言结构的'denotation'(意义)就是结构本身所代表的含义,或者就是结构所表达的语意(semantics.). 直观的来说,你也可以认为体系架构是一套完整的(优秀的)基础模型, 利用这些基础模型定义的方法你可以准确描述自己需要的结构. 而我们的观点是把体系结构(architecture)当作是创造实际模型的类, 利用一套特定的模型标识语言notation可以将体系结构实例化为真实的模型.
A modeling technique is normally described by means of syntax, semantics and pragmatics. By syntax we mean how it looks, semantics is what it means, and by pragmatics we mean heuristics and other rules of thumb for using the modeling technique.
我们通常利用语法syntax,语意semantics,和语用学pragmatics来描述一种建模技巧. 我们利用语法来描述建模技巧的外观,也就是建模技术看起来的样子; 我们利用语意来描述建模技术的具体含义, 而关于建模技术的应用场景,启发,应用规则等其他的关键点则通过语用学来描述.
The modeling techniques are used to develop models. These models should be powerful enough to build the systems we are interested in developing. The techniques should be easy to use and contain a few, but powerful, modeling objects to enable easy learning. They should, most of all, help us to handle the complexity that characterizes the systems we build.
我们使用软件建模技术来设计IT项目集成过程中需要的各种模型.这些模型必须是足够完备和强大,以便辅助构建我们期望的软件系统. 这种软件建模的技巧必须容易使用,并且包含少量的,但是非常强有力的模型对象,以便建模者易于学习和掌握.还有最重要的一点在于, 这些建模对象必须能够帮助我们面向复杂的系统进行分析和描述,并归纳出系统的特征.
To build these models, we require a method to show us how to work with the modeling techniques in order to develop systems. The method describes how we, with the aid of the modeling techniques, can create models of different systems. The specific system architecture we then obtain is formulated in terms of the modeling objects used. A specific system's architecture is therefore the result obtained after applying a method to a system.
为了设计这些模型, 我们需要一种方法来向大家演示,如何在构建IT系统的过程当中,利用这些建模技巧开展工作. 这种方法将描述我们在建模技巧的帮助下,如何创造出不同IT系统需要的模型.我们期望拥有的特定系统体系结构将会在使用模型对象的条件下进行定制,
An object-oriented view of architecture
一种面向对象观点的体系结构
In order to make a comparison with object-orientation, we can regard the architecture as a class. For each system we design, we create an instance of this class. The specific system architecture is thus an instance of the architecture that the method is based on. All system architectures have the same characteristics (modifiable, under¬standable, and so on), but they can all look different. One specific new system development can be seen as sending a Create stimulus to the architecture class which then applies the development method to the architecture for a given problem (see Figure 6.3), and thus creates a new instance (system architecture). The development method can thus be seen as an operation (in Smalltalk: method!) on this architecture, where parameters can be, for example, requirement specification, implementation environment and so on.
为了和面向对象的技术进行比较,我们可以把体系结构当成是一个类.对于我们设计的每一个IT系统, 我们可以利用这个类(体系结构)来创建一个对应的实例.一个特定系统的体系结构因此也就是体系结构(architecture)的一个实例, 而体系结构是软建模方法的基础. 所有的系统体系结构architectures拥有相同特征(可以修改性, 容Create stimulus,等等),但是他们都可以看起来完全不同. 一个特定的新系统研发过程可以被当作是面向体系结构这个类发送一个创建的指令(Create stimulus ),这样将针对一个给定的领域问题应用建模方法,因此也就能够创建一个新的实例(体系结构) (见图 6.3).这种建模方法能够被看成是的一种操作(在Smalltalk 中称为方法),创建操作能够施加在体系结构之上,同时需求定义文档, 系统实施环境都可以被当成是创建操作的参数.
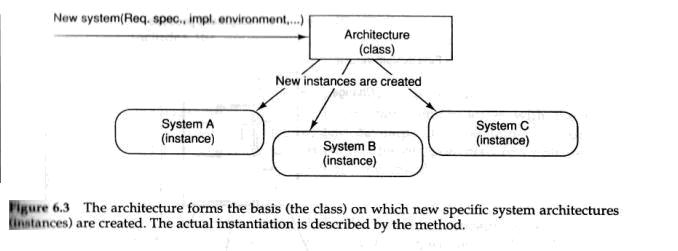
To make this development method usable in larger contexts, we need to define a process and tools. To continue the analogy with object-orientation, we can regard this process as being the union of all operations one can perform on the instances.
为了保障这种软件开发的方法能够在大型的项目中能够正确应用, 我们需要定义一个过程和一些工作. 为了继续这种面向对象的思考方法,我们可以把过程看成是一组操作的集合, 利用这一组操作,我们可以针对软件项目进行研发和定义.
6.2.3 Development processes
6.2.3 研发过程
We mentioned previously that we assume that the requirement specification exists in some form. From this specification the system is developed into a first version. Almost all systems will then be further developed continuously, including maintenance of the system. Maintenance will of course also include analysis of new requirements. In Chapter 2 we discussed the problems of describing a development process using a waterfall model. A waterfall model only describes an ideal new development. In reality, a system development process is a number of different waterfalls, as discussed in Chapter 2.
正如我们前面所提到的,在这里假设需求规范是以某种规范的形式而存在.来源于这些需求规范,我们可以开发出目标软件系统的第一版.通常来说几乎所有的IT系统在未来都会持续的进行研发和演进,包括对系统进行维护. 面向软件系统的维护当然会包含针对新需求的分析过程.在第二章中,我们详细讨论过利用一个瀑布模型这种方法来定义和描述一个IT系统研发过程可能引起的各种问题.一个瀑布模型仅仅能够描述一个理想的新系统的开发过程. 然而在现实的软件开发过程中, 一个真实的系统开发过程是由多个不同的瀑布模型所组成, 这正如我们前面在第二章中所描述的一样.
Instead of focusing on how a specific project should be driven, the focus of the process is on how a certain product (deliverable application) should be developed and maintained during its entire life cycle. This means that instead of describing a project in a waterfall description, we have to divide the development work for a specific product into processes, where each of these processes describes one activity of the management of a product. The processes work highly interactively. Each process handles a specific activity of the system development (see Figure 6.4). For instance, most types of project will involve some construction activities. This is described in the construction process.
我们将不再集中注意力在一个特定的项目应当如何开发和管理, 而是将软件开发过程的重点集中在一个特定的软件产品(一个可以交付的应用) 在他完整的生命周期内应当如何演进和维护. 这种做法就意味着,我们不再利用瀑布模型的方法对一个项目进行描述, 取而代之的方法是我们必须将针对一个特定产品而开发的工作划分为不同的过程阶段, 这中间的每一个过程都对应描述了产品管理的一个活动..多个过程之间需要高度的互动协作工作. 每一个过程负责处理系统开发过程中的一个特定活动.(见图6.4). 举个例子来说,绝大部分项目将包含一些软件开发的活动. 这种类型的活动将在构造过程(construction process)中进行描述.
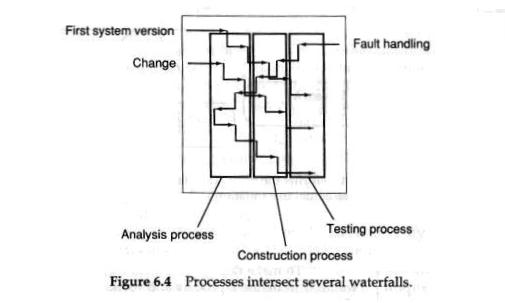
In this manner, the product will be managed by a number of processes. The development work thus extends over all these processes and the processes exist during the whole system development, namely during the whole system life cycle. All development work is managed by these processes. Each process can in its turn consist of a number of communicating subprocesses.
在这种方式下, 一个特定的产品将被一系列的过程进行管理. 软件系统开发的工作将扩展覆盖到所有这些过程, 并且这些过程将在整个系统的开发活动中存在, 我们称之为整个系统的生命周期. 所有的系统开发工作将通过这些过程来进行管理. 而每一个过程可以依此包含一系列互相通讯的子过程.
The main processes are the analysis, construction and testing processes (see Figure 6.5). Linked mainly to the construction process, there is also a component development process.
软件开发过程中包含主要的过程是分析,构建,和测试过程(见图6.5). 而主要和构建过程相关联,还存在一个组件开发过程.
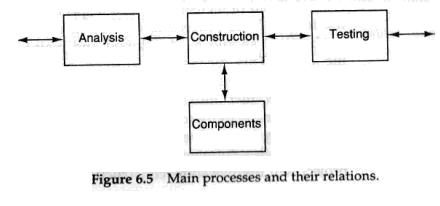
In the analysis process, we create a conceptual picture of the system we want to build. Here the requirements model and the analysis model are developed in order to understand the system and to communicate it to its orderer and to the construction process. In the construction process, we develop the system from the models created within the analysis process. This process develops two models: the Components design model and the implementation model. This process thus includes the implementation and results in a complete system. The testing process integrates the system, verifies it and decides whether it should be passed on for delivery.
在分析过程中,我们创造我们希望构建目标系统的概念图形. 在这个过程中我们将设计需求模型和分析模型, 以便理解系统, 并和系统的订购者进行沟通, 以及后续的构建过程进行沟通.在构建过程中, 我们将根据前期分析过程创建的需求模型和分析模型进行系统开发工作. 这个过程将开发两类模型, 组件设计模型和实施模型.这个过程将包含系统的实施工作,最后将产生一个可用的系统. 而测试过程将集成系统, 测试目标系统, 并最终决定是否通过测试并提交给客户.
Apart from these main processes there is the component development process, which mainly communicates with the construction process. This process develops and maintains components to be used during construction. The components are implemented code, which can be used in several different applications. The component process is thus not tied to a specific product, but is a multi-product process.
除去这些主要的过程之外, 还有存在一个组件开发component development过程, 组件开发过程主要是和构建过程进行沟通协作. 他负责开发和维护系统构建过程中需要使用的组件. 组件是已经开发好的程序代码, 这些代码可以在不同的应用系统中进行复用. 这样一来组件开发过程不是和一个特殊的产品进行绑定, 而是一个多产品开发过程.
In Chapters 1 and 2, we discussed the concepts of architecture, method, process and tools. In this chapter, we discuss the architecture forming the basis of the method and process, that is, the concepts of each model. In the following chapters, we shall discuss the method layer of each main process in more detail. Each process has its own chapter. The discussion within these chapters will be confined to the method base from which each process is built. We will also discuss some parts of the processes that are of special interest although most aspects of the process and tool layer are omitted in this book.
在前面的第一章和第二章中,我们详细讨论了关于体系结构, 方法,过程,和工具的概念. 在本章中,我们详细讨论了体系结构来组成方法和过程的基础,也就是每个模型的概念. 在后续的章节中,我们将更加详细的讨论每一个主要过程在方法层面(the method layer)的细节.每一个过程将拥有他自己对应的章节. 在这些章节的讨论中, 我们将专著讨论对应开发过程涉及到的方法基础.我们也会讨论这些开发过程中一些特别精彩的部分, 虽然本书忽略了过程和工具层面绝大部分的内容.
Each process can be supported by tools. These tools are essential, especially when the process is used on a large stale. With the help of the tools, we can automate many work steps and also obtain an invaluable aid in keeping documentation consistent.
每个开发过程可以通过工具来支持. 这些工具是必须的, 尤其是在大型项目上应用这些过程. 在工具的帮助下, 我们可以将工作的步骤自动化, 同时可以获得无价的帮助来实现保持开发文档资料的连续性.
So, we regard a development as a set of communicating processes. This suggests that they are not some set of fixed and complete procedures able to replace each other mechanically, but quite to the contrary, they communicate intensively with each other and each of them depends heavily on the work done in the other processes. The system development thus iterates over these processes. This is one of several essential differences between method and process.
基于上面的理解,我们将软件开发过程看成是一套互相通信的过程. 这就意味着这些过程不是一套固定的,完整的步骤, 可以机械的进行替换, 然而恰恰相反, 他们需要密集的进行互相通信,同时每个过程需要高度的依赖其他过程的工作.系统研发的工作需要将这些过程反复进行迭代处理(iterates over these processes). 这一点就是方法和过程之间一个非常本质的差异.
6.2.4 Processes and models
6.2.4 过程和模型
During a development, we create models of the system we are to design. To design these models, we work from a process description that describes the process with which we develop the system. Each such process works with models of the system. These models are expressed, or placed, in a certain information space. Each process takes one or several models and transforms it into other models (see Figure 6.6). The final model should be a complete and tested description of the system. This description normally consists of source code and documentation.
在IT系统的研发过程中, 我们针对计划设计的系统创建需要的模型.为了能够设计这些模型, 我们从一个过程描述开始进行工作, 根据这个过程描述的要求, 我们可以进行IT系统的研发工作. 每一个这样的过程使用这些系统的模型来进行工作Each such process works with models of the system..这些模型可以进行描述,并放置在特殊的信息空间中.每一个过程选取一个或者几个模型,并且将他们转换成其他的模型(见图6.6). 最后的模型就是一个完整的,可以供验证的系统描述资料. 这个资料通常包含源代码和描述文档.
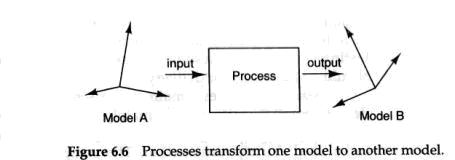
To develop software by transforming models from a requirement specification to source code has founded its own paradigms within software engineering (see Agresti (1986)). Depending on the level at which the transformations are made, they can be divided into either operational or transformational paradigms. The operational paradigm first converts the requirement specification into a totally problem-oriented operational specification which the users can test (see Zave (1984)). Once this is complete and accepted, one can proceed to the implementation factors affecting development. Now, the design and implementation of the system can take place. In the transformational paradigm, the transformations are performed on a much lower level (see Partsch and Steinbruggen (1983)). Each transformation should be proved correct, to guarantee that the final result is also correct. All transformations are saved for administration of the system. Today, one can only develop very small systems (programs) using the basic ideas of this paradigm since it is extremely hard to define correct transformations.
为了能够开发软件系统, 在软件工程领域已经建立了对应的范例paradigms以便实现将需求模型转化为源代码(see Agresti (1986)). 根据软件开发过程中模型转换所处的层面不同, 这些范例可以进一步划分为操作型和转换型operational or transformational paradigms. 操作型范例首先将需求模型转换为一个完全面向问题的操作定义规范, 这个操作定义规范是用户可以进行测试的. 一旦前面的过程已经完成并被客户认可, 系统开发者可以继续分析那些对系统开发可能产生影响的要素. 在这一阶段,可以开始进行系统设计和开发工作. 在对应的转化范例中, 具体的转换工作将会在一个非常低的层面进行(see Partsch and Steinbruggen (1983)). 每一个转化过程需要能够被证实是正确的, 以便保障最后的结果也是正确的. 所有的转换工作都被完整的保留,以便后续对系统进行维护和管理. 在今天, 我们只能在一些小型系统的开发过程中使用这些范例的基本概念, 因为在实际的过程中很难非常精确的定义正确的转换方法.
The transformations in OOSE cannot entirely be associated with either one of these schools. It is, in fact, closely related to the operational approach. In comparison with the transformational approach, it is not as formal, but the design and implementation require a lot of intellectual and creative work. Certain parts can be performed mechanically and thus can be supported by CASE tools.
在OOSE方法中的转化过程无法和上述学院派中的任何一种转换方法直接进行关联. 事实上, OOSE方法和操作型方法非常接近. 和转化型操作方法相比, OOSE方法并不是很正式,然而设计和实施过程需要大量的智力和创造性工作. 而设计过程中的特定工作可以机械的进行执行, 这样一来就可以通过特定的CASE工具来支持.
We can regard the system's requirement specification (and what it really means) as a model, placed in an information space. This information space normally has quite unspecific concepts, that is, they are often not very precise, resulting in the need to clarify what is really meant by the requirement specification. The requirement specification is one-dimensional in the sense that it is often only a textual description, where the references are forwards or backwards in the text. It is also quite usual that one 'forgets' requirements in the requirement specification. Irrespective of all this though, it represents the initial model within our chain of transformations.
我们可以将系统需求规范作为一个模型, 这个模型存在于一个特定的信息空间中.这个信息空间中通常拥有一些非确定的概念(concepts) ,通常这些概念通常不是很精确, 这样一来需求分析人员需要进一步通过完善需求定义文档明确这些概念的确切含义. 需求定义规范往往仅仅是一些文字性的描述, 而需求描述中的一些参考资料需要在文本上前向或者后向查看, 这种描述方法在某种意义上来说是一种一维的描述,.而在实际的情况中, 需求定义者也往往很容易在需求规范书中”忘记”自己需要的一些需求. 而在不考虑所有这些不确定因素, 需求模型代表了整个转换链条中最初始的模型.
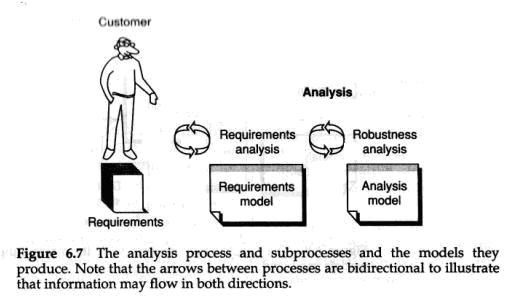
The analysis process produces two models (see Figure 6.7). From the requirement specification, a requirements model is created in which we specify all the functionality of the system. This is mainly done by use cases in the use case model which is a part of the requirement model. The use case model will also form the basis of both the construction and testing processes, and it controls a large part of the system development. We see here a typical example of reuse on a higher level, on a model level, where one model will be used as input to several processes. The requirements model also forms the basis of another model created by the analysis process, namely the analysis model. The analysis model is the basis of the system's structure. In this model, we specify all the logical objects to be included in the system and how these are related and grouped. These two models are the result of the analysis process. They will provide input data for the construction process.
在分析过程中将产生2个模型(见图6.7). 根据需求描述文档资料的描述, 我们将创造一个需求模型 , 在需求模型中我们将定义系统所有需要实现的功能.这个过程主要通过用例模型中详细的用例来定义, 而用例模型是需求模型的一部分. 用例模型也将成为后续构建过程和测试过程的基础, 他将控制IT系统研发的关键部分.在这里,我们将会发现一个在模型层面进行复用的例子, 也就是在一个相对更高的层面, 在这里一个模型将作为其他几个过程的输入对象.需求模型同样也构成分析模型的基础, 分析模型analysis model是分析过程创造的另外一个模型.分析模型是系统体系结构的基础.在分析模型中, 我们将定义系统中所有需要包含的逻辑对象, 以及这些对象是如何相互关联和聚合成群组的.这两个模型就是分析过程的结果. 他们将为后续的构建过程提供输入数据.
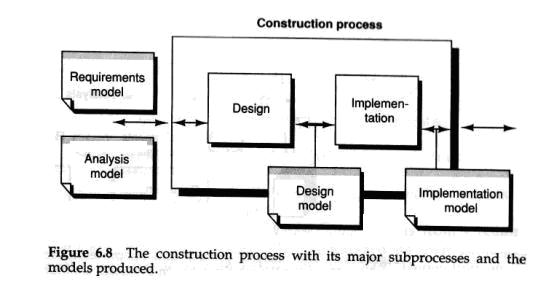
In the construction process, we design and implement the system (see Figure 6.8). We shall see that the requirements model and the analysis model provide much support for this process. First a design is made that results in a design model where each object will be fully specified. The implementation subprocess will then implement these objects and result in the implementation model which consists of the source code.
在构建的过程中, 我们将对目标系统进行设计和实施部署(见图6.8). 我们将会发现前期完成的需求模型和分析模型为构建过程提供了非常多的支持和帮助. 首先要完成一个详细的设计过程开产生一个设计模型, 在设计模型中每一个对象都需要完备的进行定义. 而在后续的实施子过程implementation subprocess中,我们将选用特定的程序语言来实现所有的对象,这样就能够产生实施模型,实施模型中将包括所有的源代码.
This implementation model provides, along with the design and requirements models, input data for the testing process (see Figure 6.9). The testing process tests the implementation model, partly from the requirements model and the design model, and produces a test model. This test model is really the result of testing the implementation model.
需求模型, 设计模型和实施模型一起,将作为测试过程的输入数据(见图6.9).测试过程的主要工作是测试实施模型, 并综合需求模型和设计模型的要素, 并创造一个测试模型. 测试模型就是最终对实施模型进行测试而产生的结果.

These transformations of models are not as mechanical as has been indicated, quite the opposite: the development of these models is an iterative and incremental activity requiring much effort from talented developers. The development work flows over these processes which interact with each other. The processes follow a product and exist as long as the product exists. For a specific project, the issue is to man all or part of these processes. We will come back to this issue in Chapter 15.
这些不同开发过程中等模型转换工作并不是象上面所描述的那样机械, 非常相反, 这些模型的开发过程需要反复的叠代和增量开发活动, 所以需要非常有天赋的开发者的辛勤工作. 开发工作将在这几个主要开发过程中流转, 并且开发工作流程之间需要互相交互. 这些过程将伴随着产品的设计过程, 并在产品的生命周期中存在. 针对一个特定的项目来说, 问题的就在于需要配置上述全部,或者部分的过程. 在第15章中,我们会继续返回讨论这个问题.
As has been discussed, an extremely important characteristic that all our models must support is traceability. We must, from one model, be able to trace an object to an object in another model, and from this new object, be able to return to the same object in the first model, for example, we wish to be able to trace something from the test model when a failure is detected, and find the reason for this failure within the implementation model. We may wish to trace the fault further back to the design and analysis models and also to the requirements model and, perhaps, even to the requirements specification. When we modify a model, we wish to see directly its effect on the other models. This traceability between models can be difficult to maintain manually during the iterative development work. A CASE tool to maintain this traceability is therefore essential for a large development project.
正如前面所讨论的, 我们在软件开发所有过程中产生的所有模型需要支持的一个非常重要的特性是可追踪性.我们必须能够, 从一个模型中的一个对象索引到另外一个模型中存在的对象;同时从这个模型中的新对象, 可以反向的索引回答到前一个模型中的已知的对象.举个例子来说, 假如我们在测试模型中发现了一个错误,我们希望能够进一步跟踪错位的原因, 就必须回溯到实施模型中查找错误的原因.同时我们会希望进一步回溯到设计模型和分析模型,需求模型,甚至是需求规范文档. 有时候在系统开发过程中更新了一个模型, 我们可能希望直接观察这种变更操作对与之关联其他各个模型的影响, 这也需要模型之间可追踪性的支持.在叠代开发的过程中, 通过人工方式维护这种模型之间的可追踪性将会变得非常困难;所以在大型的软件开发项目中,我们需要应用合适的CASE 工具来维护这种可追踪性.
Before we review each model in depth, we shall first discuss several common characteristics for the objects which we use in the models. In the following chapters we shall look at how we work with these models and how they are transformed to new models.
在我们详细的讨论每个模型之前, 我们首先需要讨论一下在这些模型中使用对象的公共特性. 在后续的章节中, 我们将进一步的学习如何利用这些模型进行设计工作, 以及这些模型是如何转换成为新模型.














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









