




 本文介绍了MapReduce编程模型,包括MapReduce的基本概念、运行原理、输入输出处理和Writable接口。通过WordCount实例,详细讲解了如何编写和执行MapReduce作业,从准备数据到生成JAR包,最后展示运行结果。
本文介绍了MapReduce编程模型,包括MapReduce的基本概念、运行原理、输入输出处理和Writable接口。通过WordCount实例,详细讲解了如何编写和执行MapReduce作业,从准备数据到生成JAR包,最后展示运行结果。
1 MapReduce编程
1.1 MapReduce简介
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,用于解决海量数据的计算问题。
MapReduce分成了两个部分:
1、映射(Mapping)对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。
2、化简(Reducing)遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,
每一个Map任务处理输入数据中的一部分,当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。
Reduce任务的主要目标就是把前面若干个Map的输出汇总到一起并输出。
MapReduce的伟大之处就在于编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
1.2 MapReduce运行原理
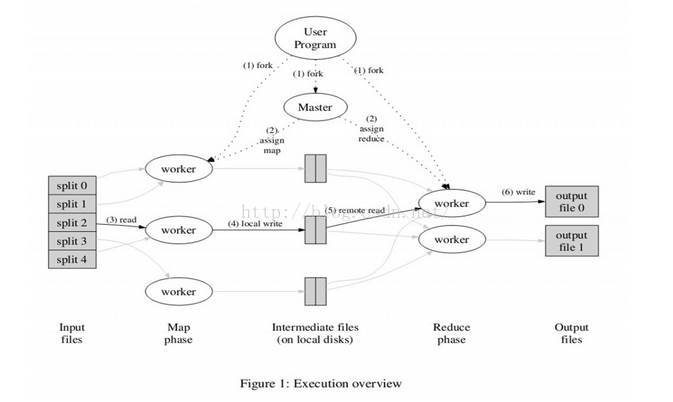
MapReduce论文流程图 - 1.1
一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
1、MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4;然后使用fork将用户进程拷贝到集群内其它机器上。
2、user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业3或者Reduce作业),worker的数量也是可以由用户指定的。
3、被分配了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









