







数据库的事务&事务的ACID特性&四种隔离级别
1、概念
事务是指"作为单个逻辑工作单元"所执行的一系列操作。要么全部执行,要么全部不执行。(也可以简单的理解为事务就是要做或所做的事情)
但并不是所有的操作集合都能称为事务,事务需要满足4个特性(也称为事务的ACID特性)。
2、事务的ACID特性
(1).原子性:事务包含的所有操作要么全部执行成功提交,要么全部执行失败回滚;
(2).一致性:事务执行的结果必须使数据库从一个一致性状态变到另一个一致性状态。
具体什么是数据的一致性,可以根据具体情况来说明:
a.比如有10个人,每个人的银行账号里有5000元,可以互相转来转去,这就组成了一个小型的数据系统,在转账过程中,这10个人的账户总额保持不变,这就满足了数据的一致性。假如A转1000元给B,A的账户减少1000元,而B的账户没有增加1000元,这就是数据不一致的状态。
b.分布式环境下,有一个数据保存在了多个地方,那么在任何时候,这几个地方的数据都必须保持同步,这也可以理解为是数据的一致性。
(3).隔离性:并发执行的多个事务之间是相互隔离、互不干扰的。比如有多个用户操作同一张表,数据库为每个用户开启的事务,都不能被其他的事务所干扰,每个事务感觉不到有其他的事务在并发的执行。
针对事务的隔离性,数据库提供了多种隔离级别,后面我们会专门讲到。
(4).持久性:事务一旦被提交,该事务对数据库所做的更改将持久的保存到数据库中,对数据库所做的改变是永久性的。
总之,事务的各种特性是为了保证数据库执行结果的正确性。
另外,要想使用数据库事务,就要在建表时选择支持事务的存储引擎,如果在建表时不指定存储引擎,则会沿用数据库的存储引擎,MySQL在5.5版本以前的默认引擎是MyISAM,5.5以后是InnoDB(支持事务)
,下面我们来了解一下数据库中的存储引擎。
3、数据库中的存储引擎
数据库的存储引擎&表的存储引擎:类似于全局变量和局部变量,假设数据库的存储引擎为InnoDB,如果没有设置该数据库中表的存储引擎,那么该数据库中的所有表默认使用数据库的存储引擎InnoDB;但如果该数据库中的某张表设置了存储引擎为MyISAM,那么该表的存储引擎为MyISAM。
存储引擎,其实是对使用了该引擎的表进行某种设置,根据所使用引擎的不同,对应表具有不同的存储机制、索引技巧以及锁定水平等。
MySQL数据库支持多种引擎,不同版本的MySQL数据库所支持的引擎也有所区别,查看MySQL支持的引擎,使用命令show engines。我们只有熟悉了各种引擎,才能在软件开发中很好的使用各种引擎,进而最大限度的利用MySQL强大的功能,开发出高性能的软件。
MySQL常用的5种存储引擎:
(1).MyISAM
不支持事务、不支持外键,优点是访问速度快。
对于事务的完整性没有要求,以select、insert操作为主的表可以设置该引擎。引擎设置为MyISAM的表还支持三种不同的存储格式:静态表、动态表、压缩表,此处不再深入,感兴趣的读者可以自行研究。
(2).InnoDB
支持事务、支持外键(MySQL的存储引擎只有InnoDB支持外键约束)。
InnoDB被很多互联网公司所使用,一般来说,如果需要支持事务,并且具有较高的读写频率,InnoDB是不错的选择。
(3).MEMORY
使用Memory引擎的出发点是响应速度。Memory引擎为了得到最快的响应速度,采用的逻辑存储介质是系统内存,虽然在内存中存储表数据确实会有很高的性能,但当进程崩溃时,内存中的数据也会全部消失。另外Memory引擎要求表字段都是长度不变的格式,这意外着Memory表中的字段不能设置为BLOB等长度不确定的格式。
(PS:varchar是一种长度可变的类型,但在MySQL内部被当做长度固定的char类型处理,所以Memory表中的字段是可以设置为varchar类型的)
(4).MERGE
Merge存储引擎把一组MyISAM数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询。构成一个MERGE数据表结构的各成员MyISAM数据表必须具有完全一样的结构。
例如,我们新建12张结构完全相同的表,用来存储1-12月份的服务器日志:log1、log2.....log12,当我们要基于这12张表进行特定条件的查询时,我们可以先将这12张表合并成为一张表,使用如下sql:
CREATE TABLE log_merge
(
dt DATETIME NOT NULL,
info VARCHAR(100) NOT NULL,
INDEX(dt)
) ENGINE = MERGE UNION = (log1, log2, log3, log4,log5...log12);
现在我们基于12张表的查询操作都可以查询log_merge单表,比如我们想查询这12张表中总共有多少记录,可以直接:
select count(1) from log_merge;
(5).ARCHIVE
归档,使用zlib无损数据压缩算法,节省空间,适用于大量历史数据的保存。在归档之后只能对表进行select、insert操作,不支持update、delete操作。在以前归档是不支持索引的,但是自从MySQL5.5开始,ARCHIVE开始支持索引。
4、事务命令
(1).手动开始事务
begin;
start transcation;
(2).提交事务
commit;
(3).回滚事务
rollback;
(4).查询事务的自动提交模式
select @@AutoCommit ;

-- 1表示自动提交已开启,0表示自动提交已禁用;
(5).设置自动提交模式
set AutoCommit=0 ; -- 禁用
set AutoCommit=1 ; -- 开启
(6).查询正在执行的事务
select * from information_schema.InnoDB_trx;
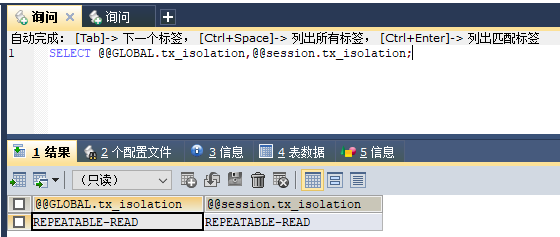
(7).查询事务的隔离级别
select @@global.tx_isolation,@@session.tx_isolation ;
-- 查询结果分别表示全局隔离级别、当前回话的隔离级别
(8).设置事务的隔离级别
#设置当前会话的隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
#设置全局的隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
隔离级别的可设值有(事务的隔离级别在后面专门讲解):
SERIALIZABLE(序列化)
REPEATABLE READ(可重复读)
READ COMMITTED(提交读)
READ UNCOMMITTED(未提交读)
5、脏读、不可重复读、幻读
上面说过,针对事务的隔离性(ACID特性之一),数据库提供了四种隔离级别。
那么数据库厂商为什么要提供这样的四种隔离级别呢?提供这样的四种隔离级别有什么用呢?
事务的隔离级别,是针对多事务并发的情况而言的,是为了解决在多事务并发情况下可能会出现的问题。那我们就来看一下多事务并发情况下可能会出现的问题:
(1).脏读:指一个事务读取到了另一个事务未提交的更新数据。
比如:事务A将某字段值从100修改为200(尚未提交),此时B去读取该字段获取到值200,但是由于某种原因,事务A回滚了,导致B读取到的数据是无效的。
(2).不可重复读:在同一事务中,多次读取同一数据返回的结果不同,也就是说在一个事务中可以读取到另一个事务修改提交的数据。
比如:事务A首先读取了一条数据,在事务A执行逻辑的过程中,事务B修改并提交了该条数据,当事务A再次去读取时,返回的结果和之前读取到的数据不一致。
(3).幻读:在同一事务中,多次查询返回的结果条数不一致,因为在后续读取时,事务A读取到了事务B已提交的insert数据。
比如:事务A要查询表中数学成绩大于90分的记录,第一次查询时返回10条记录,但就在此时,事务B往表中插入了一条数据,也满足数学成绩大于90分,所以当事务A根据同样的条件再次查询时,就会返回11条记录,好像出现了幻觉一样。
区分"不可重复读"&"幻读":
总的来看,两者都表现为两次读取返回的结果不一致。但不可重复读的重点在于update,读取同一数据而两次返回的结果不同;幻读的重点针对insert,同样的条件,两次查询返回的记录条数不一样;另外避免不可重复读"锁行"即可,但是避免幻读需要"锁表"。所以不可重复读和幻读的最大区别,就在于通过锁机制来避免它们时的操作不同。(此处又涉及到锁,锁的知识会在后面专门讲解)
通过上面学习我们知道,在多事务并发时,可能会出现脏读、不可重复读、幻读,而四种隔离级别的设计,就是为了解决脏读、不可重复读、幻读的。
6、事务的隔离级别
数据库事务的4种隔离级别由高到低分别为:
Serializable(序列化)——>Repeatable read(可重复读)——>Read committed(提交读)——>Read uncommitted(未提交读)
四种隔离级别解决脏读、不可重复读、幻读的对应关系如下表:
√:可能出现 ×:不会出现
| 脏读 | 不可重复读 | 幻读 | |
| Serializable(序列化) | × | × | × |
| Repeatable read(可重复读) | × | × | √ |
| Read committed(提交读) | × | √ | √ |
| Read uncommitted(未提交读) | √ | √ | √ |
注意:隔离界别并不是越高越好,隔离级别越高,数据库性能越低。
(1).Serializable(序列化):多个事务串行化顺序执行,事务并发时可能出现的三种问题(脏读、不可重复读、幻读)都可避免,但效率很底,可能导致大量超时,一般不用。
(2).Repeatable read(可重复读):可以防止脏读&不可重复读,但是可能会出现幻读。
Repeatable read是MySQL的默认隔离级别。
(3).Read commited(提交读):可以防止脏读,但是可能会出现不可重复读&幻读。
Read commited是Oracle、SqlServer的默认隔离级别。
(4).Read uncommited(未提交读):级别最低,三种问题都有可能出现。
另,关于查询数据库事务的隔离级别、设置隔离级别(当前回话/全局)的SQL,我们在上面已经说过,往上翻翻就能看到。
还有四种隔离级别通过锁的实现机制,将会在下篇文章
《数据库的锁机制》中专门说明。
感兴趣的小伙伴可以关注一下博主的公众号,1W+技术人的选择,致力于原创技术干货,包含Redis、RabbitMQ、Kafka、SpringBoot、SpringCloud、ELK等热门技术的学习&资料。















 5313
5313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









