







最近看了一篇文章,是讲如何通过命令行,把mysql中的数据导入到redis中的。
文中作者的思路是用sql语句来构建redis的命令,然后mysql执行这个sql语句,把sql语句的输出结果,通过管道输出到redis的客户端程序执行这些命令,从而把数据加载到redis。
原文作者用的是linux系统,而本文用的是windows,数据库用的是SQL Server,这个是最大的区别,所以具体的命令行也是完全不一样的。
关于redis的安装,可以参考我的前一篇文章:
【Redis学习点滴】Windows下的Redis安装、测试就是这么简单
1、准备工作。
这里新建了一个数据库TEST,然后切换到test数据库。
创建了一张表test,其中有3个字段,这里用的到是user_name和value两个字段,存储的是某个用户的账户余额,插入6条数据。
--创建一个数据库TEST
create database TEST;
use test
go;
--创建Test表
create table test
(
user_id int primary key,
user_name varchar(30),
value numeric(10,2)
);
insert into test
select 1,'alice',100.2
union all
select 2,'grace',100.2
union all
select 3,'eili',100.2
union all
select 4,'mandy',100.2
union all
select 5,'sophie',100.2
union all
select 6,'jerry',100.2
select * from test
2、通过select语句构建redis命令
首先要说的是这里要构建的是redis的hset命令,也就是把数据库表中的数据导入redis时,用的是hash类型来存储数据的。
redis中当我们要把数据存储到hash中时,具体的命令是这样的:
hset test 键名称 键值
这里在c盘下,创建了名为:s.sql 的文件,文件中的sql语句如下:
set nocount on;
select 'HSET '+'test '+user_name+' '+cast(value as varchar)
from test注意,这里的set nocount on是设置sql语句执行时,不返回消息,因为这些消息也会作为redis命令来运行,所以会导致redis执行报错。
这个sql语句中,hset是redis中设置散列的命令,test是这个散列的名称,那么user_name的值就是这个散列中的一个key,而value就是这个key对应的值。

3、通过sqlcmd命令行运行sql
对于mysql来说,你可以用mysql客户端命令 mysql来运行sql语句,而对于sql server,我是用sqlcmd命令行来运行文件中的sql的。
这里为了做实验,把输出结果放到一个文件中,具体的命令行如下:
C:\Users\Administrator>sqlcmd -S ggg-pc\sql2014 -U sa -P ggg -d Test -h -1 -i c:\s.sql > c:\c.txt这里稍微解释一下sqlcmd命令行参数:
-S:服务器,这里的ggg-pc是服务器名称,sql2014是实例名称,一般如果在同一个机器上安装了多个sql server时候,用于区分不同的实例
-U:用户名
-P:密码
-d:数据库名称
-h:当为-1时,运行结果中不输出字段名称
-i:要运行sql文件
>:这个是重定向,本来输出结果是打印到屏幕上的,现在重定向到 c.txt文件中。
查看c盘下的c.sql文件:

4、把sql的输出结果直接通过管道,输出到redis-cli客户端程序。
命令如下:
C:\Users\Administrator>sqlcmd -S ggg-pc\sql2014 -U sa -P yupeigu -d Test -h -1 -i c:\s.sql | e:\redisbin_x64\redis-cli
(integer) 1
(integer) 1
(integer) 1
(integer) 1
(integer) 1
(integer) 1从返回值来看,都是返回的1,说明值都写入成功了。
接下来,启动redis-cli客户端程序,在redis中查看这些值:
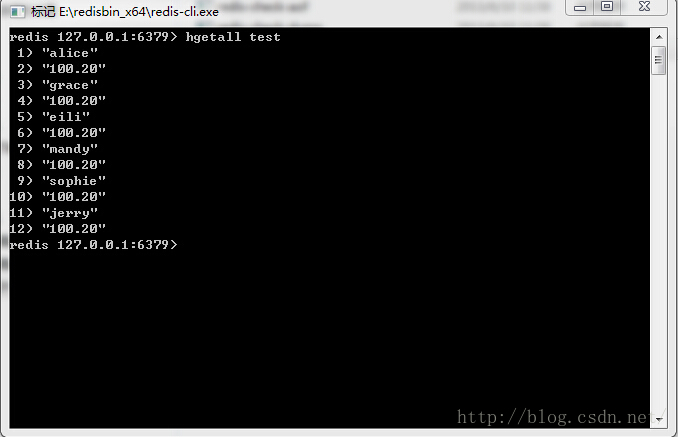
从上图可以看出,数据已经从sql server中的Test数据库,导入到redis中 。
。















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









