







如何实现Oracle9iRealease2的全文检索
|
|
|
|
|
|
|
|
Oracle一直致力于全文检索技术的研究,目前我们使用较多的Oracle9i Rlease2,Oracle数据库的全文检索技术已经非常完美,而且配置使用是相当方便的。
Oracle9i使用Oracle Text实现全文检索的功能及管理,在Oracle8(i)是Oracle interMedia Text,在8(i)之前是Oracle ConText Cartridge。Oracle Text提供了一个图形化的管理工具Oracle Text Manager来管理和创建全文检索索引,所有的操作可以生成相应的SQL语句,可以通过观察SQL语句学习如何用SQL建立全文检索的各种操作。
Oracle Text具备强大的文本检索能力和智能化的文本管理能力:它支持Oracle数据库本身支持的大部分语言,包括中文;它支持包括word,excel,pdf,html,xml,text等在内的大部分常用的文件格式;它可以对varchar2,blob,clob等字段进行检索,可以将文件以二进制字节方式放在blob字段进行检索;也可将文件放在磁盘文件系统,通过varchar2字段做路径映射,实现文件的检索。
1. 部分概念及原理
首选项:
所谓的首选项实际上是配置全文索引的属性,在
Oracle Text里,这些配置项已经做的比较成熟,比较重要的首选项有“过滤器”“语言指定器”“数据存储”。就首选项本身来说,在Oracle Text Manager中也可根据具体应用的需要进行一定程度的定制。
数据存储:
数据存储指最终的文本存放的位置。搜索时,读取列中的数据,通常,这些列数据就是文本内容,但有是这些数据只作为文档内容的指针,指向文档内容所在的存储位置。例如,
FILE_DATASTORE 将列数据作为文件名称的路径使用。
数据存储包括以下可选类型:
DIRECT_DATASTORE,FILE_DATASTORE,URL_DATASTORE,MULTI_COLUMN_DATASTORE,DETAIL_DATASTORE,USER_DATASTORE。
过滤器:
过滤器是全文检索中重要组件,实际上全文检索中识别各种文档格式就是由过滤器完成,它可以从它所支持的文件格式中将文本内容部分过滤出来提供给词法分析器生成索引。
其中ORACLE Text中可选的过滤器包括:NULL_FILTER,CHARSET_FILTER,PROCEDURE_FILTER,USER_FILTER以及最常用的INSO_FILTER。
一般而言,我们使用INSO_FILTER,这个过滤器可以从WORD,PDF,PPT,EXCEL等二进制的文件中过滤出文本。并能过滤混合格式的列。
值的一提的是,过滤器是把二进制文件的文本内容直接过滤出来,所以使用INSO_FILTER时对文本型的文件是无效的,如TXT,HTML,RTF,XML等。但使用INSO_FILTER时,ORACLE Text提供了一个选项,可以通过一个列值标示此行的数据是否二进制的内容,从而进行过滤时,ORACLE Text 可以绕过INSO_FILTER直接进行词法分析。下述的实验会做进一步介绍。
语言指定器(即词法分析器):
词法分析器是全文检索核心部件,它标识文本使用的语言,还确定在文本中如何标识标记,进而将文本拆分为一系列的单词,记录在以DR$开头的几个表中,达到生成索引的效果,其中。文本拆分机制决定了全文检索的效率。
对于中文,
Oracle Text提供给简体中文有两种语法分析器,CHINESE_VGRAM_LEXER和CHINESE_LEXER。其中CHINESE_VGRAM_LEXER支持所有的中文字符集,缺点是文本拆分比较原始,会产生大量中文不会出现的词语,因此会在增加大量无效的单词记录;CHINESE_LEXER是新增的中文语法分析器,它能识别大量中文的词汇,断词比较精确,
避免
CHINESE_VGRAM_LEXER的缺点,但是在8i它只支持UTF8,而我们使用的字符集一般是ZHS16GBK。这次通过试验表明,9iRlease2中的CHINESE_LEXER是可以支持ZHS16GBK,可创建CHINESE_LEXER的索引,通过比较表明,它生成的单词记录比用CHINESE_VGRAM_LEXER生成的单词记录少一半以上,同时这个比率会随记录的增多而继续提高。
以下介绍将各种文件放在
blob字段的设置及检索方式:
2. 预备工作
1.
先在信息发布方案库
(如stpublish)建立一个表pu_db_search,建立语句如下:
create table pu_db_search (
doc_seq
varchar2(20) not null,
i_file_type
NUMBER(2) not null,
vc_file_name
varchar2(500) not null,
vc_search_type
varchar2(50),
vc_file_desc
varchar2(4000),
file_content
BLOB,
constraint PK_PU_DB_SEARCH primary key (doc_seq, i_file_type, vc_file_name)
)
说明:
doc_seq 信息记录编号;
file_content字段用于将整个文件存放在此字段。我们将在file_content字段,实现配置对BLOB字段的全文索引;
i_file_type 文件类型 0为正文,1为附件;
vc_file_name字段用于存放文件名称;
vc_search_type字段是一个辅助字段,值为”TEXT”或“BINARY”。ORACLE TEXT在建立索引前需要通过“过滤器”来从不同格式的二进制文件(如WORD,PDF,EXCEL)中过滤出文本部分。而对于纯文本则必须绕过“过滤器”,否则会被忽略掉。因此,在使用““过滤器”时,ORACLE TEXT提供了一个“格式列”的选项,列值如果为“TEXT”,ORACLE TEXT会绕过“过滤器”。
vc_file_desc 描述。
2.
Oracle Text的配置有完整的DDL支持,同时Oracle提供了一个图形化的配置工具,Oracle Text Manager。此外,Oracle Text 必须使用CTXSYS账户或具备CTXAPP角色的账户。启动Oracle Text Manager的过程如下:
1)
在
Oracle Enterprise Manager 以DBA的身份为用户CTXSYS重设密码,并赋予DBA角色。
2)
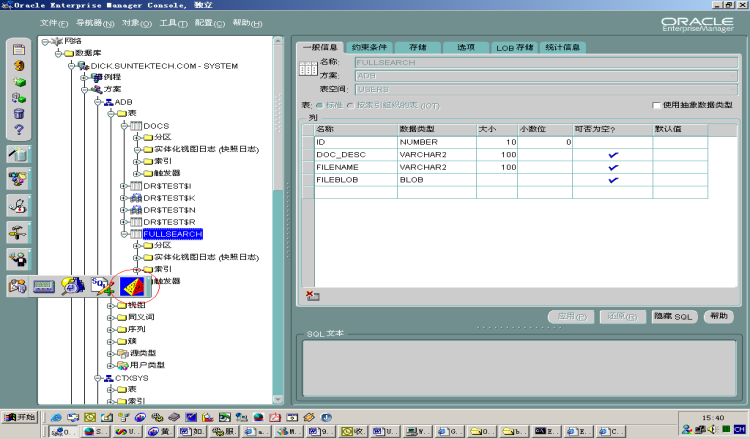
在
Oracle Enterprise Manager中的工具条菜单Text Manager按钮菜单打开Text Manager管理器,如下图:
3. 配置对BLOB字段的全文索引
a)
以
ctxsys用户登陆Oracle Text Manager。
b)
点击索引
àCONTEXT
à右键选择“创建。。。”,弹出图所示窗口。
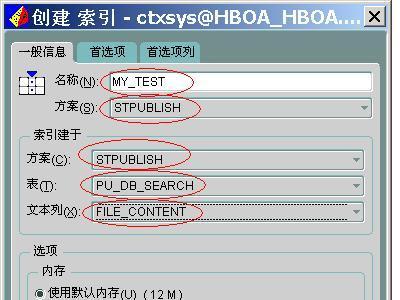
这里根据实际情况输入,红圈是需改动的域,相关域解释如下:
名称:全文索引名。 (
MY_TEST)
方案:拥有该索引的方案。 (即需索引的表所在的方案如
stpublish)
索引建于:
方案:拥有表的方案,该表包含在其上创建此索引的列。(与上一项相同)
表:包含在其上创建此索引的列的表。(就是
pu_db_search表了)
文本列:在其上创建此索引的列。该列包含要处理的文档
(行) 的文本。可以是单列文本关键字,也可以是经过编码的组合 (多列) 文本关键字的说明。(就是file_content字段了)
c)
点击
[首选项]TAB页,进行首选项的配置。如下图:
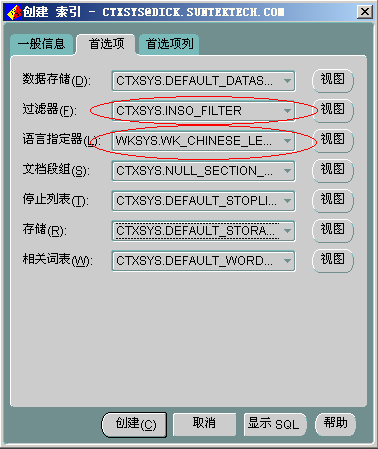
过滤器中选择CTXSYS_INSO_FILTER。
语言指定器(即词法分析器)选择WKSYS.WK_CHINESE_LEXER。
d)
点击
[首选项列]TAB页,进行首选项的配置。如下图:
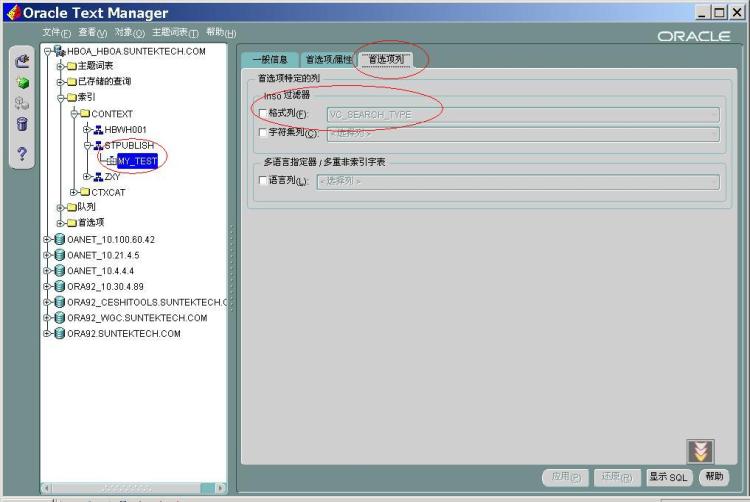
钩中格式列,并从下拉列表中选择前述的“
vc_search_type”作为格式列。
e)
点击创建后,
Oracle Text将开始生成基于字段file_content所存内容全文检索的索引。
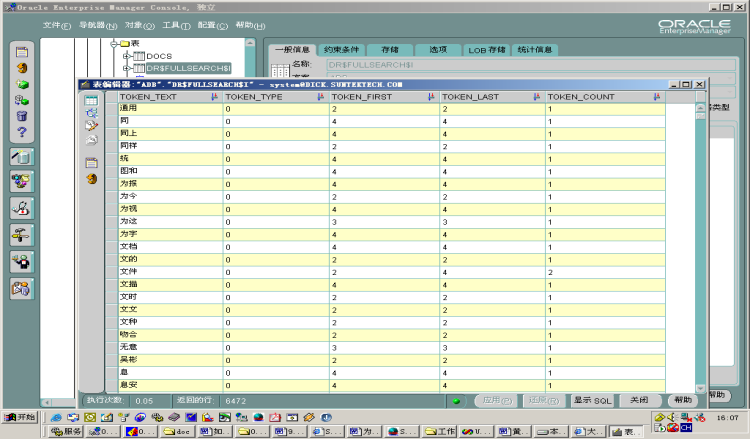
生成完毕后,可在方案下多了
DR$开头的几个表,其中DR$MY_TESTI表保存的就是文本拆分的记录,如图:
f)
使用以下
Sql语句简单验证全文索引的效果:
|
SELECT * FROM pu_db_search WHERE contains(
file_content,’管理’)>0
|
|
请注意contains的参数字段为
file_content
,表示对
file_content
的全文检索
|
4. 全文搜索索引的更新同步、优化与索引重建
以下的语句全部实验通过
:
4.1. 同步、优化及定期同步优化
同步(sync):根据新增记录的文本内容更新全文搜索的索引。
同步语法:
|
begin
ctx_ddl.sync_index('STPUBLISH.MY_TEST' );
end;
|
优化(optimize):根据被删除记录清除全文搜索索引中的垃圾。
优化语法:
|
begin
ctx_ddl.optimize_index('STPUBLISH.MY_TEST', 'FAST');
end;
|
(在ORACLE Text Manager中可直接通过图形化界面做同步和优化操作,但我发现经常没有作用,不知道为什么。但通过直接用sql 工具运行 ddl语句,实验通过)
定期同步优化
前提:
该功能需要利用oracle的JOB功能来完成。
因为oracle9I默认不启用JOB功能,所以首先需要增加ORACLE数据库实例的JOB配置参数:
假设数据库实例为OANET,则打开oracleHome$/admin/oanet/pfile目录下的init.ora文件,增加如下参数:
###########################################
# JOB 配置参数
###########################################
job_queue_processes=5
保存该文件后然后重新启动oracle数据库服务和listener服务。
同步和更新用以下的两个
job来完成(该job要建在和表同一个用户如stpublish下,):
A、用DBA用户对job所在数据库方案用户如stpublish赋权:
grant execute on dbms_job to stpublish;
B、
--同步 sync:
|
variable jobno number;
BEGIN DBMS_JOB.SUBMIT(:jobno,'ctx_ddl.sync_index(''STPUBLISH.MY_TEST'');', SYSDATE, 'SYSDATE + (1/24/4)'); commit; END; |
-- 优化optimizer
|
variable jobno number; begin DBMS_JOB.SUBMIT(:jobno,'ctx_ddl.optimize_index(''STPUBLISH.MY_TEST '',''FULL'');', SYSDATE, 'SYSDATE + 1'); commit; END; |
其中, 第一个
job的SYSDATE + (1/24/4)是指每隔15分钟同步一次,第二个job的SYSDATE + 1是每隔1天做一次全优化。具体的时间间隔,可以根据应用的需要而定
4.2. 索引重建
重建索引会删除原来的索引,重新生成索引,需要较长的时间。
重建索引语法如下:
|
ALTER INDEX STPUBLISH.MY_TEST REBUILD;
|
据网上一些用家的体会,
oracle重建索引的速度也是比较快的,有一用家这样描述:
|
Oracle 的全文检索建立和维护索引要比ms sql server都要快得多,笔者的65万记录的一个表建立索引只需要20分钟,同步一次只需要1分钟。
|
因此,也可以考虑用
job的办法定期重建索引。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









