









一、集合的排列
给定一个集合S,含有n个不重复的元素,输出该集合元素的所有排列,leetcode对应题目为:http://oj.leetcode.com/problems/permutations/。打印所有排列的复杂度为O(n*n!),因为共有n!个不同的排列,打印每个排列的复杂度为O(n)。打印所有的排列一般采用深搜策略,先给出一个常规的方法:
void perm(int start,int end,vector<int> &num,vector<vector<int>> &result)
{
if(start==end)
{
result.push_back(num);
return;
}
for(int i=start;i<=end;i++)
{
swap(num[start],num[i]);
perm(start+1,end,num,result);
swap(num[start],num[i]);
}
}该代码可看成是标准深搜的一个具体实例:
void DFS(int i,int n,…)
if i=n
print;
return;
for j=i to k do
DFS(j,n,…);深搜的第一步是判断是否已经达到递归结束的条件,之后针对不同的解空间进行递归。在某些情况下,在递归之前也伴随着剪枝,以加速算法的执行速度。上述保存集合排列的代码思想很简单:将起始位置的元素置成集合的每一个元素,然后递归下一个位置。该问题的解空间是一个排列树。例如,针对集合{1,2,3}的解空间为:
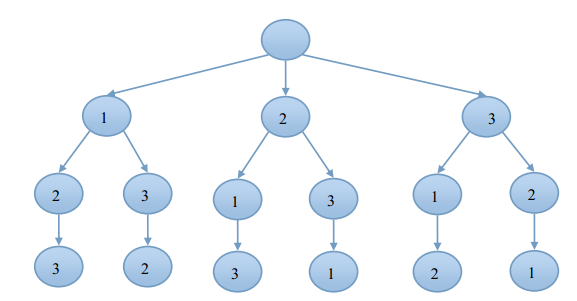
图1排列树形式的解空间
排列树形式的解空间有个规律,就是随着递归深度的增加,每个节点的子节点个数都逐次减一,这也是为什么排列算法的复杂度是O(n!)。
此外,还有一种生成排列的方法,思想不太好懂,下面只给出代码:
void perm(int n,vector<int> &num,vector<vector<int>> &result)
{
if(n==1)
{
result.push_back(num);
return;
}
for(int i=0;i<n;i++)
{
perm(n-1,num,result);
if(n%2!=0)
{
swap(num[0],num[n-1]);
}
else
{
swap(num[i],num[n-1]);
}
}
}算法正确性证明的基本思想是:数组长度n为奇数时,操作完成后,数组不变,n为偶数时,操作完成后,数组循环右移一位。
二、集合的k元素子集
给定一个集合S,含有n个不重复的元素,生成所有的含有k个元素的子集,也即求组合数,leetcode对应题目为: http://oj.leetcode.com/problems/combinations/。该问题也可以通过深搜完成,在写代码之前先分析一下其解空间的构造。针对每一个元素,我们都有两种选择:选择该元素或者不选该元素,由此问题的解空间是一棵二叉树。例如,对集合{1,2,3},选择2个数的子集的解空间如下图: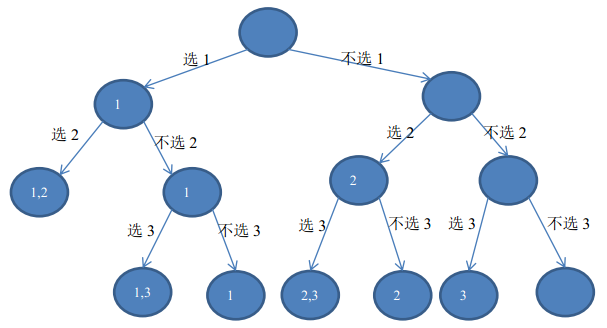
图2 子集树形式的解空间
根据上面的分析,我们可以知道求k个元素的子集,我们只需要判断当前已经选择的元素个数,如果已经选择了k个元素,则找到一个符合的子集,无需再遍历子节点。如果尚未选择k个元素,但是已经达到叶节点(n个元素已经判断一遍),我们可以直接返回,这说明此次的遍历没有找到符合的子集。按照这个思路,代码如下:
void com(int depth,int n,int k,vector<int>& r,vector<vector<int> >& result)
{
if(r.size()==k)
{
result.push_back(r);
return;
}
if(depth==n) return;
r.push_back(depth+1);
com(depth+1,n,k,r,result);
r.pop_back();
com(depth+1,n,k,r,result);
}其中参数depth表示当前深度,参数n表示最大深度,参数k表示当前保存的元素个数。如上所述,代码有两个终止条件:找到符合的子集,或者达到叶节点。遍历时,只需要考虑两种情况:选择该元素或者不选该元素,然后遍历下一层节点。
上述代码是最原始的代码,因为提交已经AC,所以无需再做优化,但实际上代码还可以有很大的优化余地。事实上,在某些路径中,我们无需遍历到叶节点也可以知道后面的遍历是不符合要求的,如果需要添加的元素个数大于剩余路径上所有元素的个数,则即使添加剩余所有的元素也不符合要求,此时我们可以直接进行剪枝,避免不必要的搜索。如果不剪枝复杂度最坏为O(2n),剪枝之后的复杂度为O(nk)。
此外,针对java和C++两种编程语言,代码稍有区别:
void com(int depth,int n,int k,ArrayList<Integer> r,ArrayList<ArrayList<Integer>> result)
{
if(r.size()==k)
{
result.add(new ArrayList<Integer>(r));
return;
}
if(depth==n) return;
r.add(depth+1);
com(depth+1,n,k,r,result);
r.remove(r.size()-1);
com(depth+1,n,k,r,result);
}这里需要特别注意的地方是代码:result.add(new ArrayList<Integer>(r));。这个地方添加结果的时候是新建了一个ArrayList,而C++是直接添加vector。如果这个地方我们不新建,则将返回空集,这是因为Java中对ArrayList的操作是引用类型,如果不新建则始终都是对一个ArrayList进行操作。一开始的ArrayList是空集,操作完成之后还是空集。C++的push_back是复制一份新的vector到vector<vector>中,不存在对同一个引用进行操作的问题。
在《挑战程序设计竞赛》一书的157页,有介绍一种非递归枚举{1,2,…,n}所包含的所有大小为k的子集的方法。有兴趣的读者可自行阅读,下面只给出代码:vector<vector<int> > combine(int n, int k) {
vector<vector<int> > result;
int comb= (1<<k)-1;//comb是每一个k元素的子集,从0…01…1开始
while(comb<1<<n)
{
vector<int> r;
for(int j=0;j<n;j++)
{
if(comb>>j&1)
{
r.push_back(j+1);
}
}
result.push_back(r);
int x=comb&-comb,y=comb+x;
comb=((comb&~y)/x>>1)|y;
}
return result;
}三、集合的所有子集
问题二只求集合的k元素子集,现在要求集合的所有子集,leetcode对应的题目为:http://oj.leetcode.com/problems/subsets/,该问题更加简单,只需要将图2的子集树完整遍历一遍即可,从根节点到叶节点的每一条路径都表示一个可能的子集。代码如下:
void sub(int depth,vector<int> &S,vector<int>& r,vector<vector<int>>& result)
{
if(depth==S.size())
{
result.push_back(r);
return;
}
r.push_back(S[depth]);
sub(depth+1,S,r,result);
r.pop_back();
sub(depth+1,S,r,result);
}与问题二的区别是,不需要考虑当前已经保存的元素个数,只需要判断是否已经到达叶节点。当然,我们也可以通过遍历一个数的二进制来获得集合的所有子集。
vector<vector<int> > subsets(vector<int> &S) {
sort(S.begin(),S.end());//给定的集合可能未排序
vector<vector<int>> result;
for(int i=0;i<1<<S.size();i++)//每一个二进制数都是一个子集
{
vector<int> r;
for(int j=0;j<S.size();j++)//获得为1的位置
{
if(i>>j&1)
{
r.push_back(S[j]);
}
}
result.push_back(r);
}
return result;
}上述三个问题都可以通过深搜完美解决,后两个问题还可以通过位运算解决,不管是深搜还是位运算都有比较相似的模式,希望通过上面的分析,大家能深刻理解深搜和位运算。














 6799
6799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









