









小问题鼓捣了一天,本来想写一个简单的客户端和服务器通信的程序,结果出现了各种问题。
问题1.版本问题
首先上网找了一段客户端代码,如下:
import socket
# 创建一个socket:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect(('www.sina.com.cn', 80))
# 发送数据:
s.send('GET / HTTP/1.1\r\nHost: www.sina.com.cn\r\nConnection: close\r\n\r\n')
# 接收数据:
buffer = []
while True:
# 每次最多接收1k字节:
d = s.recv(1024)
if d:
buffer.append(d)
else:
break
data = ''.join(buffer)
# 关闭连接:
s.close()
header, html = data.split('\r\n\r\n', 1)
print header
# 把接收的数据写入文件:
with open('sina.html', 'wb') as f:
f.write(html)这个应该是Python2.X的代码,放在Python3.X第一个出错的地方在‘发送数据’那,
s.send(''GET / HTTP/1.1\r\nHost: www.sina.com.cn\r\nConnection: close\r\n\r\n'')(这里报错是:TypeError: 'str' does not support the buffer interface),
在Python3.X要是看文档的话,你会发现socket.send(bytes[,flags])参数是bytes,不是str,所以修改的办法是s.send(''GET / HTTP/1.1\r\nHost: www.sina.com.cn\r\nConnection: close\r\n\r\n''.encode()). str.encode()方法是将str转换为bytes,同时加上编码,默认是utf-8,具体参数可以help(str)看一下。
第二个出错的地方在'data=''.join(buffer)'(这里报的错是:TypeError: sequence item 0: expected str instance, bytes found),错误的原因是buffer这个list里每个元素应该是str,但是却出现了bytes,导致这个错误的原因是在上面'd=s.recv(1024)',同样要是看3.X的文档的话,s.recv(1024)返回的也是bytes,所以解决这个问题的办法是在每个d添加到buffer之前转化为str,bytes转化str也有个方法,bytes.decode()(这样直接decode,不设置里面参数可能会出现乱码问题,具体看问题2),具体的可以查看下help(bytes),所以上面修改的代码为'buffer.append(d.decode('gb2312',))'(这样改完,后面还有可能会报错),注意这里的编码和你具体抓取的网页有关,新浪首页的网页编码是gb2312.(怎么看一个网页是以什么编码的呢?首先打开要抓取的页面,然后看该页面的html,下面我们以优酷为例,用chrome看网页源码)
(1).这是优酷首页
(2)在页面某处点右键-点审查元素(其他浏览器看html方法可以百度一下,这个是chrome的),然后是下面的界面
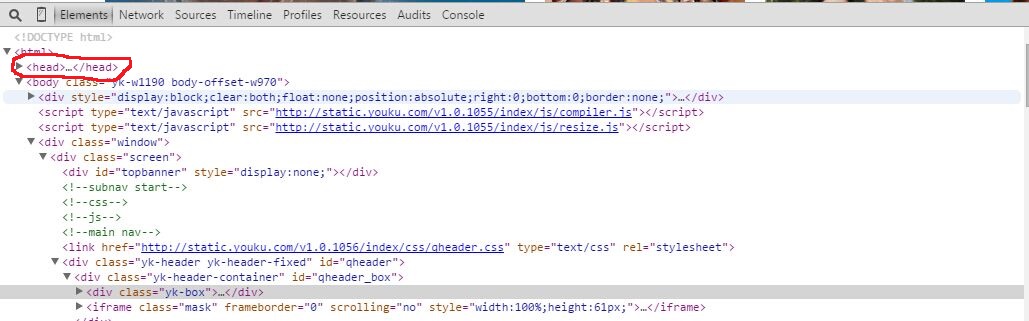
注意画圈的地方,就是head,里面就有你想要的信息,head是和网页正文一起返回给浏览器的,head里面有一些元信息,然后点开head
(3)点开head
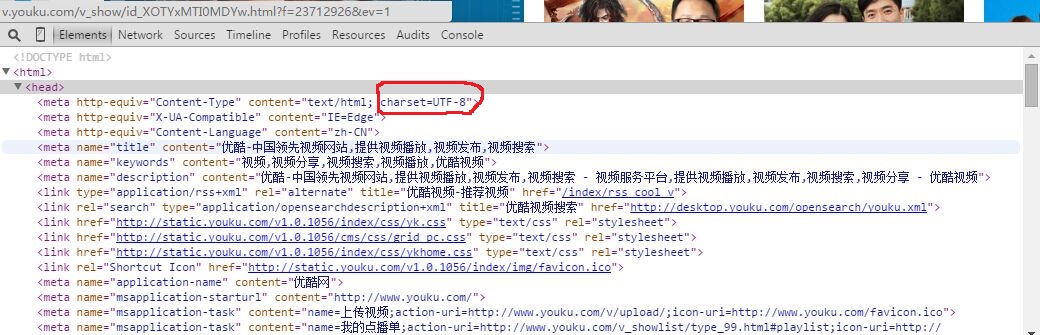
charset=UTF-8就是网页的编码,浏览器也是根据这个编码将相应的网页进行解码
问题2.编码问题
上面的程序按着刚才的方法改好后,一运行又报错(赶上点正可能也不报,比如请求网页的时候返回来个‘403’,因为这个返回的html里面没有中文,没有一些写错的符号,在用gb2312解析的时候没有问题),报错的原因是这个(UnicodeDecodeError: 'gb2312' codec can't decode byte 0x87 in position 219076: illegal multibyte sequence,要是抓取的网页用'utf-8'解析的话可能报这个UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 188: invalid continuation byte),这个问题困扰了我很长时间,一直在想编码也选对了,怎么会有这种情况,各种百度谷歌,后来不经意发现了这篇文章,他说“这 是因为遇到了非法字符——尤其是在某些用C/C++编写的程序中,全角空格往往有多种不同的实现方式,比如\xa3\xa0,或者\xa4\x57,这些 字符,看起来都是全角空格,但它们并不是“合法”的全角空格(真正的全角空格是\xa1\xa1),因此在转码的过程中出现了异常。”搜嘎,于是又把上面的buffer.append()又改成了buffer.append(d.decode('gb2312',errors='ignore')),ignore意思是解析时候遇上非法字符直接忽略,乌云散开了,于是又运行,WTF,又报错,这会问题出现在最后一行f.write(html),报的错是:TypeError: 'str' does not support the buffer interface,当然这个不是编码问题了,这个是因为在open('sina.html','wb')时候以二进制方式(Binary files)写,参数'wb'中的w代表写,b代表binary模式(文档),所以只要把代码改成f.write(html.encode())就可以了,接下来再运行就应该没问题了。下面是我的代码
def fun():
url="www.sina.com"
# url1="www.baidu.com/s?word=%E5%B0%8F%E7%8C%AB&tn=sitehao123&ie=utf-8"
s=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# print(s.connect_ex((url,80)))
s.connect((url,80))
s.send('GET / HTTP/1.1\r\nHost: www.sina.com.cn\r\nConnection: close\r\n\r\n'.encode())
buffer=[]
while True:
d=s.recv(1048576)
print(d)
print(d.decode('gb2312',errors='ignore'))
if d:
buffer.append(d.decode('gb2312',errors='ignore'))
else:
break
data=''.join(buffer)
# print('buffer type: ',type(buffer))
print(data)
print('data type: ',type(data))
s.close()
header,html=data.split('\r\n\r\n', 1)
print(header)
with open('baidu.html',mode='wb') as f:
f.write(data.encode('gb2312',errors='ignore'))
这是因为浏览器在提取head里面信息的时候,获得的是'gb2312'而程序写入文件时候的编码是'utf-8'导致的,有两种方法可以改:
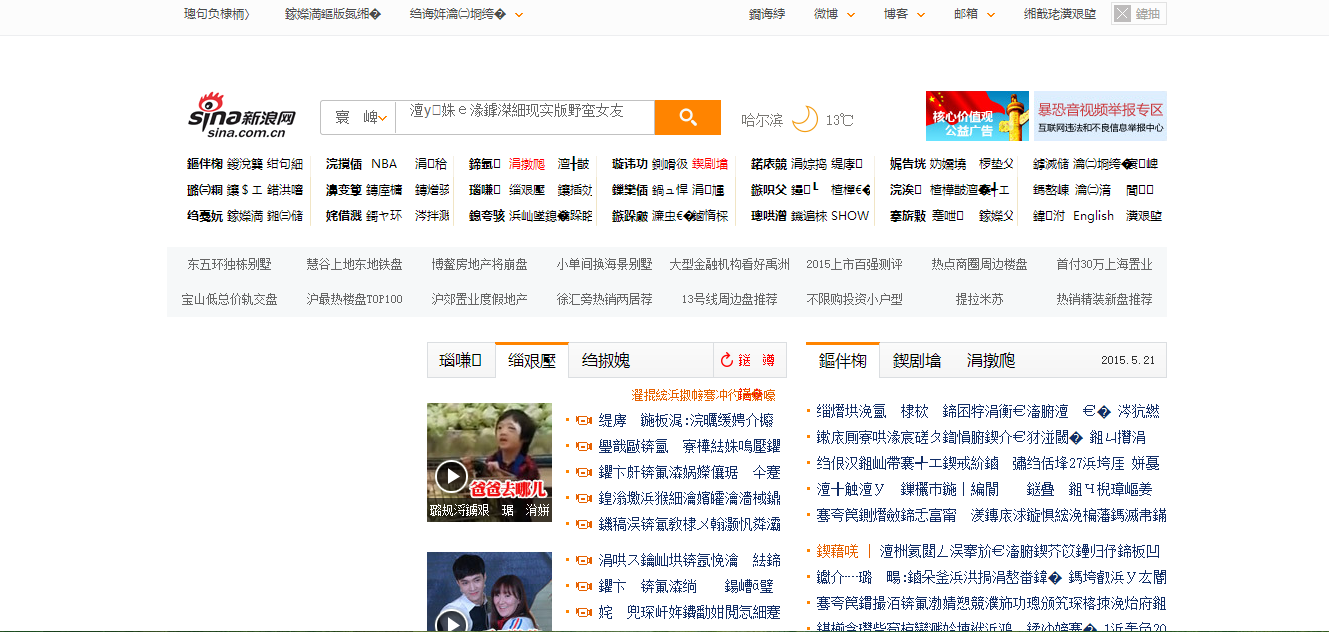
第一种:把写入文件的html里的head里面的charset='gb2312'改成utf-8
第二种:写入文件的时候直接'gb2312'编码,data.encode('gb2312')
基本就这些了,有错误的地方欢迎指正。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









