







集群是redis提供的分布式数据库方案,通过分片(sharding)来进行数据共享,并提供复制和故障转移功能。
1. 节点
一个redis集群由多个节点(node)组成。
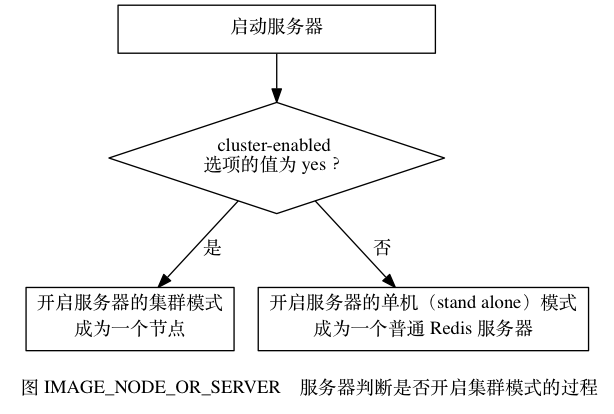
一个节点就是一个运行在集群模式下的redis服务器,redis服务器咋启动时根据cluster-enabled配置选项是否为yes来决定是否开启服务器的集群模式。
CLUSTER MEET命令:连接各个节点。向一个节点node发送CLUSTER MEET命令,可以让node节点与ip和port指定的节点进行握手,当握手成功时,node节点就会将ip和port所指定的节点添加到node节点当前所在的集群中。
CLUSTER MEET <ip> <port>CLUSTER NODES命令:查看当前集群的节点。
1.1 启动节点
一个节点就是一个运行在集群模式下的redis服务器,redis服务器咋启动时根据
cluster-enabled配置选项是否为yes来决定是否开启服务器的集群模式。
节点(运行在集群模式下的 Redis 服务器)会继续使用所有在单机模式中使用的服务器组件,
节点会继续使用 redisServer 结构来保存服务器的状态, 使用 redisClient 结构来保存客户端的状态, 至于那些只有在集群模式下才会用到的数据, 节点将它们保存到了 cluster.h/clusterNode 结构, cluster.h/clusterLink 结构, 以及 cluster.h/clusterState 结构里。
1.2 集群数据结构
cluster.h/clusterNode 结构,保存了节点状态。
每个节点使用一个clusterNode结构来记录自己的状态,并为集群中的所有其他节点(包括主节点和从节点)都创建一个相应的clusterNode结构,以此来记录其他节点的状态:
// 节点状态
struct clusterNode {
// 创建节点的时间
mstime_t ctime; /* Node object creation time. */
// 节点的名字,由 40 个十六进制字符组成
// 例如 68eef66df23420a5862208ef5b1a7005b806f2ff
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
// 节点标识
// 使用各种不同的标识值记录节点的角色(比如主节点或者从节点),
// 以及节点目前所处的状态(比如在线或者下线)。
int flags; /* REDIS_NODE_... */
// 节点当前的配置纪元,用于实现故障转移
uint64_t configEpoch; /* Last configEpoch observed for this node */
// 由这个节点负责处理的槽
// 一共有 REDIS_CLUSTER_SLOTS / 8 个字节长
// 每个字节的每个位记录了一个槽的保存状态
// 位的值为 1 表示槽正由本节点处理,值为 0 则表示槽并非本节点处理
// 比如 slots[0] 的第一个位保存了槽 0 的保存情况
// slots[0] 的第二个位保存了槽 1 的保存情况,以此类推
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
// 该节点负责处理的槽数量
int numslots; /* Number of slots handled by this node */
// 如果本节点是主节点,那么用这个属性记录从节点的数量
int numslaves; /* Number of slave nodes, if this is a master */
// 指针数组,指向各个从节点
struct clusterNode **slaves; /* pointers to slave nodes */
// 如果这是一个从节点,那么指向主节点
struct clusterNode *slaveof; /* pointer to the master node */
// 最后一次发送 PING 命令的时间
mstime_t ping_sent; /* Unix time we sent latest ping */
// 最后一次接收 PONG 回复的时间戳
mstime_t pong_received; /* Unix time we received the pong */
// 最后一次被设置为 FAIL 状态的时间
mstime_t fail_time; /* Unix time when FAIL flag was set */
// 最后一次给某个从节点投票的时间
mstime_t voted_time; /* Last time we voted for a slave of this master */
// 最后一次从这个节点接收到复制偏移量的时间
mstime_t repl_offset_time; /* Unix time we received offset for this node */
// 这个节点的复制偏移量
long long repl_offset; /* Last known repl offset for this node. */
// 节点的 IP 地址
char ip[REDIS_IP_STR_LEN]; /* Latest known IP address of this node */
// 节点的端口号
int port; /* Latest known port of this node */
// 保存连接节点所需的有关信息
clusterLink *link; /* TCP/IP link with this node */
// 一个链表,记录了所有其他节点对该节点的下线报告
list *fail_reports; /* List of nodes signaling this as failing */
};clusterNode结构的link属性是一个clusterLink结构,保存了连接其他节点所需的有关信息,比如套接字描述符,输入缓冲区,输出缓冲区。
/* clusterLink encapsulates everything needed to talk with a remote node. */
// clusterLink 包含了与其他节点进行通讯所需的全部信息
typedef struct clusterLink {
// 连接的创建时间
mstime_t ctime; /* Link creation time */
// TCP 套接字描述符
int fd; /* TCP socket file descriptor */
// 输出缓冲区,保存着等待发送给其他节点的消息(message)。
sds sndbuf; /* Packet send buffer */
// 输入缓冲区,保存着从其他节点接收到的消息。
sds rcvbuf; /* Packet reception buffer */
// 与这个连接相关联的节点,如果没有的话就为 NULL
struct clusterNode *node; /* Node related to this link if any, or NULL */
} clusterLink;每个节点都保存有一个clusterState结构,记录了在当前节点的视角下,集群所处的状态,
// 集群状态,每个节点都保存着一个这样的状态,记录了它们眼中的集群的样子。
// 另外,虽然这个结构主要用于记录集群的属性,但是为了节约资源,
// 有些与节点有关的属性,比如 slots_to_keys 、 failover_auth_count
// 也被放到了这个结构里面。
typedef struct clusterState {
// 指向当前节点的指针
clusterNode *myself; /* This node */
// 集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
// 集群当前的状态:是在线还是下线
int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */
// 集群中至少处理着一个槽的节点的数量。
int size; /* Num of master nodes with at least one slot */
// 集群节点名单(包括 myself 节点)
// 字典的键为节点的名字,字典的值为 clusterNode 结构
dict *nodes; /* Hash table of name -> clusterNode structures */
// 节点黑名单,用于 CLUSTER FORGET 命令
// 防止被 FORGET 的命令重新被添加到集群里面
// (不过现在似乎没有在使用的样子,已废弃?还是尚未实现?)
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
// 记录要从当前节点迁移到目标节点的槽,以及迁移的目标节点
// migrating_slots_to[i] = NULL 表示槽 i 未被迁移
// migrating_slots_to[i] = clusterNode_A 表示槽 i 要从本节点迁移至节点 A
clusterNode *migrating_slots_to[REDIS_CLUSTER_SLOTS];
// 记录要从源节点迁移到本节点的槽,以及进行迁移的源节点
// importing_slots_from[i] = NULL 表示槽 i 未进行导入
// importing_slots_from[i] = clusterNode_A 表示正从节点 A 中导入槽 i
clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS];
// 负责处理各个槽的节点
// 例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理
clusterNode *slots[REDIS_CLUSTER_SLOTS];
// 跳跃表,表中以槽作为分值,键作为成员,对槽进行有序排序
// 当需要对某些槽进行区间(range)操作时,这个跳跃表可以提供方便
// 具体操作定义在 db.c 里面
zskiplist *slots_to_keys;
/* The following fields are used to take the slave state on elections. */
// 以下这些域被用于进行故障转移选举
// 上次执行选举或者下次执行选举的时间
mstime_t failover_auth_time; /* Time of previous or next election. */
// 节点获得的投票数量
int failover_auth_count; /* Number of votes received so far. */
// 如果值为 1 ,表示本节点已经向其他节点发送了投票请求
int failover_auth_sent; /* True if we already asked for votes. */
int failover_auth_rank; /* This slave rank for current auth request. */
uint64_t failover_auth_epoch; /* Epoch of the current election. */
/* Manual failover state in common. */
/* 共用的手动故障转移状态 */
// 手动故障转移执行的时间限制
mstime_t mf_end; /* Manual failover time limit (ms unixtime).
It is zero if there is no MF in progress. */
/* Manual failover state of master. */
/* 主服务器的手动故障转移状态 */
clusterNode *mf_slave; /* Slave performing the manual failover. */
/* Manual failover state of slave. */
/* 从服务器的手动故障转移状态 */
long long mf_master_offset; /* Master offset the slave needs to start MF
or zero if stil not received. */
// 指示手动故障转移是否可以开始的标志值
// 值为非 0 时表示各个主服务器可以开始投票
int mf_can_start; /* If non-zero signal that the manual failover
can start requesting masters vote. */
/* The followign fields are uesd by masters to take state on elections. */
/* 以下这些域由主服务器使用,用于记录选举时的状态 */
// 集群最后一次进行投票的纪元
uint64_t lastVoteEpoch; /* Epoch of the last vote granted. */
// 在进入下个事件循环之前要做的事情,以各个 flag 来记录
int todo_before_sleep; /* Things to do in clusterBeforeSleep(). */
// 通过 cluster 连接发送的消息数量
long long stats_bus_messages_sent; /* Num of msg sent via cluster bus. */
// 通过 cluster 接收到的消息数量
long long stats_bus_messages_received; /* Num of msg rcvd via cluster bus.*/
} clusterState;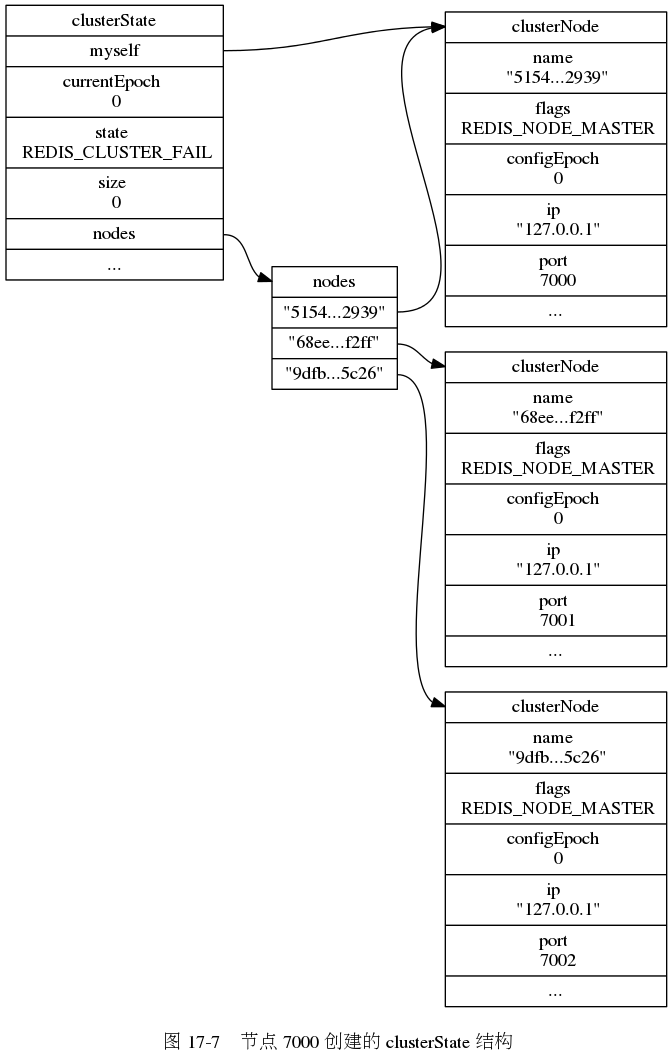
1.3 CLUSTER MEET 命令的实现
通过向节点A发送
CLUSTER MEET命令,客户端可以让接收命令的节点A将另一个节点B添加到节点A当前所在的集群里面。
CLUSTER MEET <ip> <port>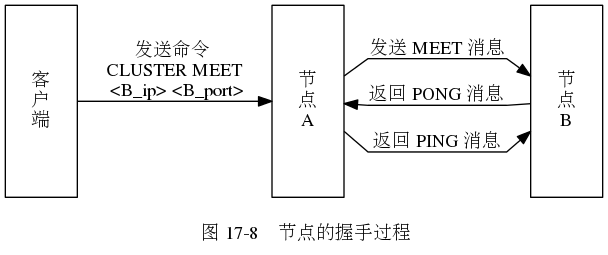
之后,节点A将节点B的信息通过Gossip协议传播给集群中的其他节点,让其他节点也与节点B进行握手,最终,节点B会被集群中的所有节点认识。
2. 槽指派
redis集群通过分片的方式来保存数据库中的键值对:集群的整个数据库被分为16384个槽(slot),数据库中的每个键都属于16384个槽的其中一个,集群中的每个节点可以处理0个或多个16384个槽。
当数据库中的16384个槽都有节点在处理时,集群处于上线状态(ok);相反,如果数据库中任何一个槽没有得到处理,那么集群处于下线状态(fail)。
CLUSTER MEET命令将节点连接到同一个集群里,但仍处于下线状态,因为三个节点都没有处理任何槽。
CLUSTER ADDSLOTS命令,将一个或多个槽指派(assign)给节点负责。
CLUSTER ADDSLOTS <slot> [slot...]当数据库中的16384个槽都被指派给了相应的节点,集群进入上线状态。
CLUSTER INFO命令:查看集群状态
CLUSTER NODES命令:查看节点状态
2.1 记录节点的槽指派信息
clusterNode结构的slots属性和numslot属性记录了节点负责处理的槽。
slots属性:一个二进制位数字(bit array),数组长度为16384/8=2048个字节。
// 由这个节点负责处理的槽
// 一共有 REDIS_CLUSTER_SLOTS / 8 个字节长
// 每个字节的每个位记录了一个槽的保存状态
// 位的值为 1 表示槽正由本节点处理,值为 0 则表示槽并非本节点处理
// 比如 slots[0] 的第一个位保存了槽 0 的保存情况
// slots[0] 的第二个位保存了槽 1 的保存情况,以此类推
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
// 该节点负责处理的槽数量
int numslots; /* Number of slots handled by this node */

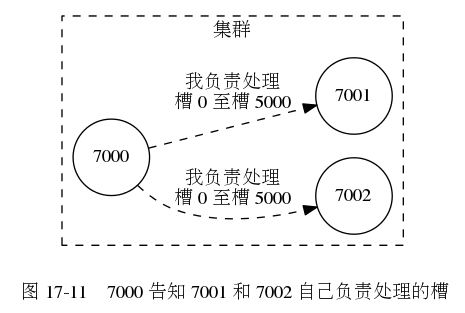
2.2 传播节点的槽指派信息
一个节点①将自己负责处理的槽记录在clusterNode结构的slots属性和numslots属性中②将自己的slots数组通过消息发送给集群中的其他节点,以此来告知其他节点自己目前负责处理的槽。
2.3 记录集群所有槽的指派信息
clusterState结构中的slots数组记录了集群中所有16384个槽的指派信息。
// 负责处理各个槽的节点
// 例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理
clusterNode *slots[REDIS_CLUSTER_SLOTS];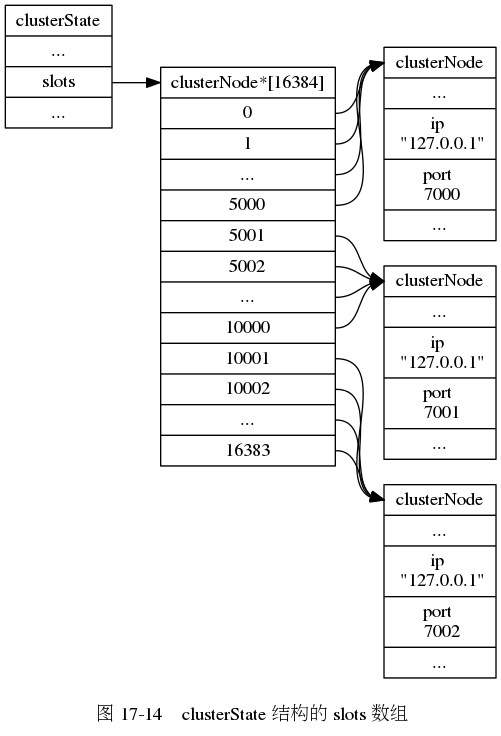
2.4 CLUSTER ADDSLOTS命令的实现
CLUSTER ADDSLOTS命令:接收一个或多个槽作为参数,将所有输入的槽 指派给 接收该命令的节点负责:
CLUSTER ADDSLOTS <slot> [slot ...]
在CLUSTER ADDSLOTS命令执行完毕后,节点会通过发送消息告知集群中的其他节点,自己目前正在负责处理的槽。
cluster.c/clusterAddSlot(clusterNode *n, int slot)函数:
// 将槽 slot 添加到节点 n 需要处理的槽的列表中
// 添加成功返回 REDIS_OK ,如果槽已经由这个节点处理了
// 那么返回 REDIS_ERR 。
int clusterAddSlot(clusterNode *n, int slot) {
// 槽 slot 已经是节点 n 处理的了
if (server.cluster->slots[slot]) return REDIS_ERR;
// 设置 bitmap
clusterNodeSetSlotBit(n,slot);
// 更新集群状态
server.cluster->slots[slot] = n;
return REDIS_OK;
}3. 在集群中执行命令
在对数据库中的REDIS_CLUSTER_SLOTS个槽都进行指派后,集群就会进入上线状态,这时,客户端就可以向集群中的节点发送数据命令了。
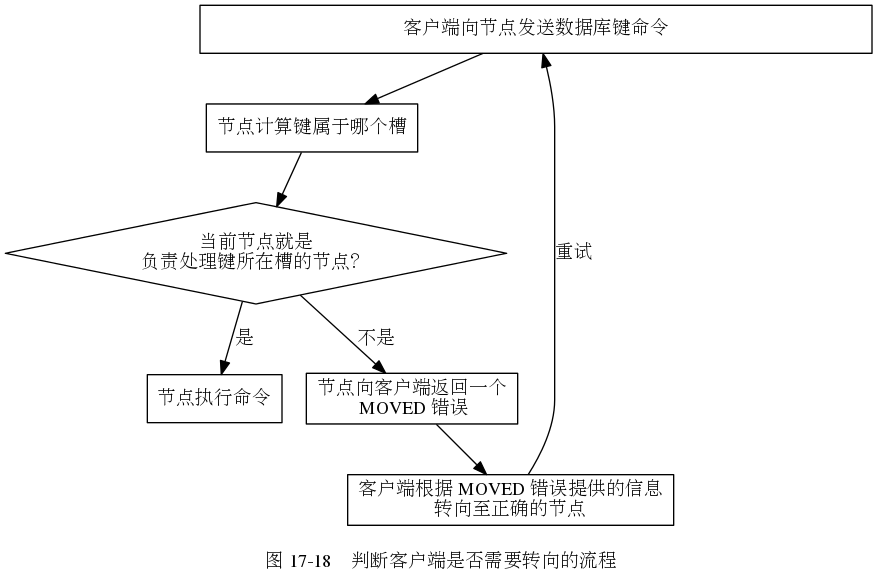
3.1 节点计算键属于哪个槽
CLUSTER KEYSLOT <key>用于计算给定键key属于哪个槽:
127.0.0.1:7000> CLUSTER KEYSLOT "name"
(integer) 20023.2 判断槽是否由当前节点负责处理
当节点计算出键所属的槽 i 之后,节点就会检查自己在clusterState,.slots数组中的项i,判断键所在的槽是否由自己负责:
1. if(clusterState.slots[i]==clusterState.myself) ,那么说明槽i由当前节点负责,节点可以执行客户端发送来的命令。
2. 如果不等,则节点根据clusterState.slot[i]指向的clusterNode结构所记录的节点IP和port,向客户端返回MOVED错误,指引客户端转向至正在处理槽i的节点。
3.3 MOVED错误
当节点发送键所在的槽并非由自己负责处理的时候,节点就向客户端返回一个MOVED错误,指引客户端转向至正在负责槽的节点。
MOVED错误格式
MOVED <slot> <ip>:<port>其中,slot为键所在的槽,ip和port是负责处理槽slot的节点的IP地址和端口号。
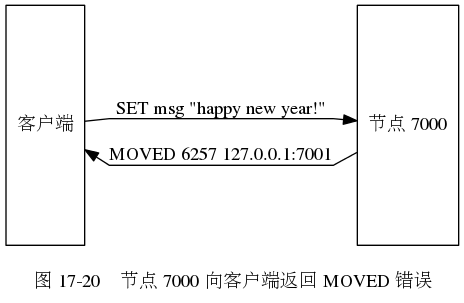
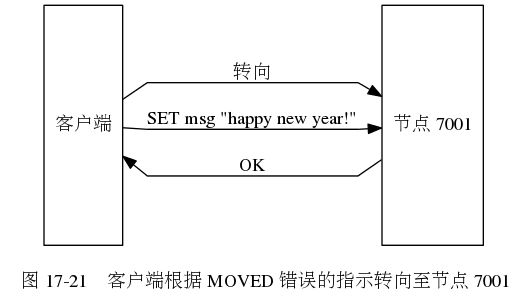
一个集群客户端通常会与集群中的多个节点创建套接字连接,节点转向实际上就是换一个套接字来发送命令,如果客户端尚未与转向的节点建立连接,则根据MOVED错误提供的IP地址和端口号建立连接。
3.4 节点数据库的实现
节点数据库和单机服务器比较:
1. 保存键值对以及键值对过期时间的方式完全相同。
2. 节点只能使用0号数据库,而单机redis服务器则没有这一限制。
3. 除了将键值对保存在数据库中外,节点还会用clustState结构中的slots_to_keys跳跃表来保存槽和键之间的关系。
// 跳跃表,表中以槽作为分值,键作为成员,对槽进行有序排序
// 当需要对某些槽进行区间(range)操作时,这个跳跃表可以提供方便
// 具体操作定义在 db.c 里面
zskiplist *slots_to_keys;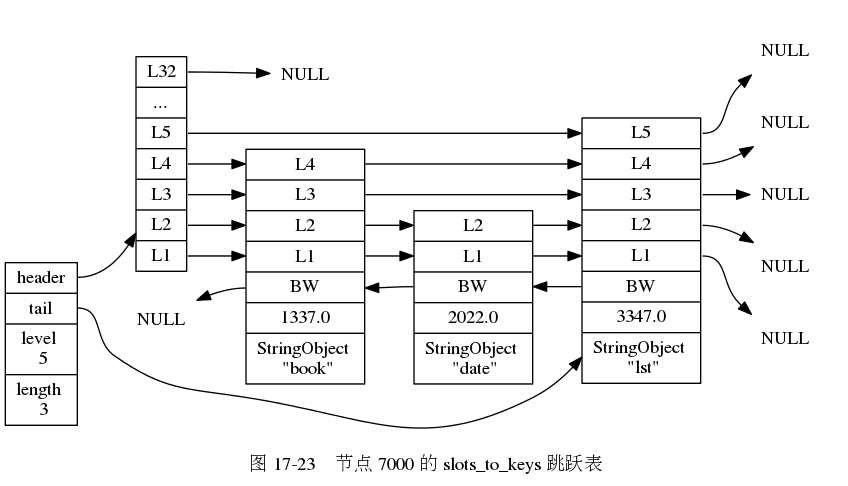
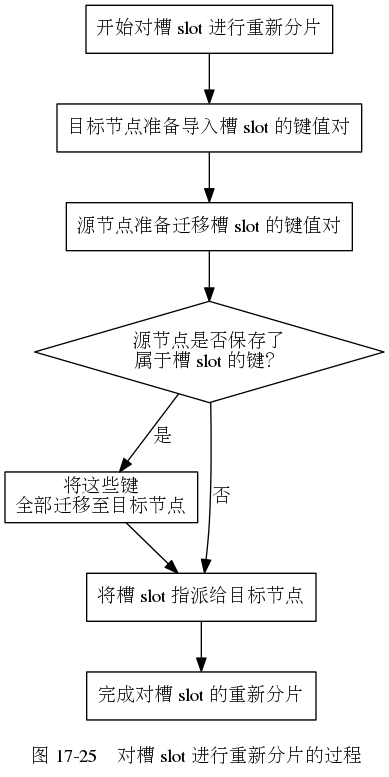
4. 重新分片(sharding)
重新分片(sharding):将任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点),并且相关槽所属的键值对也会从源节点被移动到目标节点。
redis 集群的重新分片操作是由redis的集群管理软件redis-trib负责执行的。
redis-trib通过向源节点和目标节点发送命令来进行重新分片操作。步骤如下:
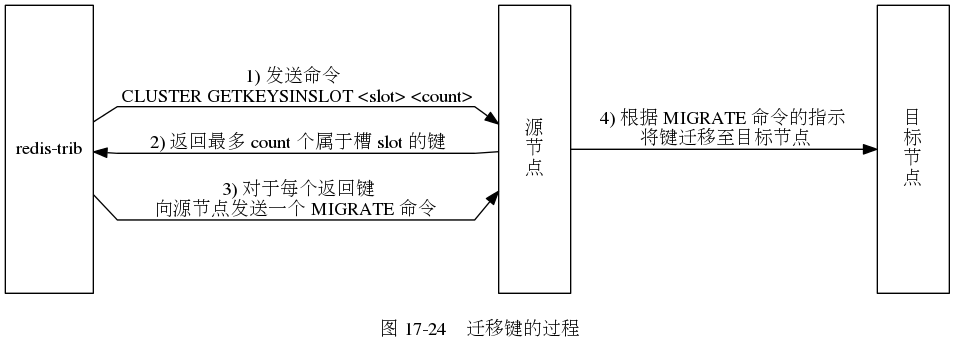
重新分片的整个过程:
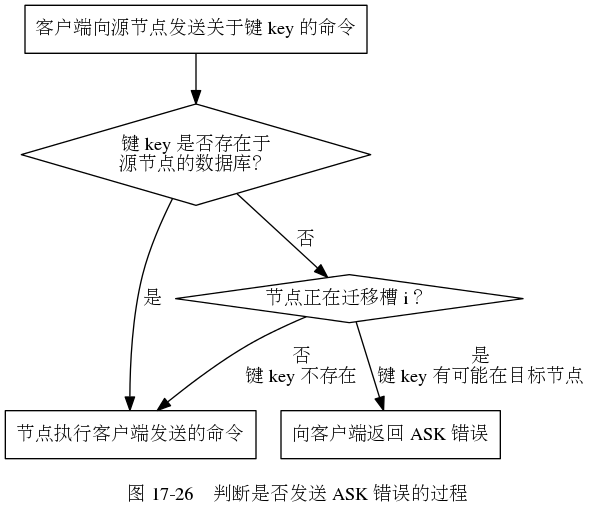
5. ASK错误
在进行重新分片期间,源节点向目标节点迁移一个槽的过程中,如果:属于被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面,当客户端向源节点发送一个与数据库键有关的命令,并且命令要处理的数据库键恰好就属于正在被迁移的槽时:
6. 复制与故障转移
redis集群中的节点:主节点(master)、从节点(slave)
1. 主节点用于处理槽
2. 从节点用于处理复制某个节点,并在被复制的节点下线时,代替下线主节点继续处理命令请求。
7. 消息
集群中的各个节点通过发送和接收消息(message)来进行通信,发送消息的节点为发送者(sender),接收消息的节点为接收者(receiver)。
五种消息:MEET 、PING、PONG、PUBLISH 、FAIL















 2166
2166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









