







一.前记
一直都想好好来系统地学一下linux内核,因为深知它将是我安身立命之本,挣钱养家之道!但出于种种原因,都未能开始,不得不承认其中一个最主要的原因是懒。其实想想,我都三十岁的人了,再不学,能行吗?希望自己以后每天能坚持一点点,积累才是硬道理,既然不可能找出整块的时间来学习,那就每天一点点。
既然要开始学linux内核,那从哪儿开始呢?以前一直想从最最开始的地方学到最最终了的地方,但发现其难度与刚开始的热情根本不在同一量级上,我逐渐明白:这个世界上的事,不要等到认为完全准备好的时候才去做,因为人会一天天老去,等忽然有一天发现自己老的已经拾不起曾经的梦的时候该是多么悲哀呢!不用再多说什么,那就开始吧。
我下载了2.6.32.63的源码,我觉得从下面的入口开始比较舒服:
include/linux/netfilter_ipv4.h
<pre name="code" class="cpp">enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK_DEFRAG = -400,
NF_IP_PRI_RAW = -300,
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
NF_IP_PRI_LAST = INT_MAX,
};
二. 数据包碎片整理的分析:
在netfilter框架下,各个hook点上的hook函数是以一定的优先级挂在一个链表上的,优先级排序是由高到底,虽然netfilter中有不同的表(raw, mangle, filter, nat等),又有不同的HOOK点,每个表中的HOOK点不尽相同,更谈不上hook函数了。但从上面的枚举中,可以看出大概的数据包在内核中要经历的过程。首当其冲的是NF_IP_PRI_CONNTRACK_DEFRAG,这个优先级最高,对应的是数据包的碎片整理,接下来就正式进入linux内核数据包的碎片整理分析。
net/ipv4/netfilter/nf_defrag_ipv4.c
<pre name="code" class="cpp">static struct nf_hook_ops ipv4_defrag_ops[] = {
{
.hook = ipv4_conntrack_defrag,
.owner = THIS_MODULE,
.pf = PF_INET,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_CONNTRACK_DEFRAG,
},
{
.hook = ipv4_conntrack_defrag,
.owner = THIS_MODULE,
.pf = PF_INET,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_CONNTRACK_DEFRAG,
},
};从上面的结构体可以看出数据包的碎片整理会在PRE_ROUTING(数据包刚进入协议栈的时候)和LOCAL_OUT(数据包从本地生成伊始)这两个HOOK点上进行,并且NF_IP_PRI_CONNTRACK_DEFRAG是优先级最高的(标准linux内核是这样的,但完全可以在这个优先级之前定义更高优先级的操作),那意味着数据包进入PRE_ROUTING HOOK检查点后,会首先进行碎片整理,这也是情理之中的事,因为后续的所有操作都应该把数据包当成是完整的,实际上也正是如此。接下来重点分析一下对应的hook函数--ipv4_conntrack_defrag
1.分析ipv4_conntrack_defrag
net/ipv4/netfilter/nf_defrag_ipv4.c
static unsigned int ipv4_conntrack_defrag(unsigned int hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
#if !defined(CONFIG_NF_NAT) && !defined(CONFIG_NF_NAT_MODULE)
/* Previously seen (loopback)? Ignore. Do this before
fragment check. */
if (skb->nfct)
return NF_ACCEPT;
#endif
#endif
/* Gather fragments. */
if (ip_hdr(skb)->frag_off & htons(IP_MF | IP_OFFSET)) {
enum ip_defrag_users user = nf_ct_defrag_user(hooknum, skb);
if (nf_ct_ipv4_gather_frags(skb, user))
return NF_STOLEN;
}
return NF_ACCEPT;
}需要展开分析一下: 这里的问题是:当定义了连接跟踪,且没有定义NAT的时候,如果skb->nfct非空,则直接返回NF_ACCEPT。表面意思是:如果是非NAT场景,且这个数据包已经与一个内核中的连接跟踪对应起来了,那就不用进行碎片整理了。
问题:
(1)一个skb的nfct在什么时机被赋值?换言之,在什么时机进行连接跟踪的建立?当建起了连接跟踪,后续的skb又怎么能跟当前的连接跟踪建立起联系?
(2)如果定义了CONFIG_NF_NAT,对碎片整理有什么影响?为什么没有定义NAT的时候,当连接跟踪建立起来后,就可以直接不用碎片整理了?
2.分析条件:if (ip_hdr(skb)->frag_off & htons(IP_MF | IP_OFFSET))
先学习一下iph:
include/linux/ip.h
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
/*The options start here. */
};
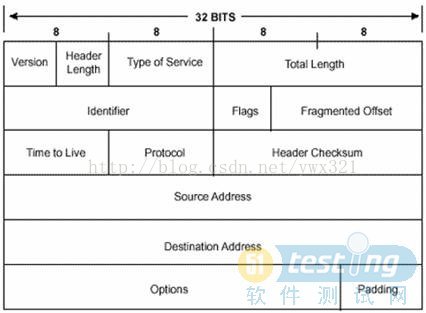
frag_off字段虽然被定义成了_be16,但其长度为13位,剩下的5位留给了Flags。但从结构体的定义来看,该字段的值肯定包含了flags的内容! Version和Header Length字段在同一个字节里,在网络上传输时,在图上是从左到右的方向,对于单字节里面的两个字段来说,也会有大小端的区别:对于小端来说,先传的是Header Length字段(一个字节的低位在右边),后传的是Version字段;但对于大端来说,先传的是Version字段,后传的是Header Length字段。实际上对于网络序来说,通常都是大端,即先传的是Version字段。
flag_off表示该skb在该组分片包中的位置,IP_MORE被定义成0x2000,IP_OFFSET被定义成0x1FFF。flags的三位从左到右的意思分别是:not use, DF, MF。而IP_MORE| IP_OFFSET正好是把第13、14位置1了,那最后ip_hdr(skb)->frag_off & htons(IP_MF | IP_OFFSET)的结果就是检查flags的DF和MF是否至少有一个被置1了。如果有,则进入碎片整理。
3.分析nf_ct_defrag_user
net/ipv4/netfilter/nf_defrag_ipv4.c
static enum ip_defrag_users nf_ct_defrag_user(unsigned int hooknum,
struct sk_buff *skb)
{
#ifdef CONFIG_BRIDGE_NETFILTER
if (skb->nf_bridge &&
skb->nf_bridge->mask & BRNF_NF_BRIDGE_PREROUTING)
return IP_DEFRAG_CONNTRACK_BRIDGE_IN;
#endif
if (hooknum == NF_INET_PRE_ROUTING)
return IP_DEFRAG_CONNTRACK_IN;
else
return IP_DEFRAG_CONNTRACK_OUT;
}看来这个nf_ct_defrag_user就是为碎片找个“主人”。
include/net/ip.h
enum ip_defrag_users
{
IP_DEFRAG_LOCAL_DELIVER,
IP_DEFRAG_CALL_RA_CHAIN,
IP_DEFRAG_CONNTRACK_IN,
IP_DEFRAG_CONNTRACK_OUT,
IP_DEFRAG_CONNTRACK_BRIDGE_IN,
IP_DEFRAG_VS_IN,
IP_DEFRAG_VS_OUT,
IP_DEFRAG_VS_FWD
};4.分析nf_ct_ipv4_gather_frags
net/ipv4/netfilter/nf_defrag_ipv4.c
/* Returns new sk_buff, or NULL */
static int nf_ct_ipv4_gather_frags(struct sk_buff *skb, u_int32_t user)
{
int err;
skb_orphan(skb);
local_bh_disable();
err = ip_defrag(skb, user);
local_bh_enable();
if (!err)
ip_send_check(ip_hdr(skb));
return err;
}include/linux/skbuff.h
/**
* skb_orphan - orphan a buffer
* @skb: buffer to orphan
*
* If a buffer currently has an owner then we call the owner's
* destructor function and make the @skb unowned. The buffer continues
* to exist but is no longer charged to its former owner.
*/
static inline void skb_orphan(struct sk_buff *skb)
{
if (skb->destructor)
skb->destructor(skb);
skb->destructor = NULL;
skb->sk = NULL;
}include/net/sock.h
/*
* Queue a received datagram if it will fit. Stream and sequenced
* protocols can't normally use this as they need to fit buffers in
* and play with them.
*
* Inlined as it's very short and called for pretty much every
* packet ever received.
*/
static inline void skb_set_owner_w(struct sk_buff *skb, struct sock *sk)
{
skb_orphan(skb);
skb->sk = sk;
skb->destructor = sock_wfree;
/*
* We used to take a refcount on sk, but following operation
* is enough to guarantee sk_free() wont free this sock until
* all in-flight packets are completed
*/
atomic_add(skb->truesize, &sk->sk_wmem_alloc);
}
static inline void skb_set_owner_r(struct sk_buff *skb, struct sock *sk)
{
skb_orphan(skb);
skb->sk = sk;
skb->destructor = sock_rfree;
atomic_add(skb->truesize, &sk->sk_rmem_alloc);
sk_mem_charge(sk, skb->truesize);
}net/core/sock.c
void sock_rfree(struct sk_buff *skb)
{
struct sock *sk = skb->sk;
atomic_sub(skb->truesize, &sk->sk_rmem_alloc);
sk_mem_uncharge(skb->sk, skb->truesize);
}在上面两个函数中,skb->destructor被分别在skb_set_owner_w和skb_set_owner_r中被赋值为sock_wfree和sock_rfree,而skb_set_owner_w函数正是在net/ipv4/ip_output.c的ip_fragment函数中被调用,对应的是对本地发出的包进行分片;而skb_set_owner_r则被net/packet/af_packet.c的packet_rcv函数调用,对应的是收到外界进来的包。接下来以sock_rfree为例来介绍一下这个析构函数。
atomic_sub是指原子地减,意即将sk->sk_rmeme_alloc中存着的原子型数原子地减去skb->truesize大小,在源码中是这样解释sk_rmem_alloc的:receive queue bytes committed(已提交的接受队列的字节数),以前老是不明白sock和skb的关系,现在有点恍然大悟的感觉:sock就是skb的一个管理结构体,可以有一系列的skb都对应到同一个sock,比如现在:释放手头的skb之时,需要把对应的接受队列的总字节数减去当前skb的字节数。
查了查网上的说明,觉得网上说的更明确,特抄在这里:sock结构中的sk_rmem_alloc和sk_wmem_alloc分别是指统计接收到的数据包的总大小和发送出去的数据包的总大小。而skb->truesize则表示数据包数据部分的大小加上skb管理结构的大小。
而sk_mem_uncharge(skb->sk, skb->truesize);从字面意义上是说,该skb的管理结构sk不用再对该skb的truesize字节负责了,意即脱离与“上级”的关系。
net/core/sock.c
static inline void sk_mem_uncharge(struct sock *sk, int size)
{
if (!sk_has_account(sk))
return;
sk->sk_forward_alloc += size;
}include/net/sock.h
static inline int sk_has_account(struct sock *sk)
{
/* return true if protocol supports memory accounting */
return !!sk->sk_prot->memory_allocated;
}sk_has_account()函数的注解很清楚了:当sk所属的协议支持内存统计的话,则以双叹号(大概是为了更安全)的方式返回0或1,而sk_forward_alloc在源码中的注解为space allocated forward,表示可供分配的预分配长度,意即可供分配的剩余空间。
从上面的分析来看,skb_orphan(skb)函数实际上并没有显式地释放skb所占的内存空间,其实还不到时候,因为碎片整理就是要把当前的小碎片整理到之前已经“归队”的队列里,怎么能够把碎片在整理之前释放掉呢?!
local_bh_disable();和local_bh_enable();,这两个函数之间的代码临界区,不会被软中断、tasklet、工作队列等打断。
5.分析ip_defrag函数
ip_defrag(skb, user)就是要把当前的小碎片skb整理到等待它归队的“主人”user那里。下面具体来看。
/* Process an incoming IP datagram fragment. */
int ip_defrag(struct sk_buff *skb, u32 user)
{
struct ipq *qp;
struct net *net;
net = skb->dev ? dev_net(skb->dev) : dev_net(skb_dst(skb)->dev);
IP_INC_STATS_BH(net, IPSTATS_MIB_REASMREQDS);
/* Start by cleaning up the memory. */
if (atomic_read(&net->ipv4.frags.mem) > net->ipv4.frags.high_thresh)
ip_evictor(net);
/* Lookup (or create) queue header */
if ((qp = ip_find(net, ip_hdr(skb), user)) != NULL) {
int ret;
spin_lock(&qp->q.lock);
ret = ip_frag_queue(qp, skb);
spin_unlock(&qp->q.lock);
ipq_put(qp);
return ret;
}
IP_INC_STATS_BH(net, IPSTATS_MIB_REASMFAILS);
kfree_skb(skb);
return -ENOMEM;
}
5.1 先来看一下struct ipq
net/ipv4/ip_fragment.c
/* Describe an entry in the "incomplete datagrams" queue. */
struct ipq {
struct inet_frag_queue q;
u32 user;
__be32 saddr;
__be32 daddr;
__be16 id;
u8 protocol;
int iif;
unsigned int rid;
struct inet_peer *peer;
};
5.2 分析dev_net
include/linux/netdevice.h
<span style="font-size:14px;">/*
* Net namespace inlines
*/
static inline
struct net *dev_net(const struct net_device *dev)
{
#ifdef CONFIG_NET_NS
return dev->nd_net;
#else
return &init_net;
#endif
}</span>init_net被定义在net/core/net_namespace.c中,可以理解为最初始的命名空间。如下所示:
<span style="font-size:14px;">struct net init_net;
EXPORT_SYMBOL(init_net);</span>
include/linux/skbuff.h
static inline struct dst_entry *skb_dst(const struct sk_buff *skb)
{
return (struct dst_entry *)skb->_skb_dst;
}
综上,来分析这句:net = skb->dev ? dev_net(skb->dev) : dev_net(skb_dst(skb)->dev);意思是,如果skb->dev(dev为struct net_device*型)非空,意即该skb带着网卡信息,则从skb->dev中返回该skb对应的命名空间指针,否则就从该skb对应的“目的入口”找到该skb的输入网络设备接口,通过这个接口再找到命名空间net。看来,skb->dev是可能为空的,我想这种情况应该是对应于从本地生成的包,还没有流经任何实际网络设备,但无论如何,一个skb的“目的入口”总是非空的,可以至少凭“目的入口”找到该skb对应的命名空间。换言之,所有skb对能对应到协议栈的命名空间net。
5.3分析IP_INC_STATS_BH(net, IPSTATS_MIB_REASMREQDS);
include/net/ip.h
#define IP_INC_STATS_BH(net, field) SNMP_INC_STATS_BH((net)->mib.ip_statistics, field)
<span style="font-size:14px;">#define SNMP_INC_STATS_BH(mib, field) \
(per_cpu_ptr(mib[0], raw_smp_processor_id())->mibs[field]++)</span>IPSTATS_MIB_REASMREQDS被在include/linux/snmp.h中定义,注释为“ReasmReqds”,应该是与碎片整理相关的某个量。net->mib为struct netns_mibmib;,mib是“Management Information Base”的简称,意思是管理信息库,net->mib.ip_statistics是struct ipstats_mib类型,如下所示:
net/netns/mib.h
<span style="font-size:14px;">struct netns_mib {
DEFINE_SNMP_STAT(struct tcp_mib, tcp_statistics);
DEFINE_SNMP_STAT(struct ipstats_mib, ip_statistics);
DEFINE_SNMP_STAT(struct linux_mib, net_statistics);
DEFINE_SNMP_STAT(struct udp_mib, udp_statistics);
DEFINE_SNMP_STAT(struct udp_mib, udplite_statistics);
DEFINE_SNMP_STAT(struct icmp_mib, icmp_statistics);
DEFINE_SNMP_STAT(struct icmpmsg_mib, icmpmsg_statistics);
#if defined(CONFIG_IPV6) || defined(CONFIG_IPV6_MODULE)
struct proc_dir_entry *proc_net_devsnmp6;
DEFINE_SNMP_STAT(struct udp_mib, udp_stats_in6);
DEFINE_SNMP_STAT(struct udp_mib, udplite_stats_in6);
DEFINE_SNMP_STAT(struct ipstats_mib, ipv6_statistics);
DEFINE_SNMP_STAT(struct icmpv6_mib, icmpv6_statistics);
DEFINE_SNMP_STAT(struct icmpv6msg_mib, icmpv6msg_statistics);
#endif
#ifdef CONFIG_XFRM_STATISTICS
DEFINE_SNMP_STAT(struct linux_xfrm_mib, xfrm_statistics);
#endif
};</span>include/net/snmp.h
<span style="font-size:14px;">#define DEFINE_SNMP_STAT(type, name) \
__typeof__(type) *name[2]</span>结合struct netns_mib的定义,DEFINE_SNMP_STAT这个宏实现的效果就是定义了一个struct ipstats_mib *ip_statistics[2];这样的一个指针数组。mib[0]则表示ip_statistics[0],那接下来看一下struct ipstats_mib的定义:
include/net/snmp.h
struct ipstats_mib {
unsigned long mibs[IPSTATS_MIB_MAX];
} __SNMP_MIB_ALIGN__;再来看一下 per_cpu_ptr(mib[0], raw_smp_processor_id()),这个应该是指访问本cpu的某个域,这个域当然是指ip_statistics[0]了。
(per_cpu_ptr(mib[0], raw_smp_processor_id())->mibs[field]++)指的是,让ip_statistics[0]->mibs[<span style="font-size:18px; background-color: rgb(240, 240, 240);">IPSTATS_MIB_REASMREQDS</span>]++;
5.4 分析 if (atomic_read(&net->ipv4.frags.mem) > net->ipv4.frags.high_thresh) ip_evictor(net);
如果协议栈中该skb对应的命名空间中已经给碎片分配的内存超过了其最高阈值,则调用ip_evictor(net);接下来看一下这个函数。<span style="font-size:14px;color:#ff0000;">net/ipve/ip_fragment.c </span><span style="font-size:18px;"> </span>/* Memory limiting on fragments. Evictor trashes the oldest
* fragment queue until we are back under the threshold.
*/
static void ip_evictor(struct net *net)
{
int evicted;
evicted = inet_frag_evictor(&net->ipv4.frags, &ip4_frags);
if (evicted)
IP_ADD_STATS_BH(net, IPSTATS_MIB_REASMFAILS, evicted);
}从注释上来看,是当“触及”到阈值时,系统会把一个最旧的碎片队列予以销毁(还不知道是否是真的彻底释放内存),直到当前的碎片整理工作可以继续。ip4_frags是定义在net/ipv4/ip_fragment.c中的:static struct inet_frags ip4_frags;
net/ipv4/inet_fragment.c
<span style="font-size:14px;">int inet_frag_evictor(struct netns_frags *nf, struct inet_frags *f)
{
struct inet_frag_queue *q;
int work, evicted = 0;
work = atomic_read(&nf->mem) - nf->low_thresh;//计算当前为碎片分配的内存与最低阈值的差值
while (work > 0) {//进入循环
read_lock(&f->lock);
if (list_empty(&nf->lru_list)) {//这个lru_list应该是碎片队列
read_unlock(&f->lock);
break;
}
q = list_first_entry(&nf->lru_list,//要理解netns_frags是碎片队列的队列,这里是指要读取第一个队列。
struct inet_frag_queue, lru_list);//参数1是这个队列的头,参数2是想返回哪个类型的结构体指针,参数3是在这个结构体中struct list_head的名字
atomic_inc(&q->refcnt);//为什么要给这个碎片队列的引用计数加一呢?是因为接下来还要引用q,以防其它地方“看见”q的引用计数为0,从而释放了这个碎片队列
read_unlock(&f->lock);
spin_lock(&q->lock);//从加自旋锁可以看出,这次是要来真格的了
if (!(q->last_in & INET_FRAG_COMPLETE))//
inet_frag_kill(q, f);
spin_unlock(&q->lock);
if (atomic_dec_and_test(&q->refcnt))
inet_frag_destroy(q, f, &work);
evicted++;
}
return evicted;
}</span>
未完待续














 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









