







1、HDFS结构
hdfs的采用的是master/slave模型,一个hdfs cluster包含一个NameNode和若干的DataNode,NameNode是master。
NameNode主要负责管理hdfs文件系统,掌握着整个HDFS的文件目录树及其目录与文件,这些信息会以文件的形式永久地存储在本地磁盘。具体地包括namespace管理(其实就是目录结构),block管理(其中包括 filename->block,block->ddatanode list的对应关系)。NameNode提供的是始终被动接收服务的server,主要有三类协议接口:ClientProtocol接口、DatanodeProtocol接口、NamenodeProtocol接口。
DataNode主要是用来存储数据文件,hdfs将一个文件分割成一个个的block,这些block可能存储在一个DataNode上或者是多个DataNode上。dn负责实际的底层的文件的读写,如果客户端client程序发起了读hdfs上的文件的命令,那么首先将这些文件分成block,然后DataNode将告知client这些block数据是存储在哪些DataNode上的,之后,client将直接和DataNode交互。
2、FSNamesystem
NameNode的核心是FSNamesysem
FSNamesystem持有几大主要数据结构:FSDirectory维护系统目录结构、BlocksMap维护数据块信息、LeaseManagr维护租约信息;此外,还通过DatandeDescriptor、corruptReplicas等维护数据结点(DN)状态、坏副本等信息;
FSNamesystem内部维护多个数据结构之间的关系:
- fsname->block列表的映射
- 所有有效blocks集合
- block与其所属的datanodes之间的映射(该映射是通过block reports动态构建的,维护在namenode的内存中。每个datanode在启动时向namenode报告其自身node上的block)
- 每个datanode与其上的blocklist的映射
- 采用心跳检测根据LRU算法更新的机器(datanode)列表
FSNamesystem体系结构

2.1、FSDirectory
FSDirectory用于维护当前系统中的文件树,存储整个文件系统的目录状态。FSDirectory通过FSImage及FSEditLog保存目录结构的某一时刻镜像及对镜像的修改(从namenode本地磁盘读取元数据信息和向本地磁盘写入元数据信息,并登记对目录结构所作的修改到日志文件);另外,FSDirectory保存了文件名和数据块的映射关系。存储整个文件系统的目录状态我们可以在$HADOOP_HOME/tmp/dfs/name/current下找到这些文件:fsimage以及edits。
fsimage:保存了最新的元数据检查点;
edits:保存了HDFS中自最新的元数据检查点后的命名空间变化记录;
为了防止edits中保存的最新变更记录过大,HDFS会定期合并fsimage和edits文件形成新的fsimage文件,然后重新记录edits文件。由于NameNode存在单点问题(Hadoop2.0以前版本),因此为了减少NameNode的压力,HDFS把fsimage和edits的合并的工作放到SecondaryNameNode上,然后将合并后的文件返回给NameNode。但是,这也会造成一个新的问题,当NameNode宕机,那么NameNode中edits的记录就会丢失。也就是说,NameNode中的命名空间信息有可能发生丢失。
2.2、FsImage
Fsimage是一个二进制文件,它记录了HDFS中所有文件和目录的元数据信息。关于fsimage的内部结构我们可以参看下图:

第一行是文件系统元数据,第二行是目录的元数据信息,第三行是文件的元数据信息。namespaceID:当前命名空间的ID,在NameNode的生命周期内保持不变,DataNode注册时,返回该ID作为其registrationID,每次和NameNode通信时都要检查,不认识的namespaceID拒绝连接;path的length为0,即表示这个目录为根目录。
NameNode将这些信息读入内存之后,构造一个文件目录结构树,将表示文件或目录的节点填入到结构中。
在NameNode加载fsimage完成之后,BlocksMap中只有每个block到其所属的datanodes list的对应关系信息还没建立。然后通过dn的blockReport来收集构建。当所有的DataNode汇报给NameNode的blockReport处理完毕后,BlocksMap整个结构也就构建完成了。
GFS 在 Master 上存储的文件结构是采用命名空间的方式,没有目录内存储的文件列表结构,没有链接或别名机制,每一个命名空间的映射条目都是采用文件的绝对路径存储,并且采用前缀压缩技术(Prefix compression)进行压缩存储。这样可以更高效地进行文件的定位和访问。
2.3、BlocksMap
namenode中是通过block->datanode list的方式来维护一个block的副本是保存在哪几个datanodes上的对应关系的。
2.3.1、版本一

block->datanode的信息没有持久化存储,而是namenode通过datanode的blockreport获取block->datanode list
BlocksMap负责维护了三种信息(维护Block -> { INode, datanodes, self ref } 的映射 ):
block->datanode list
block->INodeFile
datanode->blocks
这要归功于Object[] triplets结构:

他是一个三元组,每个block有几个副本,就有几个三元组。
三元组的第一个元素表示该block所属的Datanode,类型是DatanodeDescriptor,通过它获得block->datanode list
第二/三个元素表示该block所在Datanode上的前/后一个block(前驱和后继),类型是BlockInfo,通过它获得datanode->blocks
借助这个三元组可以找到一个block所属的所有datanode,也可以通过三元组的后两个元素信息找到一个datanode上所有的block。
2.3.3、版本三

BlocksMap是NameNode保存block对象的容器。所有的Block对象被封装成BlockInfo对象,BlockInfo对象组织成HashMap进行存储;
BlockInfo对象使用多个(与复本个数相同)三元组(triplets)保存每个block复本的位置信息;
三元组中第一个位元指向相应复本所在的DataNode;如图中虚线所示;第二个位元指向相同DataNode中前一个Block;第三个位元指向相同DataNode中后一个Block;如图中实现所示,从一个DatanodeDescriptor开始,通过一个双向链表,可以找到该DataNode上所有的Block;
BlocksMap结构比较简单,实际上就是一个Block到BlockInfo的映射。
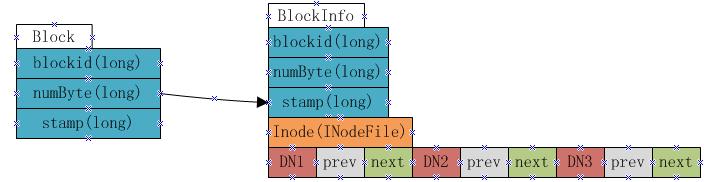
Block
Block是HDFS中的基本读写单元,主要包括:
- blockId: 一个long类型的块id
- numBytes: 块大小
- generationStamp: 块更新的时间戳
BlockInfo
BlockInfo扩展自Block,除基本信息外还包括一个inode引用,表示该block所属的文件;以及一个神奇的三元组数组Object[] triplets,用来表示保存该block的datanode信息,假设系统中的备份数量为3。那么这个数组结构如下:

- DN1,DN2,DN3分别表示存有改block的三个datanode的引用(DataNodeDescriptor)
- DN1-prev-blk表示在DN1上block列表中当前block的前置block引用
- DN1-next-blk表示在DN1上block列表中当前block的后置block引用
DN2,DN3的prev-blk和next-blk类似。 HDFS采用这种结构存放block->datanode list的信息主要是为了节省内存空间,block->datanodelist之间的映射关系需要占用大量内存,如果同样还要将datanode->blockslist的信息保存在内存中,同样要占用大量内存。采用三元组这种方式能够从其中一个block获得到该block所属的datanode上的所有block列表。
Conclusion
通过fsimage与blocksmap两种数据结构,NameNode就能建立起完整的命名空间信息以及文件块映射信息。在NameNode加载fsimage之后,BlocksMap中只有每个block到其所属的DataNode列表的对应关系信息还没建立,这个需要通过DataNode的blockReport来收集构建,当所有的DataNode上报给NameNode的blockReport处理完毕后,BlocksMap整个结构也就构建完成。
HDFS文件系统命名空间
http://www.aboutyun.com/thread-7388-1-1.html
https://github.com/leotse90/SparkNotes/blob/master/HDFS%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F%E5%91%BD%E5%90%8D%E7%A9%BA%E9%97%B4.md#hdfs文件系统命名空间
http://blog.csdn.net/liuaigui/article/details/5993604
GFS uses a B-tree to map namespace to metadata; no directory nodes; 100 bytes per file
哈希表¶
http://origin.redisbook.com/datatype/hash.html














 1138
1138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









