







基础知识我就不写了http://blog.csdn.net/gavin_chen929/article/details/53241976这篇博客有我就主要贴贴代码吧,我的python版本为3.5
建爬虫项目命名为jd建爬虫文件命名为jdsc
目录结构
编写item类(java习惯了不知道在item中是不是也可以这么叫啊)定义几个参数
标题
title=scrapy.Field()
#连接地址
link=scrapy.Field()
#价格
price=scrapy.Field()
#好评数
goodcomment=scrapy.Field()
#差萍数
PoorCountStr=scrapy.Field()
#追评数
AfterCountStr=scrapy.Field()
#总评论数
comment=scrapy.Field()
定义好参数后开始编写具体的操作实现
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from jd.items import JdItem
import urllib.request
import re
class JdscSpider(scrapy.Spider):
name = "jdsc"
allowed_domains = ["XX.com"]
start_urls = ['http://XX.com/']
def parse(self,response):
#定义搜索关键字
key="笔记本"
for iin range(0,100):
#循环收索的页面
url="https://search.XX.com/Search?keyword="+str(key)+"&enc=utf-8&page="+str(1+2*i)
#传递url参数调用page函数
yield Request(url=url,callback=self.page)
def page(self,response):
#提取页面中某个元素的href属性(访问的url)
url1=response.xpath("//div[@class='p-name p-name-type-2']/a/@href").extract()
#循环url
for jin range(0,len(url1)):
#添加访问的https头(页面元素中没有https头确有//我没有去了所以在这加上https)
urldata="https:"+str(url1[j])
#传递urldata参数调用next函数
yield Request(url=urldata,callback=self.next)
def next(self,response):
#实例话JdItem()
item=JdItem()
#提取传过来的URL中的某个元素的值
item["title"]=response.xpath("//div[@class='sku-name']/text()").extract()
#提取url
item["link"]=response.url
#定义正则表达式规则(获取类似于商品id之类的商品唯一属性)
pat = "https://XX.XX.com/(.*?).html"
#获取商品对应页面的唯一性属性
thisid=re.compile(pat).findall(response.url)[0]
#构建获取商品价格的url(这个地方的名字我定义错了comment应该换成price的导致后面我很多参数的名字都混了 )
)
commenturl="https://XX.XX.XX/XX/mgets?callback=XX&skuIds=J_"+str(thisid)
#获取价格参数集(获取到的数有好几个好像是什么会员价市场价之类的)
commentdata=urllib.request.urlopen(commenturl).read().decode("utf-8","ignore")
#定义正则表达式规则
pate='"p":"(.*?)","m":'
#获取价格(价格是一个json的结果集)
item["price"]=re.compile(pate).findall(commentdata)
#构建商品评论数的url
priceurl="https://xxx.xx.com/xx/xx.action?referenceIds="+str(thisid)+"&callback=xx"
#获取评论数结果集(结果集是json数据)
pricedata=urllib.request.urlopen(priceurl).read().decode("utf-8","ignore")
#定义获取好评数的正则表达式规则
pricepategood='"GoodCount":(.*?),"AfterCount'
#获取好评数
item["goodcomment"]=re.compile(pricepategood).findall(pricedata)
#定义追评数的正则表达式规则
priceafter='"AfterCount":(.*?),"AfterCountStr"'
#获取追评数
item["AfterCountStr"]=re.compile(priceafter).findall(pricedata)
#定义差评数的正则表达式规则
PoorCountStrpat='"PoorCount":(.*?),"PoorRate"'
#获取差评数
item["PoorCountStr"]=re.compile(PoorCountStrpat).findall(pricedata)
#定义评论数的正则表达式规则
commentpat='"CommentCount":(.*?),"AverageScore"'
#获取总的评论数(获取的数本来有些数据是一万为单位计数的我获取后万始终没看到所以就换了一种表达方式)
item["comment"]=re.compile(commentpat).findall(pricedata)
yield item
编写pipeline类
# -*- coding: utf-8 -*-
import pymysql
class JdPipeline(object):
def __init__(self):
#定义连接数据库
self.conn = pymysql.connect(host="localhost",user="root",passwd="YY",db="cs",port=3306,charset='utf8')
def process_item(self, item,spider):
#try处理异常
try:
#获取商品名称
title=item["title"][0]
link=item["link"]
price=item["price"][0]
comment=item["comment"][0]
goodcomment=item["goodcomment"][0]
PoorCountStr=item["PoorCountStr"][0]
AfterCountStr=item["AfterCountStr"][0]
#拼接插入mysql数据库的sql语句
sql = "insert into jd(title,link,price,comment,goodcomment,poorcountstr,aftercount) values('"+title+"','"+link+"','"+price+"','"+comment+"','"+goodcomment+"','"+PoorCountStr+"','"+AfterCountStr+"')"
#执行sql
self.conn.query(sql)
#提交sql
self.conn.commit()
return item
except Exceptionas err:
pass
def close_spider(self):
#这里本来可以不用提交的不过发现这里不提交的话好多异常数据显示不知道是什么原因(希望大神给我解答一下)
self.conn.commit()
#关闭数据库连接
self.conn.close()
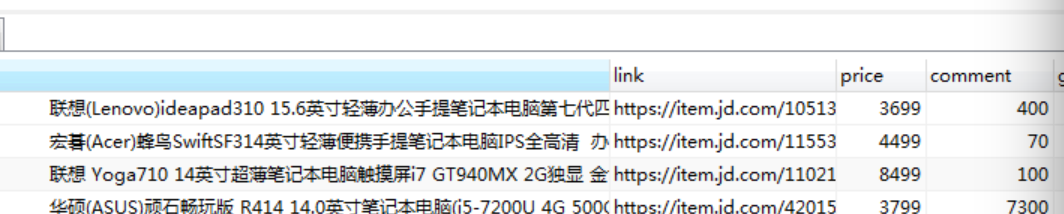














 833
833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









