






一、大索引技术,大数据的未来
YDB并没有采用堆积机器,靠大内存和SSD硬盘的方式来提升计算速度。YDB采用索引技术, 在RDBMS中索引的概念大家一点都不陌生,但是在大数据里大家似乎没有听过,YDB将索引创建在HDFS中,通过索引技术,将大数据分门别类整理好,就像是一个新华字典的目录,通过目录可以快速到相关数据,避免了暴力的扫描,从而提升查询速度。
1.当大数据使用上大索引后有什么好处?
l索引技术大幅度的加快数据的检索速度。
l索引技术可以显著减少查询中分组、统计和排序的时间。
l索引技术大幅度的提高系统的性能和响应时间,从而节约资源。
2.这个大索引系统应该什么样?
l数据规模超大:万亿甚至十万亿。
l数据时效性高:数据从产生到能够查询到结果这个间隔1~2分钟。
l查询响应要快:从万亿规模的数据里,查询到相关数据,响应时间为毫秒或者几秒。
l支持容灾:要能够支撑可靠的容灾,并且保证良好的数据的准确性。
l能够与现有的大数据系统进行较好的融合,方便系统之间的交互(数据导入导出)
3.传统索引的缺点
传统的关系型数据库的索引目前存在如下几个问题,是需要改进的。
l索引存储在本地硬盘
首先是分散在机器的每个硬盘上,索引不容易管理,容灾与高可用的实现代价较高。
其次是索引的迁移成本以及单机硬盘的容量制约了其索引规模和大小。
最后是如果是通过冗余("master/slave"或者"双写")等方式实现数据容灾,数据一致性的设计难度较大。
本地硬盘往往并不可靠,如果存在“坏点”问题,某一时刻读取到的某段数据其中有一个byte的值是异常的,操作系统并不能及时的发现,但是也有可能引起整个索引的指针异常,查询到的数据不准确。
l表的管理、索引、调度曾混杂在一起,集群规模上不去
索引数据、计算资源掺杂在一起,调度系统管理的事情太多,既要管理索引,又要管理心跳,也要维护容灾,导致调度系统的机器规模上不来。同一个计算资源只分配给固定的索引数据导致计算资源太多的浪费。
l对硬件要求太高
数据必须长期持久的滞留在内存中,否则无法快速的加载和查询数据,对硬件要求较高一般都是需要大内存(128G以上)以及SSD硬盘,百亿规模的数据甚至需要数百台机器来支撑快速的查询,对于万亿规模的数据来说成本太高.
4.基于YDB的大索引的特点
随着基于Hadoop Yarn技术的趋于成熟,以及在HDFS中的索引技术的成熟和性能的提升,低延迟的万亿规模的索引技术有了希望。
lYarn本身是一套完美的任务调度系统,他解决了Hadoop1.0版本JobTracker调度的不足,调度延迟时间大大缩小,并且适合实时的即席任务调度,启动的任务是可以长久的持久化运行,并且有很好的容灾机制。
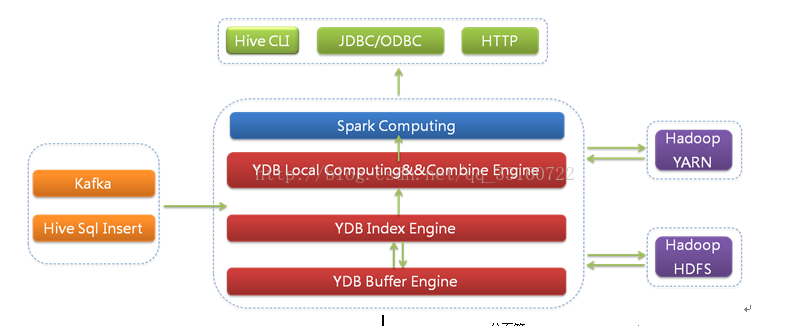
l索引可以直接存放在HDFS中,通过HDFS来解决数据的容灾问题,让业务能更专注索引的实现。索引直接存储在HDFS上,通过HDFS来实现数据的高可用,这样程序的设计复杂性就会减少很多,不再担心本地硬盘的问题(是否损坏,是否已满,硬盘损坏时迁移时间过长),也不用担心各种网络的问题,理论上HDFS上有多大的空间,我们就可以存储多少索引,不再受限于本地磁盘大小的限制,数据规模可以很容易的水平拓展。
l易于使用与部署,在任意节点启动YDB。服务直接在Yarn上启动,Yarn自动部署与分发,不在需要集群一台一台的配置。
l将索引数据与计算资源的分开,不再交叉的放在一起,分别管理,划清界限,减少程序设计复杂度。计算资源的管理直接交给Yarn来处理,从而提升集群的规模。
l一个计算资源不再固定的负责一个索引,而是根据实际的计算需要,处理不同的索引,这比之前一个资源(CPU+内存)固定的分配给一个索引利用率会高很多,因为并不是每次检索和查询都需要扫描全部的数据,有些数据根本就不需要或者很少去查,就没必要让他们长期的占用一个资源。
l索引的管理将会充分的放权,采用HDFS的目录形式的层次结构,便于管理,外部可以自由的配置索引的存储目录,根据不同业务的需要,索引可以按照时间进行打散,按照时间进行目录分区,也可以按照某些用户ID进行hash,也可以按照某些业务来管理配置不同的生命周期。
lYDB是一个细粒度的、精确粒度的索引。数据即时导入,索引即时生成,通过索引高效定位到相关数据。YDB与Spark深度集成,Spark直接对YDB检索结果集分析计算,同样场景让Spark性能加快百倍
l这个版本的YDB除了可以单独对外提供服务,也会更加的开放,对外提供索引服务,提供了很多拓展功能,现有的Hive以及Spark可以很方便的通过类似InputFormat或RDD的方式直接使用大索引。同时可以方便的与HDFS,Hbase,Hive,进行交互,也可以通过自定义实时的消费Kafka,MetaQ等消息队列的数据。
试想下,Spark在利用上这个大索引后,一个万亿规模的数据,几秒钟就返回结果,而且还支持很多的复杂查询,是不是很值得期待呢 。
二、YDB架构描述














 2996
2996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









