






第十二章YDB技术原理
一、铺一条让Spark跑的更快的路
| |

二、YDB的本质
在Spark之上基于搜索引擎技术,实现索引和搜索功能。
既有搜索引擎的查询速度,又有Spark强大的分析计算能力。
可对多个字段进行关键字全匹配或模糊匹配检索,并可对检索结果集进行分组、排序、计算等统计分析操作。
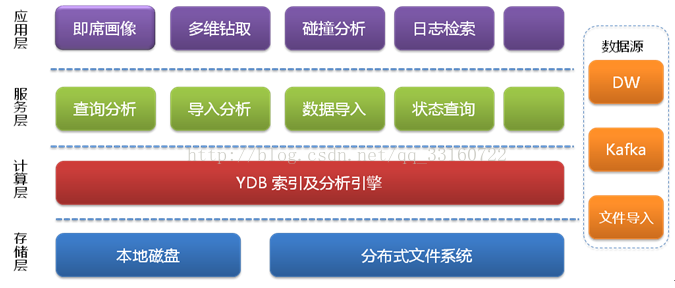
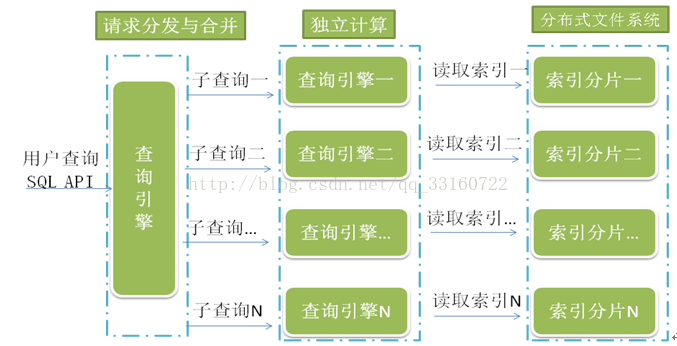
三、多种技术组合-万亿数据秒级查询

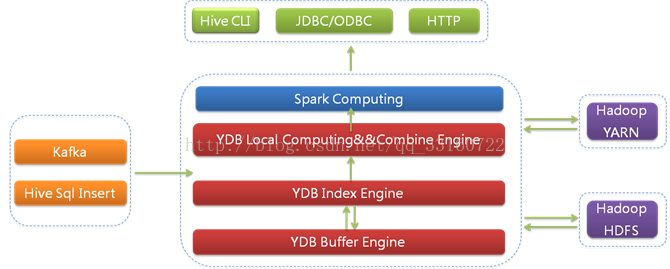
四、整体架构
| |
| |
| |
五、通过读写双向BLOCK-BUFFER减少文件IO
| |
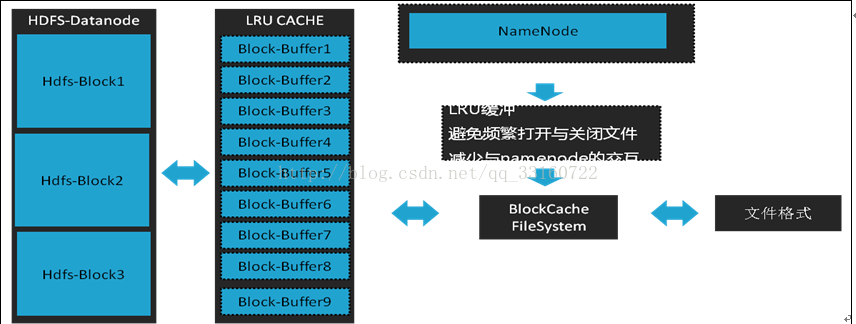
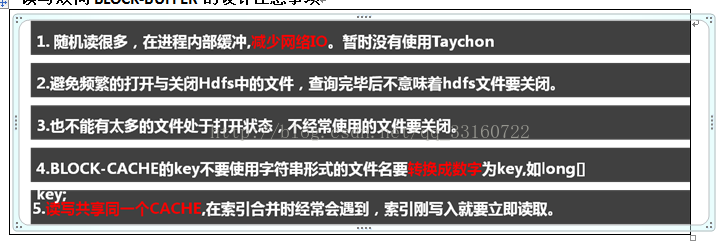
读写双向BLOCK-BUFFER的设计注意事项
| |
六、倒排索引与跳跃表
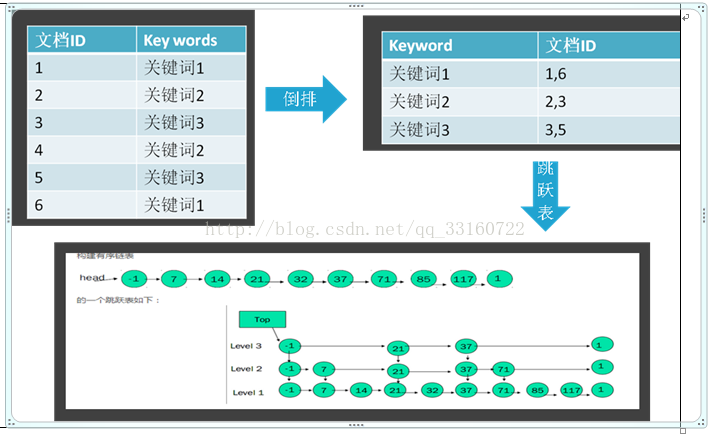
1.倒排索引与跳跃表基本原理
| |
| |
2.与开源的倒排索引系统相比
| l数据不要存储在本地 硬盘容易坏,恢复麻烦,每次数据都的从备份恢复么?20T数据的恢复要多久-7个小时够么? l系统资源问题 索引不要持久化的打开的,永远不关闭,在万亿规模下-太耗资源,要修改为LRU按需加载,不 经常使用的索引要关闭掉,节省资源。 lIO与内存问题 fdx,tvx,fnm,si,tip等文件是常驻内存的,要改为按需读取,提高首次打开索引的速度。 lLuceneDocvalues可以优化一下 三到四次重复IO,略加改动在索引合并是就可以节省2~3倍的IO。 多个segments之间要做关系映射,特别耗费CPU与内存,这也是SOLR耗内存的主要原因之一。 HASHSET操作太影响性能,要去掉换成数组。 lGC问题 创建Field的时候,有对象可以复用,否则GC问题严重。 (在solr里每个field要创建60多个对象,每行要创建600多个对象。) l数据倾斜问题 如 性别=男 and 手机号=1234567890。多个条件查询的时候要充分利用跳跃表。 |
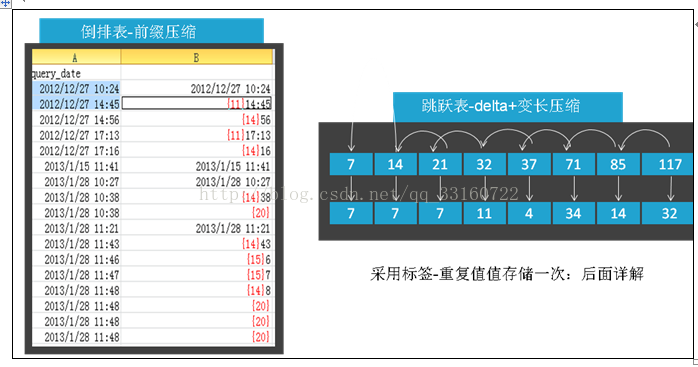
3.针对范围查找我们所做的优化(skiplist IO 分析)
范围查找,尤其是时间范围的查找,在日常检索中会被经常使用,在范围查找中跳跃表的利用与否对性能影响非常大。
我们对lucene的默认范围查找做了一个小实验,对IO情况做了分析。
测试结果如下
1)普通的等值SQL分析-占用IO较小
筛选条件为:phonenum='13470881895' and amtdouble=50
2)使用小范围的 term扫描(IO也较小)
筛选条件为:phonenum='13470881895' and amtdouble like '([50 to 50])'
3)使用大范围的term扫描(IO非常大,超出想象)
筛选条件为:phonenum='13470881895' and (amtdouble>='50' or amtdouble<='50')
amtlong采用的数据类型为tlong类型,已经尽量通过tree的层次结构减少了term的个数,但是没想到,doclist本很成为瓶颈。
doclist用来存储一个term对应的doc id的列表,由于数据量很大,有些term可能达数亿甚至几十亿个。
问题分析
我们在上述查找中,都限定了手机号码,理论上,只要利用了skiplist的跳跃功能(lucene中对应advance方法),IO会很小,但是明显第三种测试的IO超出了我们的预期。
对于文档数量较少的范围查找,是否使用了跳跃功能对性能影响不大,但是YDB的场景更偏重大数据场景,倒排表对应的skiplist会特别长,如果没有使用跳跃功能就会出现上面那种一个查询耗费几个GB的IO的情况,严重影响查询性能。
我们针对每个IO,打印出详细的函数调用关系,验证我们的推测。
前两种情况均使用了advance。
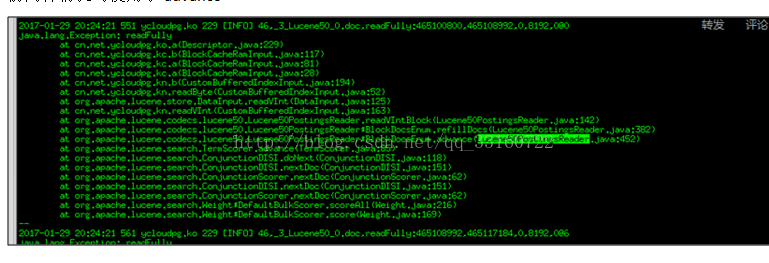
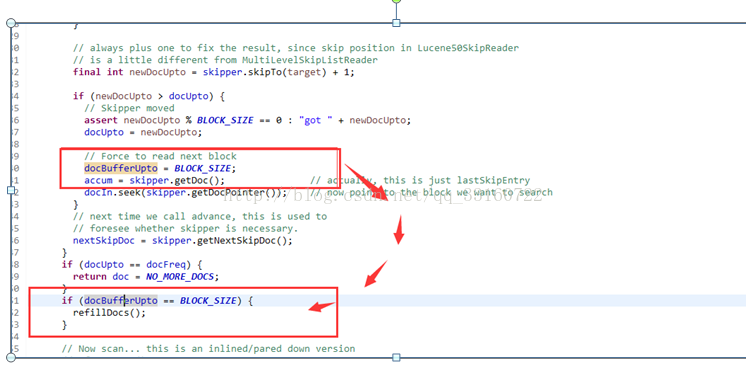
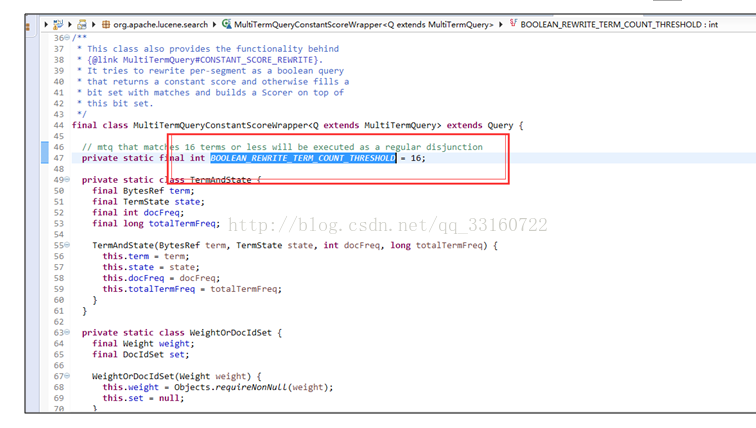
第三种情况没有advance,而是采用了暴力遍历的方式,所以IO特别巨大,我们通过源码分析到了具体原因,超过16个term后,lucene默认就不会继续使用skiplist了。
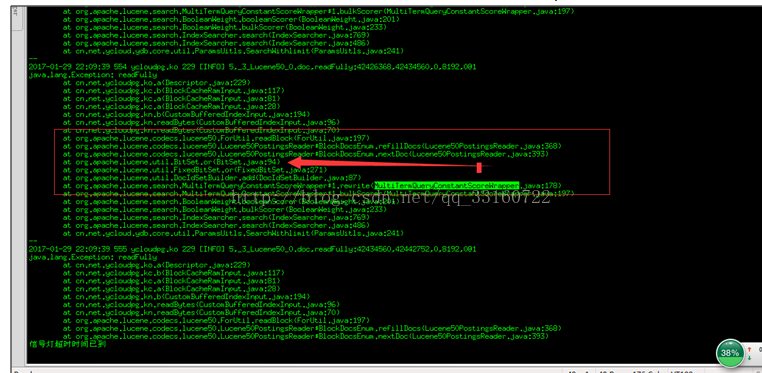
如何解决?
lucene这样优化是有明显的原因的,即当term数量特别多的时候,跳跃的功能会带来更多的随机读,相反性能会更差。
但显然对于海量数据的情况下不适用,因IO巨大导致检索性能很慢,YDB针对范围查找做了如下的变更改动
16个term真的太小太小,我们更改为1024个,针对tlong,tint,tfloat,tdouble类型的数据将会有特别高的扫描性能。
大多时候term对应的skiplist也是有数据倾斜的,尤其是tlong,ting,tfloat,tdouble类型本身的分层特性。对于有数据倾斜的term我们要区别对待,对于skiplist很长的term采用跳跃功能能显著减少IO,对于skiplist很短的term则采用顺序读取,遍历的方式,减少随机读。
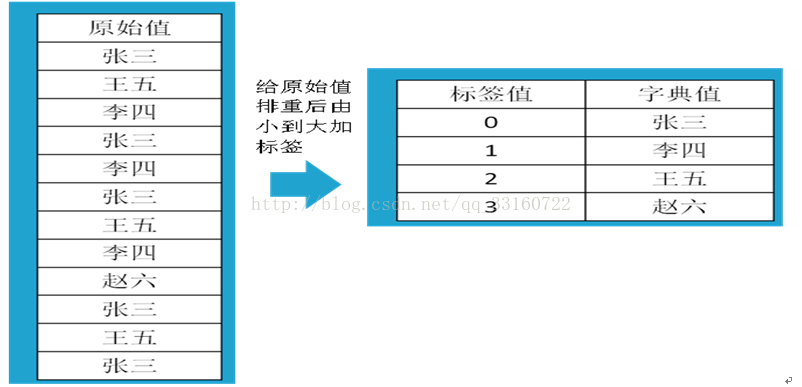
七、采用标签代替原始值-进行分组与排序
采用标签标记技术-让大数据化小
优点
1.重复值仅存储一份,可以减少存储空间占用。
2.标签值采用定长存储,可随机读取。
3.Group by分组计算的时候,使用标签代替原始值,数值型计算速度比字符串的计算速度快很多。
4.标签值的大小原始值的大小是对应的,故排序的时候也仅读取标签进行排序。
5.标签比原始值占的内存少。
缺点
1.如果数据重复值很低,存储空间相反比原始数据大。
2.如果重复值很低,且查询逻辑需要大量的根据标签值获取原始值的操作的时候,性能比原始值慢。
下图为替换示例,示意图
| |
| |
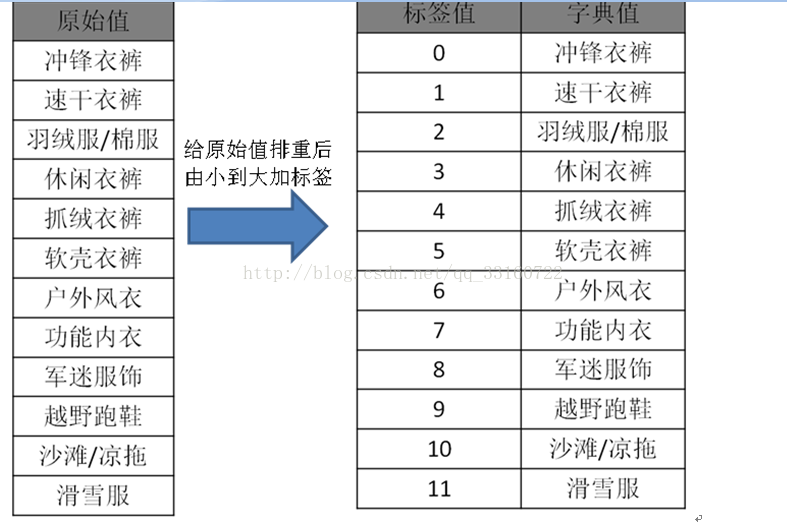
在真实的数据中,数据肯定是有重复的,比如说类目,性别,年龄,成交金额等信息,传统的分析工具存储的是原始的值,比如说我们有1千亿条数据,那么就要存储一千亿条记录,那么进行统计的时候,一条一条的读出这些类目肯定要慢的不得了。
还记得机器人总动员中的伊娃么?当数据规模达到一定程度以后,如果还是直接对原始值进行读取,对大数据的搬运工作将会特别的消耗体力,而且工作效率很低。

ydb对原始数据做了一些处理,基本思路是:虽然你有1千亿的数据,但是你的类目不会那么多,典型的系统一般是几万个类目,2~3个性别值,故ydb在存储的时候虽然有1千亿条记录,但是只会存储几万个类目,2个性别,这根原始的千亿条记录在数据规模上可是相差千万倍,那么在之后的统计(count,sum,avg等)势必会比传统的分析工具快上千倍万倍。
ydb的这种方式我们称为标签技术,就是将数据的真实值用一个数值标签来替换数据本身,原始数据每个值我们只存储一份,这样当有大量重复值的数据,可以节省很多IO,即使数据重复值很少,我们也可以一个数字来代表原始值,因为原始值有可能比较大,但数值确可以很好的压缩。
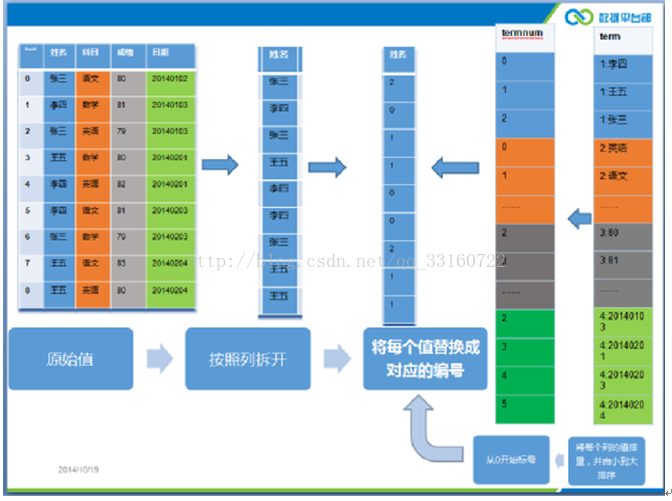
基本的处理过程如下图所示:
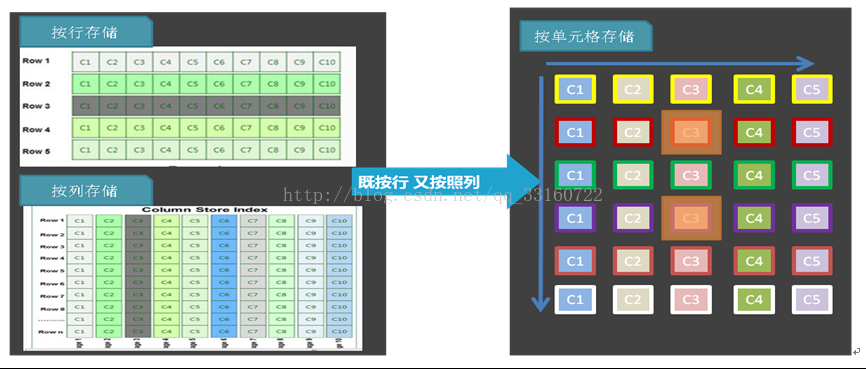
八、按单元格存储
YDB在列的处理上也采用了列存储的技术,列和列之间的值是分开的,基于YDB的一个项目(face),是一个几万个列的大宽表,用户分析的时候往往只关心几个列(维度),如果像传统的分析软件那样,将几万个列的值都读出来,然后只取其中几个列的值,那么太浪费了,所以列存储技术YDB这种基于检索的分析系统来说也是必备的。
但是仅仅列存储也是不够的,如果数据行数很多,即使至于一个列的暴力扫描也会很慢,所以YDB结合了索引+标签技术,如下图所示,我们使用了按照单元格存储的方式,每个单元格存储的是一个标签的值,而非原始数据,这样就可以进行定长的跳跃的读取,而且根据标签值的情况,我们可以采取不同的压缩算法。
| |
九、利用倒排索引跳过不需要的行与列-不进行暴力扫描
| |
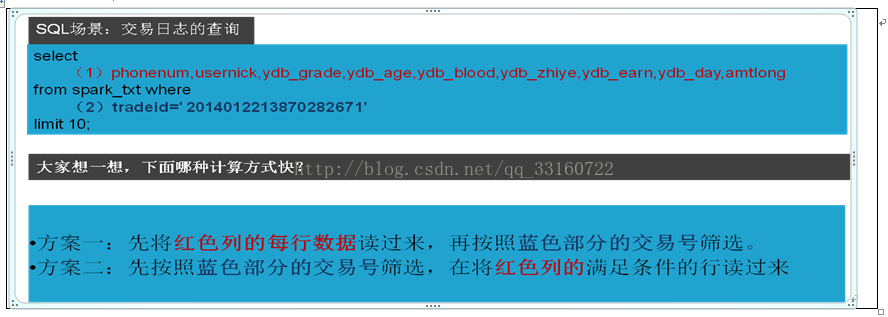
YDB跟传统的分析工具最大的不同,是传统的分析工具很多时候采用的非常暴力的全表扫描的方式进行统计,有1千亿条记录,就要扫描1千亿行,你可能只需要在其中找几条记录而已,却要匹配1千亿次。
如果你没有变种人X教授的最强大脑,那么千万不要学他这么做,一个一个的找人,真的会累死的。

YDB使用索引直接定位到相关的记录,不需要的记录则全部都跳过去,这样无疑会节省很多的IO,从目前的几个案例来看,对几千亿的数据量进行一次检索耗时也就是几秒钟,这要是采用哪种暴力扫描的方式,怎么说不得几个小时才能算完啊。
这里面涉及倒排索引、跳跃表、delta压缩,doclist压缩与跳跃,bitset等相关跟索引有关的技术,看着很高大上,其实并不难理解。其实大家可以回想一下,我们小时候使用的新华字典了,目录其实就是一种索引,只有拼音,和偏旁部首等几个维度,但我们绝不会为了查找某一个字,翻遍每一页,而是借助目录的多级索引进行快速的定位,YDB与之类似,只不过复杂了一些,在细节上进行了很多的优化。

十、非排序的列最后延迟读取
|
|
十一、采用blockSort快速排序
blockSort排序(排序大跃进)
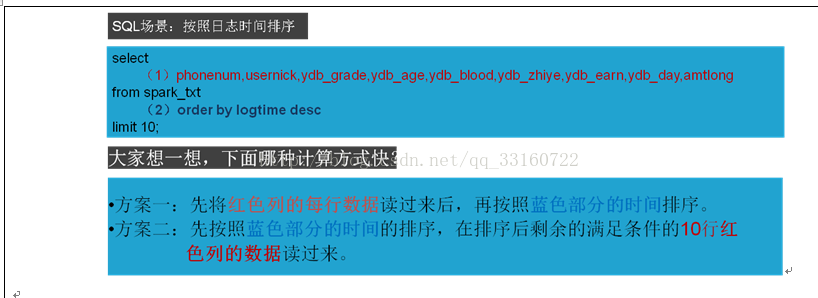
按照时间逆序排序可以说是很多日志系统的硬指标。在延云YDB系统中,我们改变了传统的暴力排序方式,通过索引技术,可以超快对数据进行单列排序,不需要全表暴力扫描,这个技术我们称之为blockSort,目前支持tlong,tdouble,tint,tfloat四种数据类型。
由于blockSort是借助搜索的索引来实现的,所以,采用blockSort的排序,不需要暴力扫描,性能有大幅度的提升。
blockSort的排序,并非是预计算的方式,可以全表进行排序,也可以基于任意的过滤筛选条件进行过滤排序。
十二、两段式查询
1.将原先的一次查询化为两次或多次查询。
2.第一次查询仅读取必备的列,如排序的列,需要group by与统计的列。
3.第一次查询不会获取数据的真实值,仅仅读取数据标签
4.所有的计算都完成后,因为数据进行过排序或汇总,剩余的记录数不多
这个时候在将标签从字典中转换为真实值,其他列的值也跟着读取过来。
十三、多区域数据实时导入
|
|
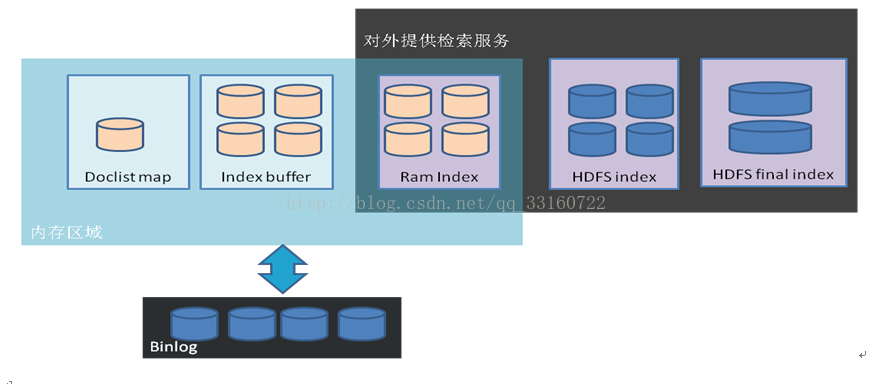
十四、采用PROCESS-LOCAL 更充分的利用cache
HadoopRdd只有HDFSCacheTaskLocation与HostTaskLocation,并没有ExecutorCacheTaskLocation无法做到PROCESS-LOCAL
但是注意下这里的源码,可以通过变通的方式实现。
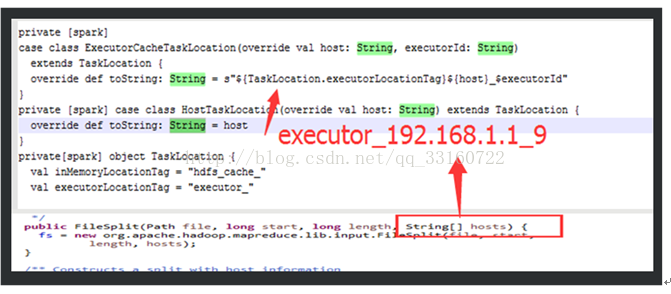
其实进程在发生故障后,重新启动后,executorId是变化的。要注意修正
十五、创建持久化的进程
YDB与常规的spark和Hive应用的最大的区别是,YDB里面是在YDB启动的时候就先将Container启动好,而不是等一个SQL查询的时候才去动态的启动进程
1.这边避免来来回回的复制jar包
2.jvm本身创建进程开销很大
3.利用process-local的特性,可以更高效的利用Cache
十六、按需加载
数据表,索引,列信息,列的值,文件,文件cache均采用LRU的方式加载,只有用到才会打开,不经常使用的会释放掉资源。
十七、addIndexesNoOptimize的优化
该方法了解lucene的人应该知道,是向当前索引中添加一个新的索引,通常来说我们在mapreduce的第一个阶段会通过大并发创建小索引,在第二个阶段会通过addIndexesNoOptimize的方法将这些小的索引合并成一个完整的最终的索引。
目前lucene在这个地方的实现并不是特别好,addIndexesNoOptimize的处理逻辑是先将外部的索引copy到当前索引所在的目录,然后在进行合并,所以这个就多了一个copy的过程
这样做目前有3个缺点
第一、 当数据量特别大的时候,因为有了一次额外的copy,这种copy带来的开销是很大的,而且也是没必要的。
第二、 因为这这种copy将索引都copy到同一个目录上了,也就意味着在同一个磁盘上,那么在合并索引的时候还需要将这些文件重新读取一遍,单个磁盘的读取速度是有限的,不能利用多个磁盘进行合并会影响合并速度。
第三、 很多时候我希望当前索引下的不同的sigments能够分布到不同的硬盘上,这样检索的时候,同一个索引不同的sigments能够使用不同的硬盘进行检索。
原理:
针对上述问题,我们对lucene进行了一次比较小的改进,大家可以将其理解为Linux下的文件的软连接,实际的addIndexesNoOptimize方法并不会真正的发生copy,而是仅仅在当前的索引中做了一个标记,标记出他们附加的外部索引存储在什么位置,而不是真的去copy他们。
十八、 solr 的FQ Cache的不足以及在TOP N 全文检索上的改进
举个倒排表的例子
性别:男 =>1,2,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20
手机:1340100xxxx =>11
可以看出上述两个列的值有很大区别,性别列,因为值得重复程度特别多会有大量的docid对应性别是男的用户
而对于手机这个列为,一般一个手机号只对应一个docid
第一个场景
那么如果我去查找性别是男的 前10条记录 而不考虑任何的排序的话,我仅仅从头读出10个docid 就可以了,但实际上solr和lucene本身并没有这样干,solr是为了生成一个完整的bitset作为缓存,将全部的值都会读出来,之后作为缓存放在内存里,对于lucene来说它的默认的collect实现也是收集全部的docid,而不是收集到10个就停止了(它这样做的目的是为了全文检索里面的余弦排序,但很多场景并不需要排序),如果对应几千万条记录的话,IO浪费很多,是很亏的,很有必要自己单独写一个collect.
第二个场景
我们查找性别是男的并且手机号是 1340100xxxx的用户,很明显,结果就是docid=11的这个用户,这个处理的时候如若大家的过滤条件是通过solr的两个不同的fq参数传递进去的时候,就还会存在第一个场景的问题,性别是男的那个列浪费了很多的IO,所以这个地方要注意改为让他们在同一个FQ里面,使用lucene的booleanQuery去查询,这样因为doclist本身具有跳跃的性质,性别的那个列的相当一部分的docid都会跳跃过去,而节省了IO,所以自某些场景要做适当的优化
十九、ThreadLocal引起的内存泄露
无论是lucene还是spark 均使用了大量的ThreadLocal对象,采用普通线程使用ThreadLocal不会有问题,线程结束资源就释放了,但是如果想solr与ES那样采用线程池就会引起内存泄露的问题,因为线程池中的线程有可能永久都不释放,所以对于spark,solr,es都存在内存泄露的问题。
threadlocal里面使用了一个存在弱引用的map,当释放掉threadlocal的强引用以后,map里面的value却没有被回收.而这块value永远不会被访问到了. 所以存在着内存泄露. 最好的做法是将调用threadlocal的remove方法.
每个thread中都存在一个map, map的类型是ThreadLocal.ThreadLocalMap. Map中的key为一个threadlocal实例. 这个Map的确使用了弱引用,不过弱引用只是针对key. 每个key都弱引用指向threadlocal. 当把threadlocal实例置为null以后,没有任何强引用指向threadlocal实例,所以threadlocal将会被gc回收. 但是,我们的value却不能回收,因为存在一条从current thread连接过来的强引用. 只有当前thread结束以后, current thread就不会存在栈中,强引用断开, Current Thread, Map, value将全部被GC回收.
所以得出一个结论就是只要这个线程对象被gc回收,就不会出现内存泄露,但在threadLocal设为null和线程结束这段时间不会被回收的,就发生了我们认为的内存泄露。其实这是一个对概念理解的不一致,也没什么好争论的。最要命的是线程对象不被回收的情况,这就发生了真正意义上的内存泄露。比如使用线程池的时候,线程结束是不会销毁的,会再次使用的。就可能出现内存泄露。
PS.Java为了最小化减少内存泄露的可能性和影响,在ThreadLocal的get,set的时候都会清除线程Map里所有key为null的value。所以最怕的情况就是,threadLocal对象设null了,开始发生“内存泄露”,然后使用线程池,这个线程结束,线程放回线程池中不销毁,这个线程一直不被使用,或者分配使用了又不再调用get,set方法,那么这个期间就会发生真正的内存泄露。
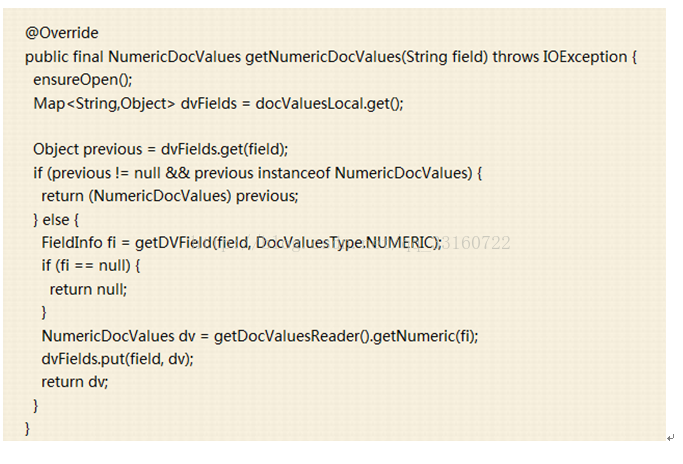
我们贴下lucene中跟内存泄露有关的关键代码

二十、spark的Thread.UncaughtExceptionHandler问题
1.默认spark会捕获所有的线程异常,一旦发现异常,直接报错退出进程
2.而lucene在索引合并的时候如果发生了异常,lucene merger schedule,会进行rallback,期望对线程抛出的异常不进行处理,而是应该忽略改异常,但是因为spark 的这个异常捕获,或导致改进程直接退出。
,这样的实现对于一个持久化的进程来说是不合理的,如果我们在创建索引过程中由于磁盘很繁忙,就很有可能遇到hdfs的异常,但是这个时候我们期望是程序能够进行重试而不是直接退出。故我们更改了这个地方的实现,让lucene索引合并的时候能够顺利进行重试,而不是一个小小的错误造成持久化进程的退出。
二十一、spark 内存泄露
1.高并发情况下的内存泄露的具体表现
很遗憾,spark的设计架构并不是为了高并发请求而设计的,我们尝试在网络条件不好的集群下,进行100并发的查询,在压测3天后发现了内存泄露。
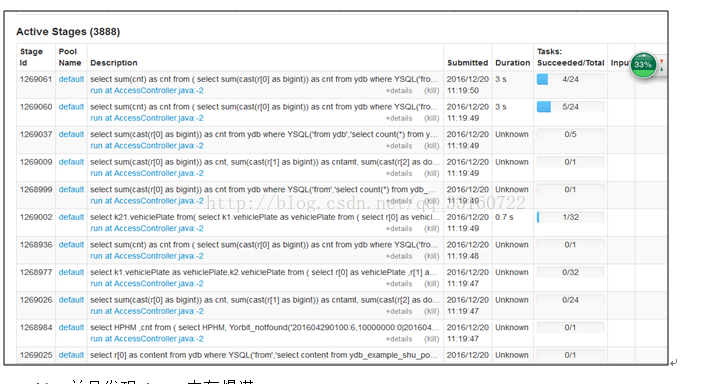
a)在进行大量小SQL的压测过程中发现,有大量的activejob在spark ui上一直处于pending状态,且永远不结束,如下图所示
b)并且发现driver内存爆满
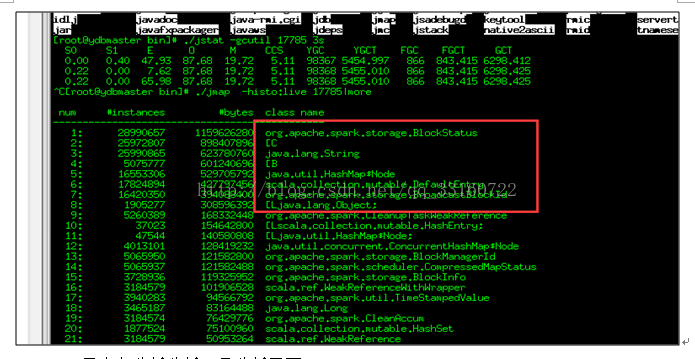
c)用内存分析分析工具分析了下
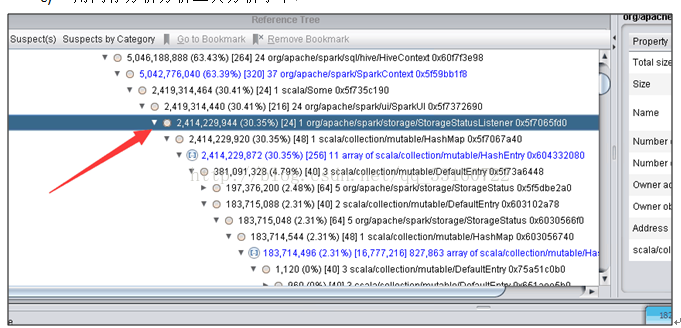
2.高并发下AsynchronousListenerBus引起的WEB UI的内存泄露
短时间内 SPARK 提交大量的SQL ,而且SQL里面存在大量的 union与join的情形,会创建大量的event对象,使得这里的 event数量超过10000个event ,
一旦超过10000个event就开始丢弃 event,而这个event是用来回收 资源的,丢弃了 资源就无法回收了。 针对UI页面的这个问题,我们将这个队列长度的限制给取消了。
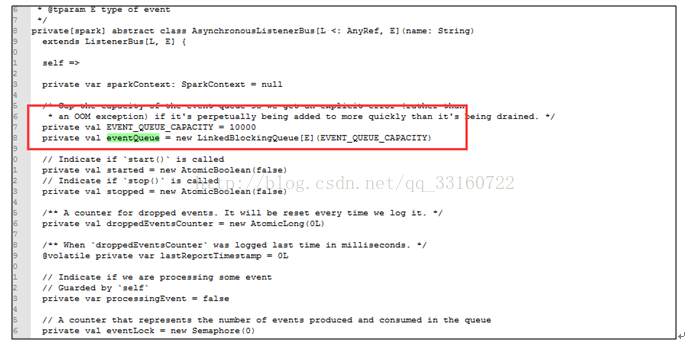
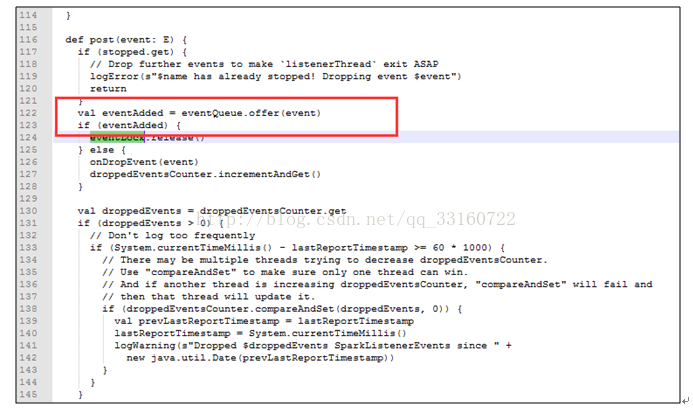
3.AsynchronousListenerBus本身引起的内存泄露
抓包发现

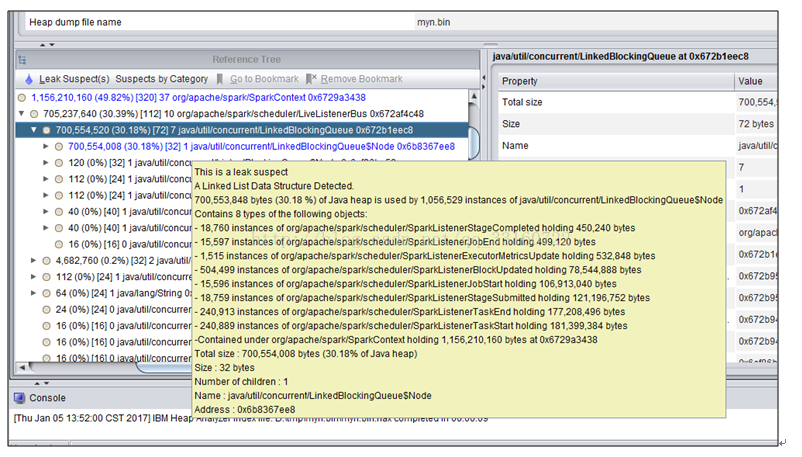
这些event是通过post方法传递的,并写入到队列里
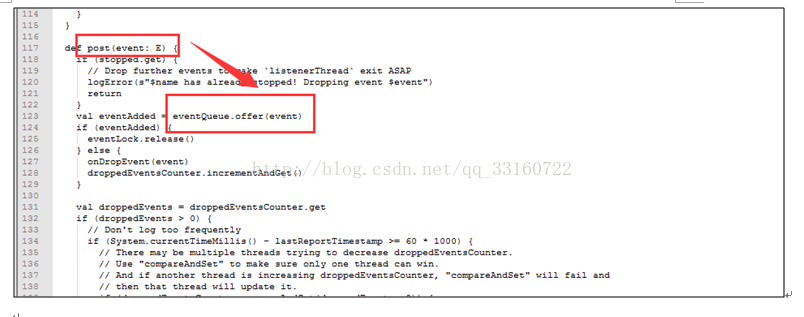
但是也是由一个单线程进行postToAll的
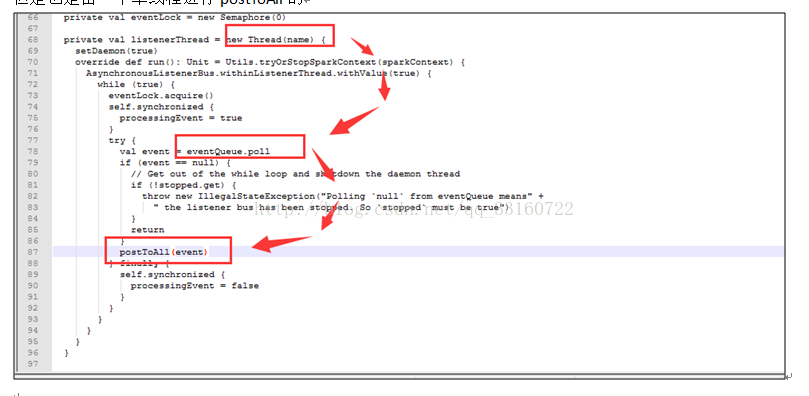
但是在高并发情况下,单线程的postToAll的速度没有post的速度快,会导致队列堆积的event越来越多,如果是持续性的高并发的SQL查询,这里就会导致内存泄露
接下来我们在分析下postToAll的方法里面,那个路径是最慢的,导致事件处理最慢的逻辑是那个?
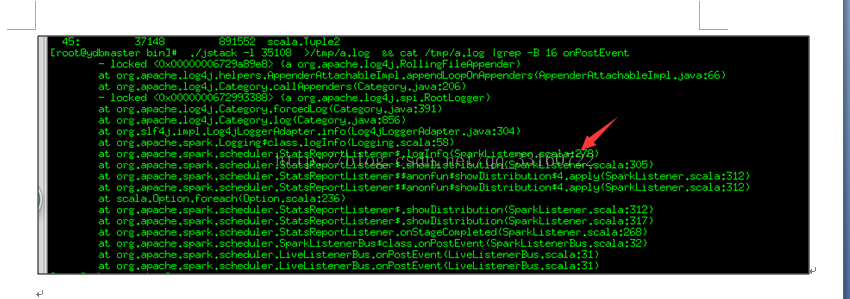
可能您都不敢相信,通过jstack抓取分析,程序大部分时间都阻塞在记录日志上
可以通过禁用这个地方的log来提升event的速度
log4j.logger.org.apache.spark.scheduler=ERROR
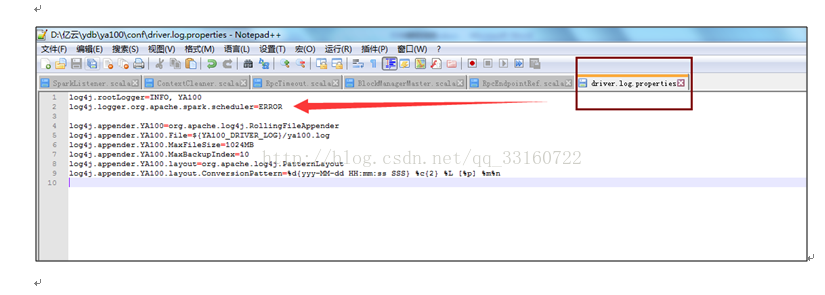
4.高并发下的Cleaner的内存泄露
说道这里,Cleaner的设计应该算是spark最糟糕的设计。spark的ContextCleaner是用于回收与清理已经完成了的 广播boradcast,shuffle数据的。但是高并发下,我们发现这个地方积累的数据会越来越多,最终导致driver内存跑满而挂掉。
l我们先看下,是如何触发内存回收的

没错,就是通过System.gc() 回收的内存,如果我们在jvm里配置了禁止执行System.gc,这个逻辑就等于废掉(而且有很多jvm的优化参数一般都推荐配置禁止system.gc 参数)
lclean过程
这是一个单线程的逻辑,而且每次清理都要协同很多机器一同清理,清理速度相对来说比较慢,但是SQL并发很大的时候,产生速度超过了清理速度,整个driver就会发生内存泄露。而且brocadcast如果占用内存太多,也会使用非常多的本地磁盘小文件,我们在测试中发现,高持续性并发的情况下本地磁盘用于存储blockmanager的目录占据了我们60%的存储空间。

我们再来分析下 clean里面,那个逻辑最慢
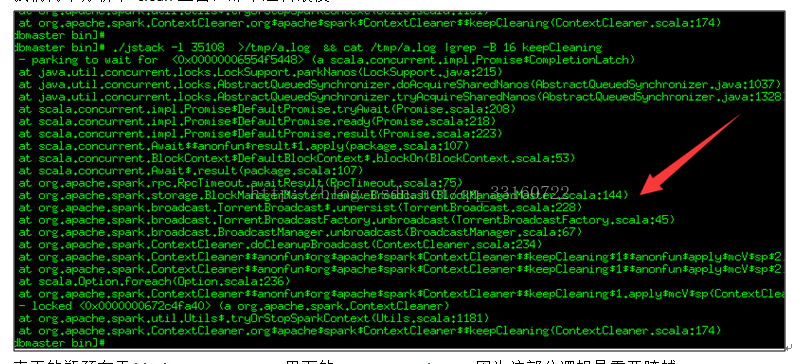
真正的瓶颈在于blockManagerMaster里面的removeBroadcast,因为这部分逻辑是需要跨越多台机器的。
针对这种问题,
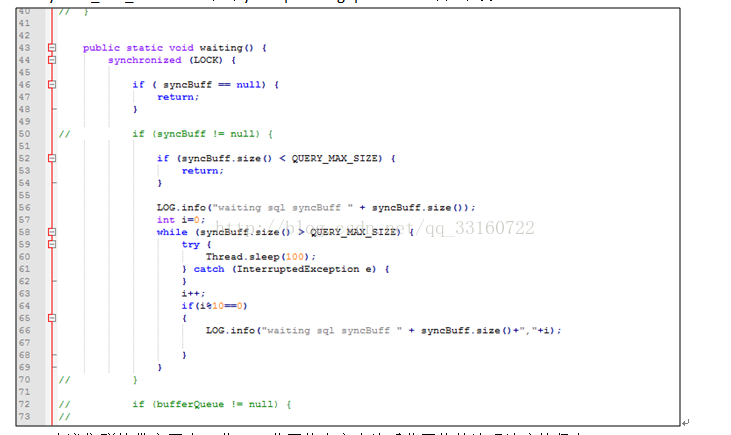
l我们在SQL层加了一个SQLWAITING逻辑,判断了堆积长度,如果堆积长度超过了我们的设定值,我们这里将阻塞新的SQL的执行。堆积长度可以通过更改conf目录下的ya100_env_default.sh中的ydb.sql.waiting.queue.size的值来设置。
l建议集群的带宽要大一些,万兆网络肯定会比千兆网络的清理速度快很多。
l给集群休息的机会,不要一直持续性的高并发,让集群有间断的机会。
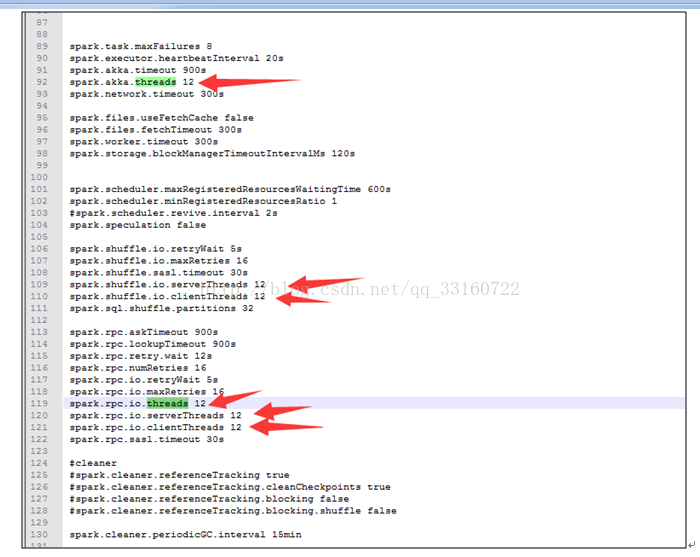
l增大spark的线程池,可以调节conf下的spark-defaults.conf的如下值来改善。
5.线程池与threadlocal引起的内存泄露
发现spark,hive,lucene都非常钟爱使用threadlocal来管理临时的session对象,期待SQL执行完毕后这些对象能够自动释放,但是与此同时spark又使用了线程池,线程池里的线程一直不结束,这些资源一直就不释放,时间久了内存就堆积起来了。
针对这个问题,延云修改了spark关键线程池的实现,更改为每1个小时,强制更换线程池为新的线程池,旧的线程数能够自动释放。
6.文件泄露
您会发现,随着请求的session变多,spark会在hdfs和本地磁盘创建海量的磁盘目录,最终会因为本地磁盘与hdfs上的目录过多,而导致文件系统和整个文件系统瘫痪。在YDB里面我们针对这种情况也做了处理。
7.deleteONExit内存泄露
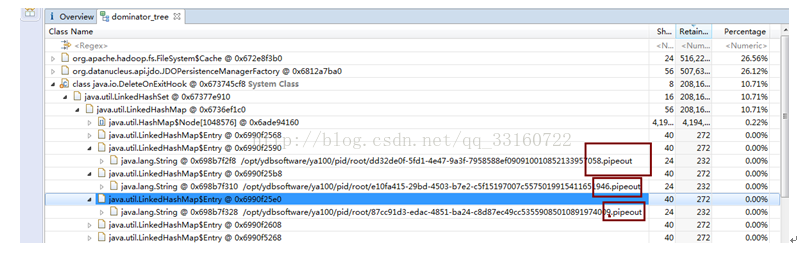
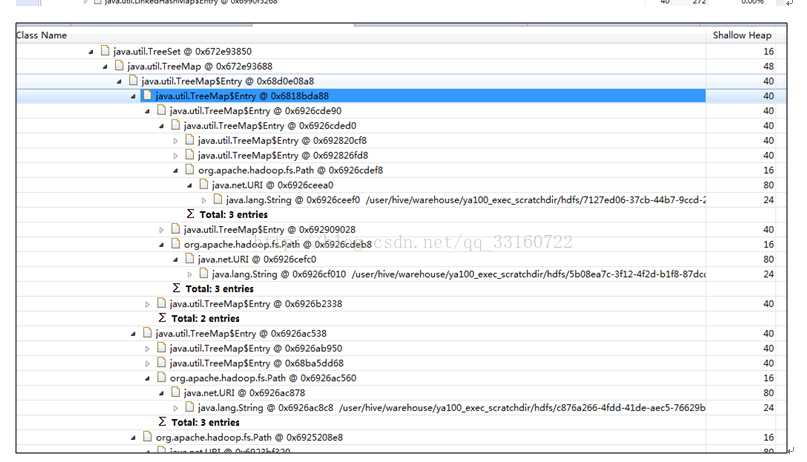
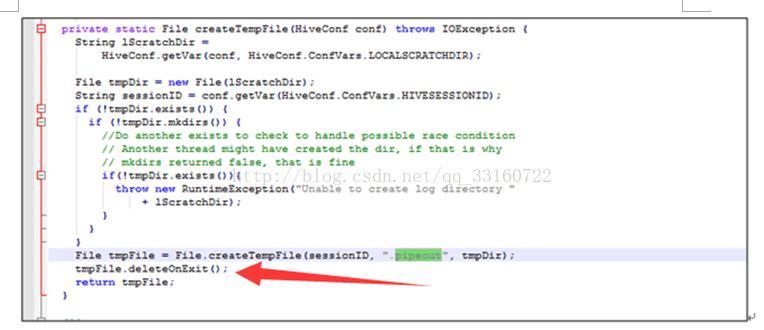
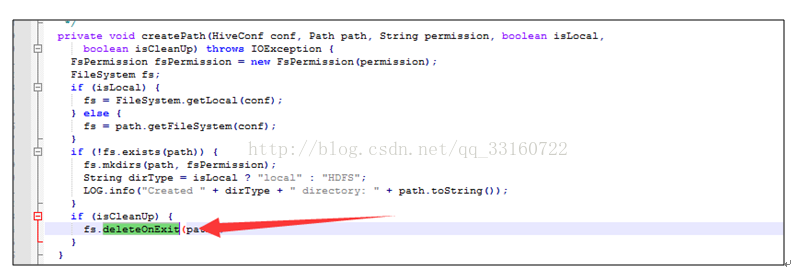
为什么会有这些对象在里面,我们看下源码
8.JDO内存泄露
多达10万多个JDOPersistenceManager
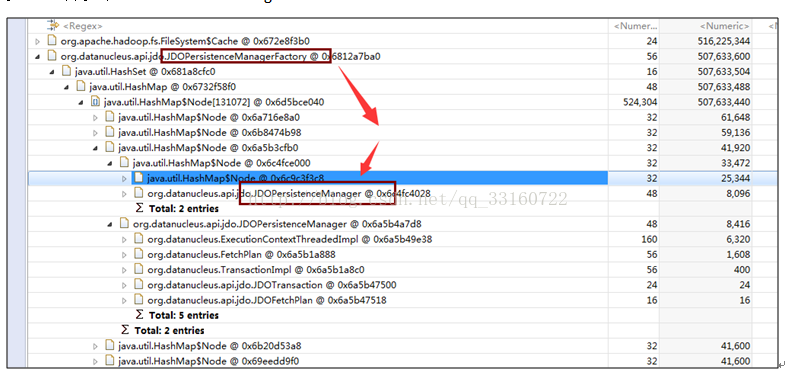
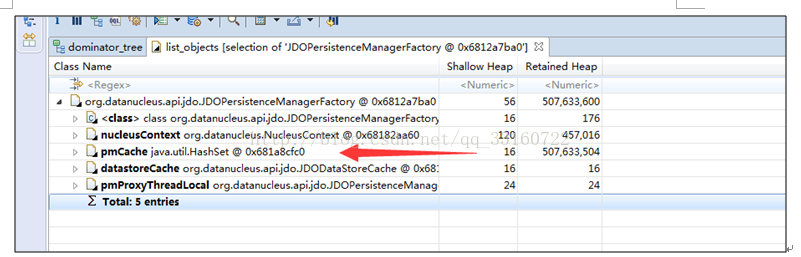
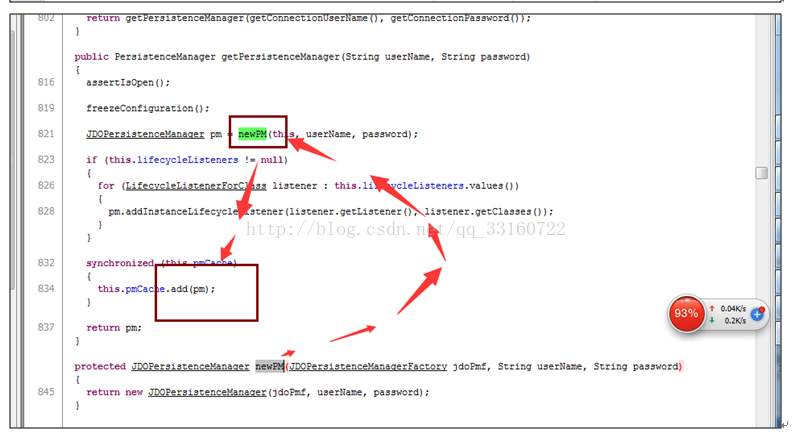
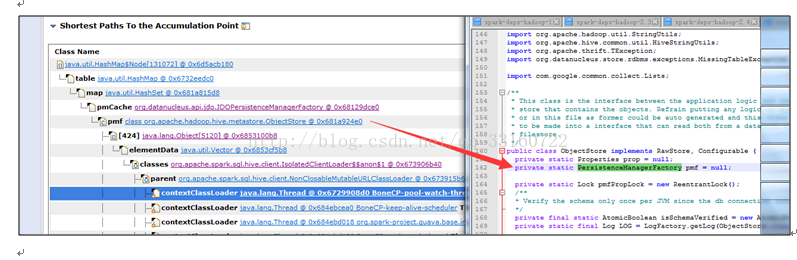
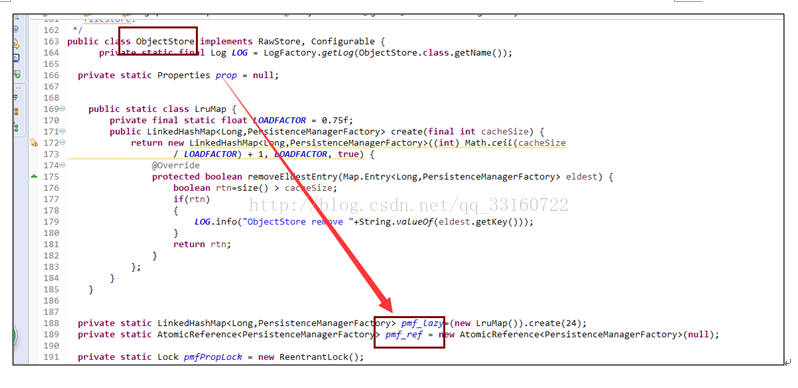
9.listerner内存泄露
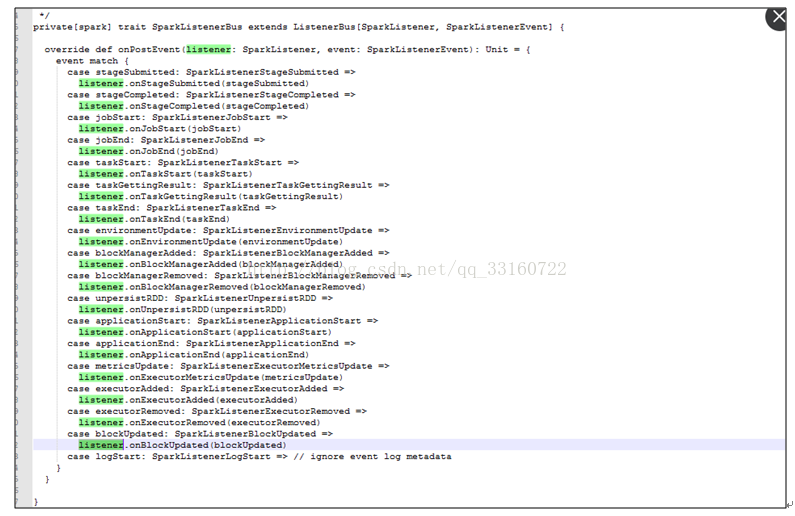
通过debug工具监控发现,spark的listerner随着时间的积累,通知(post)速度运来越慢
发现所有代码都卡在了onpostevent上
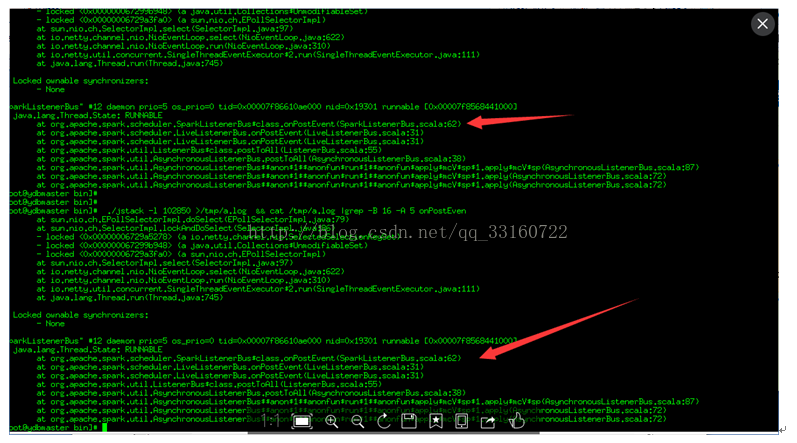
jstack的结果如下
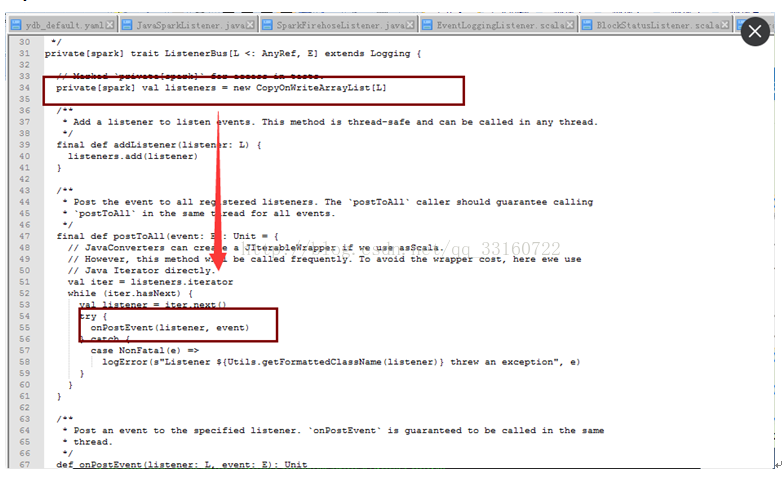
研究下了调用逻辑如下,发现是循环调用listerners,而且listerner都是空执行才会产生上面的jstack截图
通过内存发现有30多万个linterner在里面
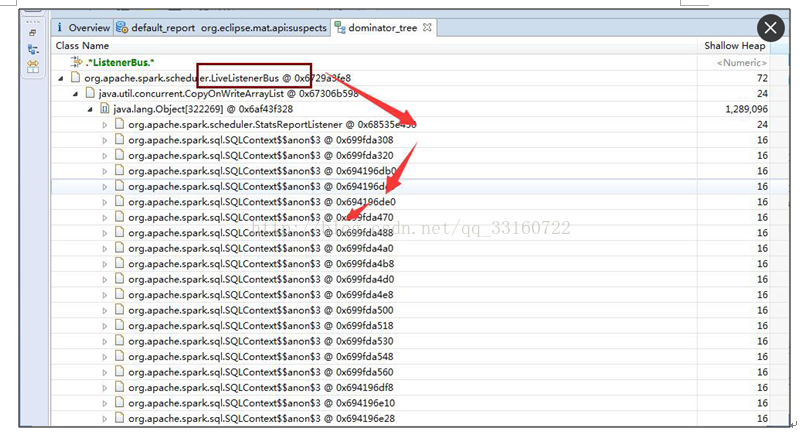
发现都是大多数都是同一个listener,我们核对下该处源码
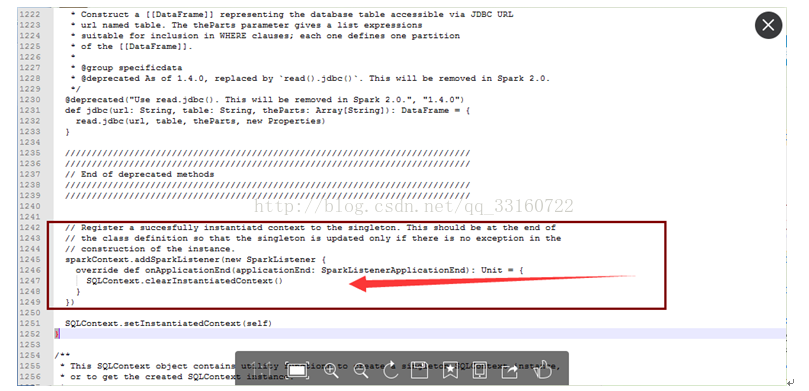
最终定位问题
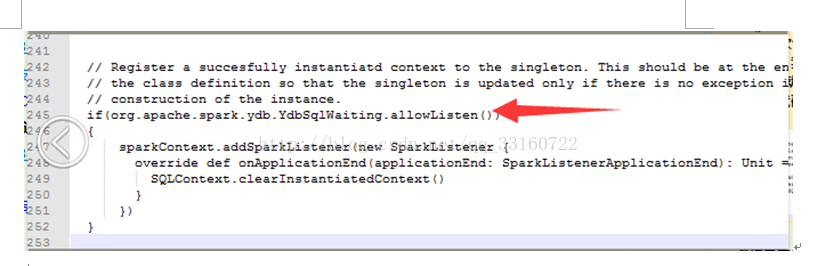
确系是这个地方的BUG ,每次创建JDBC连接的时候 ,spark就会增加一个listener, 时间久了,listener就会积累越来越多 针对这个问题 我简单的修改了一行代码,开始进入下一轮的压测
二十二、spark源码调优
测试发现,即使只有1条记录,使用 spark进行一次SQL查询也会耗时1秒,对很多即席查询来说1秒的等待,对用户体验非常不友好。针对这个问题,我们在spark与hive的细节代码上进行了局部调优,调优后,响应时间由原先的1秒缩减到现在的200~300毫秒。
以下是我们改动过的地方
1.SessionState 的创建目录 占用较多的时间
另外使用Hadoop namenode HA的同学会注意到,如果第一个namenode是standby状态,这个地方会更慢,就不止一秒,所以除了改动源码外,如果使用namenode ha的同学一定要注意,将active状态的node一定要放在前面。
2.HiveConf的初始化过程占用太多时间
频繁的hiveConf初始化,需要读取core-default.xml,hdfs-default.xml,yarn-default.xml
,mapreduce-default.xml,hive-default.xml等多个xml文件,而这些xml文件都是内嵌在jar包内的。
第一,解压这些jar包需要耗费较多的时间,第二每次都对这些xml文件解析也耗费时间。
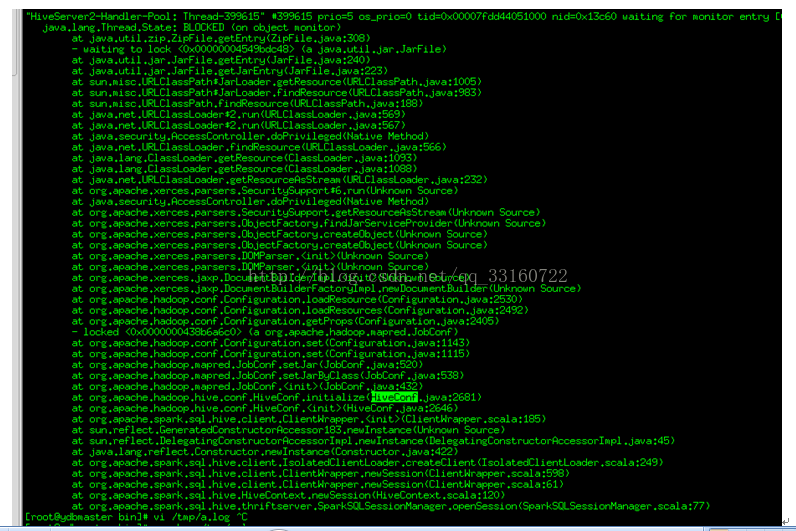
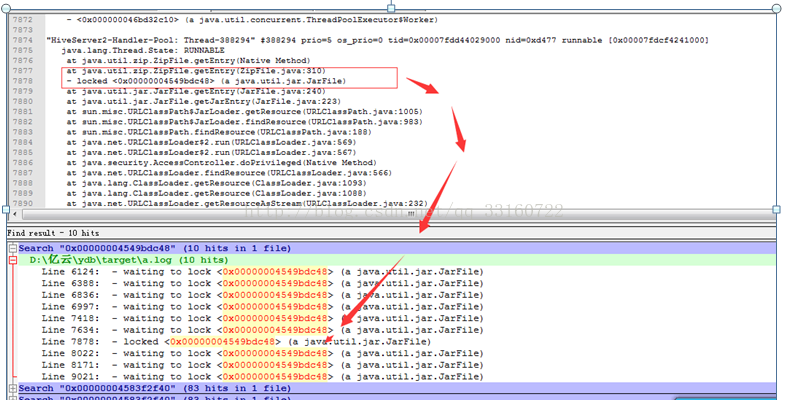
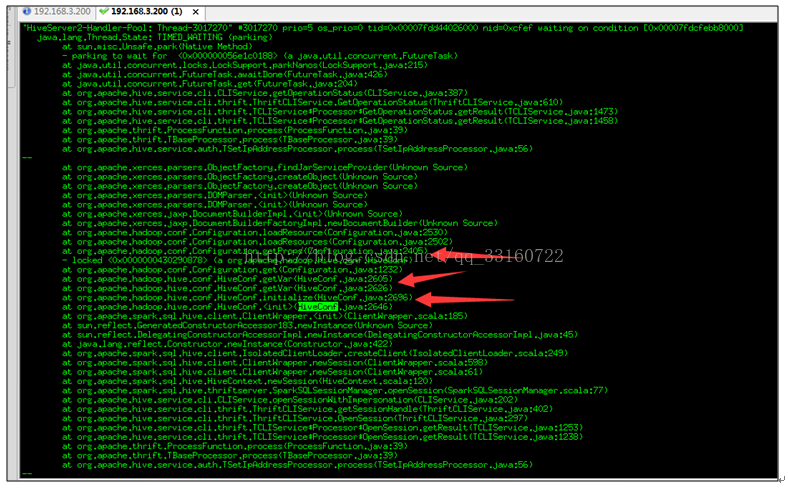
3.广播broadcast传递的hadoop configuration序列化很耗时
lconfiguration的序列化,采用了压缩的方式进行序列化,有全局锁的问题
lconfiguration每次序列化,传递了太多了没用的配置项了,1000多个配置项,占用60多Kb。我们剔除了不是必须传输的配置项后,缩减到44个配置项,2kb的大小。
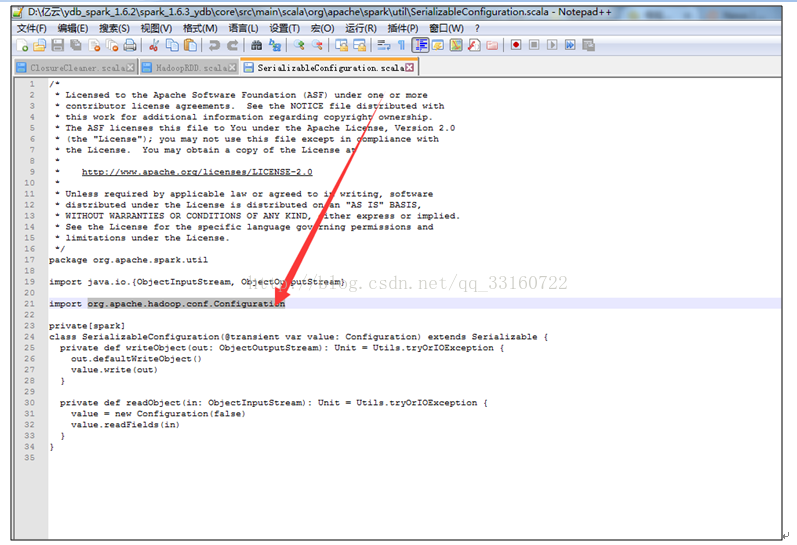
4.对spark广播数据broadcast的Cleaner的改进
由于SPARK-3015 的BUG,spark的cleaner 目前为单线程回收模式。
大家留意spark源码注释
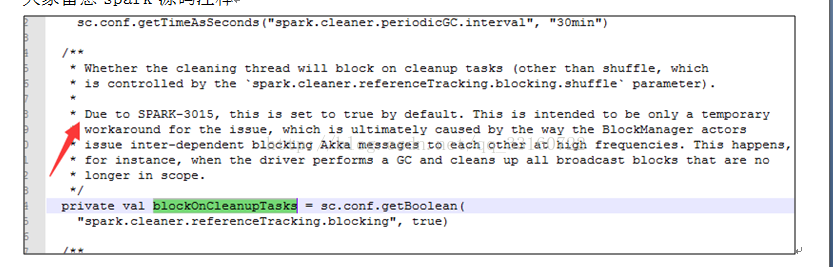
其中的单线程瓶颈点在于广播数据的cleaner,由于要跨越很多台机器,需要通过akka进行网络交互。
如果回收并发特别大,SPARK-3015 的bug报告会出现网络拥堵,导致大量的 timeout出现。
为什么回收量特变大呢? 其实是因为cleaner 本质是通过system.gc(),定期执行的,默认积累30分钟或者进行了gc后才触发cleaner,这样就会导致瞬间,大量的akka并发执行,集中释放,网络不瞬间瘫痪才不怪呢。
但是单线程回收意味着回收速度恒定,如果查询并发很大,回收速度跟不上cleaner的速度,会导致cleaner积累很多,会导致进程OOM(YDB做了修改,会限制前台查询的并发)。
不论是OOM还是限制并发都不是我们希望看到的,所以针对高并发情况下,这种单线程的回收速度是满足不了高并发的需求的。
对于官方的这样的做法,我们表示并不是一个完美的cleaner方案。并发回收一定要支持,只要解决akka的timeout问题即可。
所以这个问题要仔细分析一下,akka为什么会timeout,是因为cleaner占据了太多的资源,那么我们是否可以控制下cleaner的并发呢?比如说使用4个并发,而不是默认将全部的并发线程都给占满呢?这样及解决了cleaner的回收速度,也解决了akka的问题不是更好么?
针对这个问题,我们最终还是选择了修改spark的ContextCleaner对象,将广播数据的回收 改成多线程的方式,但现在了线程的并发数量,从而解决了该问题。
第十二章YDB技术原理
一、铺一条让Spark跑的更快的路
| |
二、YDB的本质
在Spark之上基于搜索引擎技术,实现索引和搜索功能。
既有搜索引擎的查询速度,又有Spark强大的分析计算能力。
可对多个字段进行关键字全匹配或模糊匹配检索,并可对检索结果集进行分组、排序、计算等统计分析操作。
三、多种技术组合-万亿数据秒级查询
四、整体架构
| |
| |
| |
五、通过读写双向BLOCK-BUFFER减少文件IO
| |
读写双向BLOCK-BUFFER的设计注意事项
| |
六、倒排索引与跳跃表
1.倒排索引与跳跃表基本原理
| |
| |
2.与开源的倒排索引系统相比
| l数据不要存储在本地 硬盘容易坏,恢复麻烦,每次数据都的从备份恢复么?20T数据的恢复要多久-7个小时够么? l系统资源问题 索引不要持久化的打开的,永远不关闭,在万亿规模下-太耗资源,要修改为LRU按需加载,不 经常使用的索引要关闭掉,节省资源。 lIO与内存问题 fdx,tvx,fnm,si,tip等文件是常驻内存的,要改为按需读取,提高首次打开索引的速度。 lLuceneDocvalues可以优化一下 三到四次重复IO,略加改动在索引合并是就可以节省2~3倍的IO。 多个segments之间要做关系映射,特别耗费CPU与内存,这也是SOLR耗内存的主要原因之一。 HASHSET操作太影响性能,要去掉换成数组。 lGC问题 创建Field的时候,有对象可以复用,否则GC问题严重。 (在solr里每个field要创建60多个对象,每行要创建600多个对象。) l数据倾斜问题 如 性别=男 and 手机号=1234567890。多个条件查询的时候要充分利用跳跃表。 |
3.针对范围查找我们所做的优化(skiplist IO 分析)
范围查找,尤其是时间范围的查找,在日常检索中会被经常使用,在范围查找中跳跃表的利用与否对性能影响非常大。
我们对lucene的默认范围查找做了一个小实验,对IO情况做了分析。
测试结果如下
1)普通的等值SQL分析-占用IO较小
筛选条件为:phonenum='13470881895' and amtdouble=50
2)使用小范围的 term扫描(IO也较小)
筛选条件为:phonenum='13470881895' and amtdouble like '([50 to 50])'
3)使用大范围的term扫描(IO非常大,超出想象)
筛选条件为:phonenum='13470881895' and (amtdouble>='50' or amtdouble<='50')
amtlong采用的数据类型为tlong类型,已经尽量通过tree的层次结构减少了term的个数,但是没想到,doclist本很成为瓶颈。
doclist用来存储一个term对应的doc id的列表,由于数据量很大,有些term可能达数亿甚至几十亿个。
问题分析
我们在上述查找中,都限定了手机号码,理论上,只要利用了skiplist的跳跃功能(lucene中对应advance方法),IO会很小,但是明显第三种测试的IO超出了我们的预期。
对于文档数量较少的范围查找,是否使用了跳跃功能对性能影响不大,但是YDB的场景更偏重大数据场景,倒排表对应的skiplist会特别长,如果没有使用跳跃功能就会出现上面那种一个查询耗费几个GB的IO的情况,严重影响查询性能。
我们针对每个IO,打印出详细的函数调用关系,验证我们的推测。
前两种情况均使用了advance。
第三种情况没有advance,而是采用了暴力遍历的方式,所以IO特别巨大,我们通过源码分析到了具体原因,超过16个term后,lucene默认就不会继续使用skiplist了。
如何解决?
lucene这样优化是有明显的原因的,即当term数量特别多的时候,跳跃的功能会带来更多的随机读,相反性能会更差。
但显然对于海量数据的情况下不适用,因IO巨大导致检索性能很慢,YDB针对范围查找做了如下的变更改动
16个term真的太小太小,我们更改为1024个,针对tlong,tint,tfloat,tdouble类型的数据将会有特别高的扫描性能。
大多时候term对应的skiplist也是有数据倾斜的,尤其是tlong,ting,tfloat,tdouble类型本身的分层特性。对于有数据倾斜的term我们要区别对待,对于skiplist很长的term采用跳跃功能能显著减少IO,对于skiplist很短的term则采用顺序读取,遍历的方式,减少随机读。
七、采用标签代替原始值-进行分组与排序
采用标签标记技术-让大数据化小
优点
1.重复值仅存储一份,可以减少存储空间占用。
2.标签值采用定长存储,可随机读取。
3.Group by分组计算的时候,使用标签代替原始值,数值型计算速度比字符串的计算速度快很多。
4.标签值的大小原始值的大小是对应的,故排序的时候也仅读取标签进行排序。
5.标签比原始值占的内存少。
缺点
1.如果数据重复值很低,存储空间相反比原始数据大。
2.如果重复值很低,且查询逻辑需要大量的根据标签值获取原始值的操作的时候,性能比原始值慢。
下图为替换示例,示意图
| |
| |
在真实的数据中,数据肯定是有重复的,比如说类目,性别,年龄,成交金额等信息,传统的分析工具存储的是原始的值,比如说我们有1千亿条数据,那么就要存储一千亿条记录,那么进行统计的时候,一条一条的读出这些类目肯定要慢的不得了。
还记得机器人总动员中的伊娃么?当数据规模达到一定程度以后,如果还是直接对原始值进行读取,对大数据的搬运工作将会特别的消耗体力,而且工作效率很低。
ydb对原始数据做了一些处理,基本思路是:虽然你有1千亿的数据,但是你的类目不会那么多,典型的系统一般是几万个类目,2~3个性别值,故ydb在存储的时候虽然有1千亿条记录,但是只会存储几万个类目,2个性别,这根原始的千亿条记录在数据规模上可是相差千万倍,那么在之后的统计(count,sum,avg等)势必会比传统的分析工具快上千倍万倍。
ydb的这种方式我们称为标签技术,就是将数据的真实值用一个数值标签来替换数据本身,原始数据每个值我们只存储一份,这样当有大量重复值的数据,可以节省很多IO,即使数据重复值很少,我们也可以一个数字来代表原始值,因为原始值有可能比较大,但数值确可以很好的压缩。
基本的处理过程如下图所示:
八、按单元格存储
YDB在列的处理上也采用了列存储的技术,列和列之间的值是分开的,基于YDB的一个项目(face),是一个几万个列的大宽表,用户分析的时候往往只关心几个列(维度),如果像传统的分析软件那样,将几万个列的值都读出来,然后只取其中几个列的值,那么太浪费了,所以列存储技术YDB这种基于检索的分析系统来说也是必备的。
但是仅仅列存储也是不够的,如果数据行数很多,即使至于一个列的暴力扫描也会很慢,所以YDB结合了索引+标签技术,如下图所示,我们使用了按照单元格存储的方式,每个单元格存储的是一个标签的值,而非原始数据,这样就可以进行定长的跳跃的读取,而且根据标签值的情况,我们可以采取不同的压缩算法。
| |
九、利用倒排索引跳过不需要的行与列-不进行暴力扫描
| |
YDB跟传统的分析工具最大的不同,是传统的分析工具很多时候采用的非常暴力的全表扫描的方式进行统计,有1千亿条记录,就要扫描1千亿行,你可能只需要在其中找几条记录而已,却要匹配1千亿次。
如果你没有变种人X教授的最强大脑,那么千万不要学他这么做,一个一个的找人,真的会累死的。
YDB使用索引直接定位到相关的记录,不需要的记录则全部都跳过去,这样无疑会节省很多的IO,从目前的几个案例来看,对几千亿的数据量进行一次检索耗时也就是几秒钟,这要是采用哪种暴力扫描的方式,怎么说不得几个小时才能算完啊。
这里面涉及倒排索引、跳跃表、delta压缩,doclist压缩与跳跃,bitset等相关跟索引有关的技术,看着很高大上,其实并不难理解。其实大家可以回想一下,我们小时候使用的新华字典了,目录其实就是一种索引,只有拼音,和偏旁部首等几个维度,但我们绝不会为了查找某一个字,翻遍每一页,而是借助目录的多级索引进行快速的定位,YDB与之类似,只不过复杂了一些,在细节上进行了很多的优化。
十、非排序的列最后延迟读取
|
|
十一、采用blockSort快速排序
blockSort排序(排序大跃进)
按照时间逆序排序可以说是很多日志系统的硬指标。在延云YDB系统中,我们改变了传统的暴力排序方式,通过索引技术,可以超快对数据进行单列排序,不需要全表暴力扫描,这个技术我们称之为blockSort,目前支持tlong,tdouble,tint,tfloat四种数据类型。
由于blockSort是借助搜索的索引来实现的,所以,采用blockSort的排序,不需要暴力扫描,性能有大幅度的提升。
blockSort的排序,并非是预计算的方式,可以全表进行排序,也可以基于任意的过滤筛选条件进行过滤排序。
十二、两段式查询
1.将原先的一次查询化为两次或多次查询。
2.第一次查询仅读取必备的列,如排序的列,需要group by与统计的列。
3.第一次查询不会获取数据的真实值,仅仅读取数据标签
4.所有的计算都完成后,因为数据进行过排序或汇总,剩余的记录数不多
这个时候在将标签从字典中转换为真实值,其他列的值也跟着读取过来。
十三、多区域数据实时导入
|
|
十四、采用PROCESS-LOCAL 更充分的利用cache
HadoopRdd只有HDFSCacheTaskLocation与HostTaskLocation,并没有ExecutorCacheTaskLocation无法做到PROCESS-LOCAL
但是注意下这里的源码,可以通过变通的方式实现。
其实进程在发生故障后,重新启动后,executorId是变化的。要注意修正
十五、创建持久化的进程
YDB与常规的spark和Hive应用的最大的区别是,YDB里面是在YDB启动的时候就先将Container启动好,而不是等一个SQL查询的时候才去动态的启动进程
1.这边避免来来回回的复制jar包
2.jvm本身创建进程开销很大
3.利用process-local的特性,可以更高效的利用Cache
十六、按需加载
数据表,索引,列信息,列的值,文件,文件cache均采用LRU的方式加载,只有用到才会打开,不经常使用的会释放掉资源。
十七、addIndexesNoOptimize的优化
该方法了解lucene的人应该知道,是向当前索引中添加一个新的索引,通常来说我们在mapreduce的第一个阶段会通过大并发创建小索引,在第二个阶段会通过addIndexesNoOptimize的方法将这些小的索引合并成一个完整的最终的索引。
目前lucene在这个地方的实现并不是特别好,addIndexesNoOptimize的处理逻辑是先将外部的索引copy到当前索引所在的目录,然后在进行合并,所以这个就多了一个copy的过程
这样做目前有3个缺点
第一、 当数据量特别大的时候,因为有了一次额外的copy,这种copy带来的开销是很大的,而且也是没必要的。
第二、 因为这这种copy将索引都copy到同一个目录上了,也就意味着在同一个磁盘上,那么在合并索引的时候还需要将这些文件重新读取一遍,单个磁盘的读取速度是有限的,不能利用多个磁盘进行合并会影响合并速度。
第三、 很多时候我希望当前索引下的不同的sigments能够分布到不同的硬盘上,这样检索的时候,同一个索引不同的sigments能够使用不同的硬盘进行检索。
原理:
针对上述问题,我们对lucene进行了一次比较小的改进,大家可以将其理解为Linux下的文件的软连接,实际的addIndexesNoOptimize方法并不会真正的发生copy,而是仅仅在当前的索引中做了一个标记,标记出他们附加的外部索引存储在什么位置,而不是真的去copy他们。
十八、 solr 的FQ Cache的不足以及在TOP N 全文检索上的改进
举个倒排表的例子
性别:男 =>1,2,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20
手机:1340100xxxx =>11
可以看出上述两个列的值有很大区别,性别列,因为值得重复程度特别多会有大量的docid对应性别是男的用户
而对于手机这个列为,一般一个手机号只对应一个docid
第一个场景
那么如果我去查找性别是男的 前10条记录 而不考虑任何的排序的话,我仅仅从头读出10个docid 就可以了,但实际上solr和lucene本身并没有这样干,solr是为了生成一个完整的bitset作为缓存,将全部的值都会读出来,之后作为缓存放在内存里,对于lucene来说它的默认的collect实现也是收集全部的docid,而不是收集到10个就停止了(它这样做的目的是为了全文检索里面的余弦排序,但很多场景并不需要排序),如果对应几千万条记录的话,IO浪费很多,是很亏的,很有必要自己单独写一个collect.
第二个场景
我们查找性别是男的并且手机号是 1340100xxxx的用户,很明显,结果就是docid=11的这个用户,这个处理的时候如若大家的过滤条件是通过solr的两个不同的fq参数传递进去的时候,就还会存在第一个场景的问题,性别是男的那个列浪费了很多的IO,所以这个地方要注意改为让他们在同一个FQ里面,使用lucene的booleanQuery去查询,这样因为doclist本身具有跳跃的性质,性别的那个列的相当一部分的docid都会跳跃过去,而节省了IO,所以自某些场景要做适当的优化
十九、ThreadLocal引起的内存泄露
无论是lucene还是spark 均使用了大量的ThreadLocal对象,采用普通线程使用ThreadLocal不会有问题,线程结束资源就释放了,但是如果想solr与ES那样采用线程池就会引起内存泄露的问题,因为线程池中的线程有可能永久都不释放,所以对于spark,solr,es都存在内存泄露的问题。
threadlocal里面使用了一个存在弱引用的map,当释放掉threadlocal的强引用以后,map里面的value却没有被回收.而这块value永远不会被访问到了. 所以存在着内存泄露. 最好的做法是将调用threadlocal的remove方法.
每个thread中都存在一个map, map的类型是ThreadLocal.ThreadLocalMap. Map中的key为一个threadlocal实例. 这个Map的确使用了弱引用,不过弱引用只是针对key. 每个key都弱引用指向threadlocal. 当把threadlocal实例置为null以后,没有任何强引用指向threadlocal实例,所以threadlocal将会被gc回收. 但是,我们的value却不能回收,因为存在一条从current thread连接过来的强引用. 只有当前thread结束以后, current thread就不会存在栈中,强引用断开, Current Thread, Map, value将全部被GC回收.
所以得出一个结论就是只要这个线程对象被gc回收,就不会出现内存泄露,但在threadLocal设为null和线程结束这段时间不会被回收的,就发生了我们认为的内存泄露。其实这是一个对概念理解的不一致,也没什么好争论的。最要命的是线程对象不被回收的情况,这就发生了真正意义上的内存泄露。比如使用线程池的时候,线程结束是不会销毁的,会再次使用的。就可能出现内存泄露。
PS.Java为了最小化减少内存泄露的可能性和影响,在ThreadLocal的get,set的时候都会清除线程Map里所有key为null的value。所以最怕的情况就是,threadLocal对象设null了,开始发生“内存泄露”,然后使用线程池,这个线程结束,线程放回线程池中不销毁,这个线程一直不被使用,或者分配使用了又不再调用get,set方法,那么这个期间就会发生真正的内存泄露。
我们贴下lucene中跟内存泄露有关的关键代码
二十、spark的Thread.UncaughtExceptionHandler问题
1.默认spark会捕获所有的线程异常,一旦发现异常,直接报错退出进程
2.而lucene在索引合并的时候如果发生了异常,lucene merger schedule,会进行rallback,期望对线程抛出的异常不进行处理,而是应该忽略改异常,但是因为spark 的这个异常捕获,或导致改进程直接退出。
,这样的实现对于一个持久化的进程来说是不合理的,如果我们在创建索引过程中由于磁盘很繁忙,就很有可能遇到hdfs的异常,但是这个时候我们期望是程序能够进行重试而不是直接退出。故我们更改了这个地方的实现,让lucene索引合并的时候能够顺利进行重试,而不是一个小小的错误造成持久化进程的退出。
二十一、spark 内存泄露
1.高并发情况下的内存泄露的具体表现
很遗憾,spark的设计架构并不是为了高并发请求而设计的,我们尝试在网络条件不好的集群下,进行100并发的查询,在压测3天后发现了内存泄露。
a)在进行大量小SQL的压测过程中发现,有大量的activejob在spark ui上一直处于pending状态,且永远不结束,如下图所示
b)并且发现driver内存爆满
c)用内存分析分析工具分析了下
2.高并发下AsynchronousListenerBus引起的WEB UI的内存泄露
短时间内 SPARK 提交大量的SQL ,而且SQL里面存在大量的 union与join的情形,会创建大量的event对象,使得这里的 event数量超过10000个event ,
一旦超过10000个event就开始丢弃 event,而这个event是用来回收 资源的,丢弃了 资源就无法回收了。 针对UI页面的这个问题,我们将这个队列长度的限制给取消了。
3.AsynchronousListenerBus本身引起的内存泄露
抓包发现
这些event是通过post方法传递的,并写入到队列里
但是也是由一个单线程进行postToAll的
但是在高并发情况下,单线程的postToAll的速度没有post的速度快,会导致队列堆积的event越来越多,如果是持续性的高并发的SQL查询,这里就会导致内存泄露
接下来我们在分析下postToAll的方法里面,那个路径是最慢的,导致事件处理最慢的逻辑是那个?
可能您都不敢相信,通过jstack抓取分析,程序大部分时间都阻塞在记录日志上
可以通过禁用这个地方的log来提升event的速度
log4j.logger.org.apache.spark.scheduler=ERROR
4.高并发下的Cleaner的内存泄露
说道这里,Cleaner的设计应该算是spark最糟糕的设计。spark的ContextCleaner是用于回收与清理已经完成了的 广播boradcast,shuffle数据的。但是高并发下,我们发现这个地方积累的数据会越来越多,最终导致driver内存跑满而挂掉。
l我们先看下,是如何触发内存回收的
没错,就是通过System.gc() 回收的内存,如果我们在jvm里配置了禁止执行System.gc,这个逻辑就等于废掉(而且有很多jvm的优化参数一般都推荐配置禁止system.gc 参数)
lclean过程
这是一个单线程的逻辑,而且每次清理都要协同很多机器一同清理,清理速度相对来说比较慢,但是SQL并发很大的时候,产生速度超过了清理速度,整个driver就会发生内存泄露。而且brocadcast如果占用内存太多,也会使用非常多的本地磁盘小文件,我们在测试中发现,高持续性并发的情况下本地磁盘用于存储blockmanager的目录占据了我们60%的存储空间。
我们再来分析下 clean里面,那个逻辑最慢
真正的瓶颈在于blockManagerMaster里面的removeBroadcast,因为这部分逻辑是需要跨越多台机器的。
针对这种问题,
l我们在SQL层加了一个SQLWAITING逻辑,判断了堆积长度,如果堆积长度超过了我们的设定值,我们这里将阻塞新的SQL的执行。堆积长度可以通过更改conf目录下的ya100_env_default.sh中的ydb.sql.waiting.queue.size的值来设置。
l建议集群的带宽要大一些,万兆网络肯定会比千兆网络的清理速度快很多。
l给集群休息的机会,不要一直持续性的高并发,让集群有间断的机会。
l增大spark的线程池,可以调节conf下的spark-defaults.conf的如下值来改善。
5.线程池与threadlocal引起的内存泄露
发现spark,hive,lucene都非常钟爱使用threadlocal来管理临时的session对象,期待SQL执行完毕后这些对象能够自动释放,但是与此同时spark又使用了线程池,线程池里的线程一直不结束,这些资源一直就不释放,时间久了内存就堆积起来了。
针对这个问题,延云修改了spark关键线程池的实现,更改为每1个小时,强制更换线程池为新的线程池,旧的线程数能够自动释放。
6.文件泄露
您会发现,随着请求的session变多,spark会在hdfs和本地磁盘创建海量的磁盘目录,最终会因为本地磁盘与hdfs上的目录过多,而导致文件系统和整个文件系统瘫痪。在YDB里面我们针对这种情况也做了处理。
7.deleteONExit内存泄露
为什么会有这些对象在里面,我们看下源码
8.JDO内存泄露
多达10万多个JDOPersistenceManager
9.listerner内存泄露
通过debug工具监控发现,spark的listerner随着时间的积累,通知(post)速度运来越慢
发现所有代码都卡在了onpostevent上
jstack的结果如下
研究下了调用逻辑如下,发现是循环调用listerners,而且listerner都是空执行才会产生上面的jstack截图
通过内存发现有30多万个linterner在里面
发现都是大多数都是同一个listener,我们核对下该处源码
最终定位问题
确系是这个地方的BUG ,每次创建JDBC连接的时候 ,spark就会增加一个listener, 时间久了,listener就会积累越来越多 针对这个问题 我简单的修改了一行代码,开始进入下一轮的压测
二十二、spark源码调优
测试发现,即使只有1条记录,使用 spark进行一次SQL查询也会耗时1秒,对很多即席查询来说1秒的等待,对用户体验非常不友好。针对这个问题,我们在spark与hive的细节代码上进行了局部调优,调优后,响应时间由原先的1秒缩减到现在的200~300毫秒。
以下是我们改动过的地方
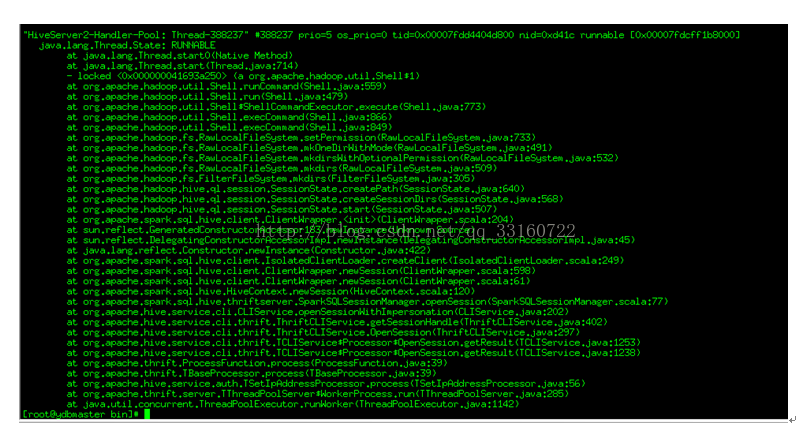
1.SessionState 的创建目录 占用较多的时间
另外使用Hadoop namenode HA的同学会注意到,如果第一个namenode是standby状态,这个地方会更慢,就不止一秒,所以除了改动源码外,如果使用namenode ha的同学一定要注意,将active状态的node一定要放在前面。
2.HiveConf的初始化过程占用太多时间
频繁的hiveConf初始化,需要读取core-default.xml,hdfs-default.xml,yarn-default.xml
,mapreduce-default.xml,hive-default.xml等多个xml文件,而这些xml文件都是内嵌在jar包内的。
第一,解压这些jar包需要耗费较多的时间,第二每次都对这些xml文件解析也耗费时间。
3.广播broadcast传递的hadoop configuration序列化很耗时
lconfiguration的序列化,采用了压缩的方式进行序列化,有全局锁的问题
lconfiguration每次序列化,传递了太多了没用的配置项了,1000多个配置项,占用60多Kb。我们剔除了不是必须传输的配置项后,缩减到44个配置项,2kb的大小。
4.对spark广播数据broadcast的Cleaner的改进
由于SPARK-3015 的BUG,spark的cleaner 目前为单线程回收模式。
大家留意spark源码注释
其中的单线程瓶颈点在于广播数据的cleaner,由于要跨越很多台机器,需要通过akka进行网络交互。
如果回收并发特别大,SPARK-3015 的bug报告会出现网络拥堵,导致大量的 timeout出现。
为什么回收量特变大呢? 其实是因为cleaner 本质是通过system.gc(),定期执行的,默认积累30分钟或者进行了gc后才触发cleaner,这样就会导致瞬间,大量的akka并发执行,集中释放,网络不瞬间瘫痪才不怪呢。
但是单线程回收意味着回收速度恒定,如果查询并发很大,回收速度跟不上cleaner的速度,会导致cleaner积累很多,会导致进程OOM(YDB做了修改,会限制前台查询的并发)。
不论是OOM还是限制并发都不是我们希望看到的,所以针对高并发情况下,这种单线程的回收速度是满足不了高并发的需求的。
对于官方的这样的做法,我们表示并不是一个完美的cleaner方案。并发回收一定要支持,只要解决akka的timeout问题即可。
所以这个问题要仔细分析一下,akka为什么会timeout,是因为cleaner占据了太多的资源,那么我们是否可以控制下cleaner的并发呢?比如说使用4个并发,而不是默认将全部的并发线程都给占满呢?这样及解决了cleaner的回收速度,也解决了akka的问题不是更好么?
针对这个问题,我们最终还是选择了修改spark的ContextCleaner对象,将广播数据的回收 改成多线程的方式,但现在了线程的并发数量,从而解决了该问题。














 4549
4549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









