






一.简介
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。现在形成一个高速发展应用广泛的生态系统。
Spark 是一个用来实现快速而通用的集群计算的平台。
Spark 的一个主要特点就是能够在内存中进行计算,因而更快。不过即使是必须在磁盘上进行的复杂计算,Spark 依然比MapReduce 更加高效(官方称其速度比MapReduce要快100倍)
Spark 所提供的接口非常丰富。除了提供基于Python、Java、Scala 和SQL 的简单易用的API 以及内建的丰富的程序库以外,Spark 还能和其他大数据工具密切配合使用。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
二.组件
1.Spark Core(本文章重点讲它的核心)
2.Spark SQL
3.SparkSteaming
4.Mlib(机器学习)
5.GraghX
6.Cluster Manager
1)独立调度器
2)Yarn
3 )Mesos
三.安装
spark有三种运行模式(因为安装不是本文的重点所以只提一下简单步骤)
1.local模式安装:
1.下载spark2.1.2版本
2.t解压
3.配置SPARK_HOME
4.spark shell命令
spark-shell --master local[*]
5.spark Web UI(local):http://[ipaddress]:4040
2.standalone模式安装:
1.下载spark2.1.2版本
2.解压
3.配置SPARK_HOME
4.配置conf/slaves文件,添加worker节点
5.配置SSH无密登录
6.将spark文件分发到其他节点上
7.启动服务 sbin下./start-all.sh
8.停止服务:sbin下./stop-all.sh
9.spark Web UI(standalone):http://[ipaddress]:8080
1.下载spark2.1.2版本
2.解压
3.配置SPARK_HOME
4.修改spark-env.sh
添加环境变量:HADOOP_CONF_DIR=/home/hadoop/soft/hadoop/etc/hadoop
5.修改hadoop中yarn-site.xml
<property>
<description>Whether physical memory limits will be enforced for
containers.</description>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<description>Whether virtual memory limits will be enforced for
containers.</description>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
四.Spark的组件
1.Application
------------------------------------
Application是指用户编写的spark应用程序,包含驱动程序和分布在集群中多个节点上运行的执行进程,在执行过程中由一个或多个作业组成。
Spark会将一个完整的作业拆分为多个任务进行分布式计算,以提高spark应用程序的执行效率。
同一个spark集群可以同时运行多个spark应用程序。
2.Driver
-------------------------------------
Driver是Spark中的驱动程序,是用户编写作业提交后的阶段,也就是代码编写结束提交至spark集群后的过程。在这个过程中,Spark context会被创建,随着Spark context被创建之后,其会根据RDD之间的依赖关系构建有向无环图(DAG)。
最终被创建出的DAG会被提交至高级调度接口(DagScheduler),并转化为多个批处理任务。
通常用SparkContext代表Driver。
3.Cluster Manager
-------------------------------------
Cluster Manager 指的是进行资源调度的外部服务,目前 spark 支持的资源调度方式有
Standalone
Yarn
Mesos
4.Master
-------------------------------------
Master节点为Spark standalone模式下的主节点
Master节点负责在Spark应用程序执行时管理以及分配Spark集群资源,功能类似于ResourceManager
Spark standalone模式默认为单Master节点,存在单点故障的隐患。可以通过Spark HA解决单点故障的问题,需要在spark-env.sh中添加zookeeper的配置
5.Worker
-------------------------------------
Worker为集群中的工作节点,Worker为集群中任何可以运行Spark程序的节点,在Spark典型的Master-Slave架构中扮演从节点的角色。
在Spark standalone运行模式下worker节点为slaves配置文件中配置的节点
在Spark on yarn模式下worker节点为NodeManager节点
6.Executor
-------------------------------------
Executor为Spark各个Worker节点中负责执行任务的执行进程,该进程负责运行各个任务,并负责将数据存在内存或者磁盘上。
每个Spark应用程序都有各自独立的Executor进程在Worker节点中执行,也就是说,一个Worker节点中可以存在多个Executor进程
在一个Executor进程中可以包含多个Task
7.Stage
-------------------------------------
当某个操作触发计算,向 DAGScheduler 提交作业时,DAGScheduler 需要从RDD依赖链最末端的RDD出发,遍历整个RDD依赖链,划分Stage任务阶段,
并决定各个Stage之间的依赖关系。Stage的划分是以 ShuffleDependency 为依据的,也就是说当某个 RDD 的运算需要将数据进行 Shuffle 时,
这个包含了 Shuffle 依赖关系的RDD将被用来作为输入信息,构建一个新的 Stage,由此为依据划分 Stage,
可以确保有依赖关系的数据能够按照正确的顺序得到处理和运算。
8.Task
-------------------------------------
一个 Job 被拆分成若干个 Stage,每个 Stage 执行一些计算,产生一些中间结果。它们的目的是最终生成这个 Job 的计算结果。
而每个 Stage 是一个 task set,包含若干个 task。Task 是 Spark 中最小的工作单元,在一个 executor 上完成一个特定的任务。
9.DAG 有向无环图
-------------------------------------
Spark 的有向无环图(DAG)的分布式并行计算框架进行计算时常常需要根据 RDD 之间的依赖关系对计算的过程划分不同的计算节点。
10Dependency 血统
-------------------------------------
RDD 之间只存在两种依赖关系,分别为
窄依赖
宽依赖
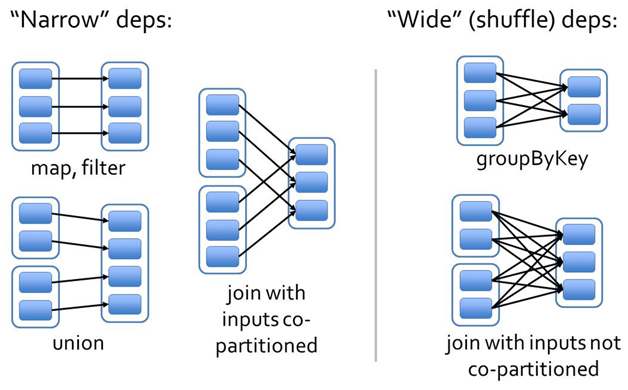
Narrow Dependencies是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。
Wide Dependencies是指子RDD的分区依赖于父RDD的多个分区或所有分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。(说白了窄依赖就是一个父类rdd只对应一个分区,没有计算结果,宽依赖指经过shuffle阶段不同分区的计算结果在一个分区)
窄依赖的函数有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的函数有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
五.作业执行
Spark作业执行原理:Spark的作业和任务调度系统是Spark的核心,计算的根本是基于有向无环图的计算模型以及容错机制,Spark作业执行大概分为四个阶段:
1.构建DAG
2.DAG切割
3.任务调度
4.执行任务
如下图:
下边我来详细说一下各个阶段:
1.构建DAG:
使用算子操作RDD进行各种转换操作,最后通过行动操作触发Spark作业运行。提交之后Spark会根据转换过程所产生的RDD之间的依赖关系构建有向无环图。如下图:
2.DAG切割:
DAG切割主要根据RDD的依赖是否为宽依赖来决定切割节点,当遇到宽依赖就将任务划分为一个新的调度阶段(Stage)。每个Stage中包含一个或多个Task。这些Task将形成任务集(TaskSet),提交给底层调度器进行调度运行。
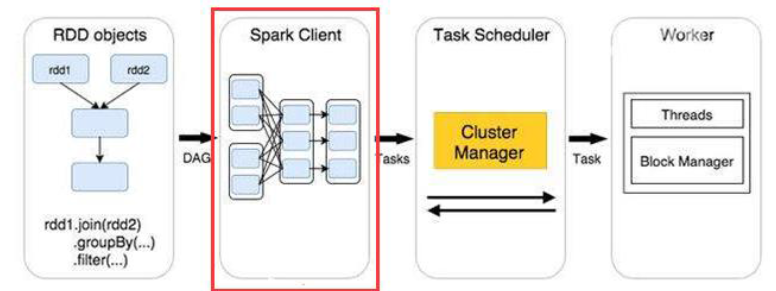
3.任务调度:
每一个Spark任务调度器只为一个SparkContext实例服务。当任务调度器收到任务集后负责把任务集以任务的形式分发至Worker节点的Executor进程中执行,如果某个任务失败,任务调度器负责重新分配该任务的计算。
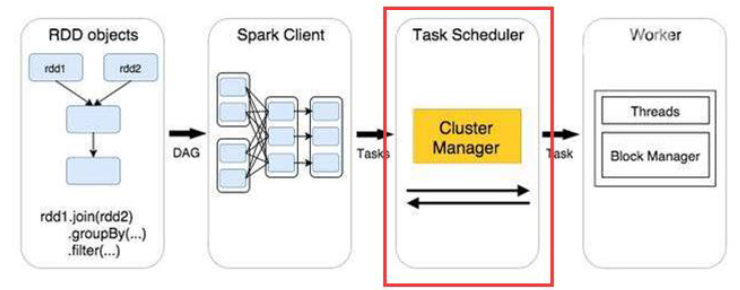
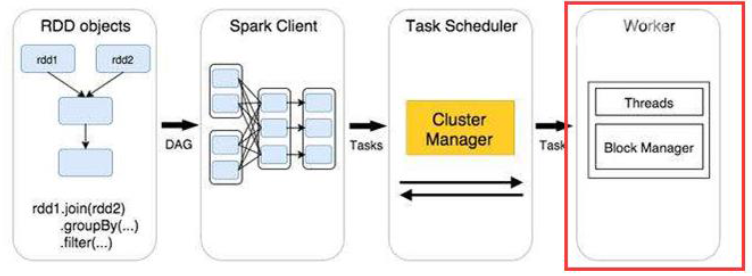
4.执行任务:
当Executor收到发送过来的任务后,将以多线程的方式执行任务的计算,每个线程负责一个任务,任务结束后会根据任务的类型选择相应的返回方式将结果返回给任务调度器。














 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









