






不少朋友经常会问我以下问题:
-
58到家有没有使用数据库中间件
-
使用了什么数据库中间件,是自研,还是第三方
-
怎么实现的,是基于客户端的中间件,还是基于服务端的中间件
-
使用中间件后,join/子查询/集函数/事务等问题是怎么解决的
-
…
你是不是也有类似的疑问?
然而,“究竟为什么要引入数据库中间件”却很少有人问及。 “架构师之路”文章思路,以解决“为什么”为优先,借着近期撰写互联网分层架构系列文章,讲一讲这个核心问题:
-
究竟为什么要引入数据库中间件

经过连续分层架构演进,DAO层,基础数据服务化,通用业务服务化,前后端分离之后,一个业务系统的后端结构如上:
-
web-view层通过http接口,从web-data获取json数据(前后端分离)
-
web-data层通过RPC接口,从biz-service获取数据(通用业务服务)
-
biz-service层通过RPC接口,从base-service获取数据(基础数据服务)
-
base-service层通过DAO,从db获取数据(DAO)
-
db存储数据
随着时间的推移,数据量会越来越大,base-service通过DAO来访问db的性能会越来越低,需要开始考虑对db进行水平切分,一旦db进行水平切分,原来很多SQL可以支持的功能,就需要base-service层来进行特殊处理:
-
有些数据需要路由到特定的水平切分库
-
有些数据不确定落在哪一个水平切分库,就需要访问所有库
-
有些数据需要访问全局的库,拿到数据的全局视野,到service层进行额外处理
-
…
更具体的,对于前台高并发的业务,db水平切分后,有这么几类典型的业务场景及应对方案。特别强调一下,此处应对的是“前台”“高并发”“db水平切分”的场景,对于后台的需求,将通过前台与后台分离的架构处理,不在此处讨论。
一:partition key上的单行查询
典型场景:通过uid查询user
场景特点:
-
通过patition key查询
-
每次只返回一行记录
解决方案:base-service层通过patition key来进行库路由
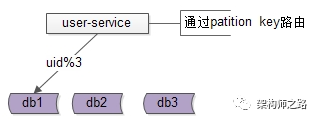
如上图:
-
user-service底层user库,分库patition key是uid
-
uid上的查询,user-service可以直接定位到库
二、非patition key上的单行查询
典型场景:通过login_name查询user
场景特点:
-
通过非patition key查询
-
每次只返回一行记录
解决方案1:base-service层访问所有库
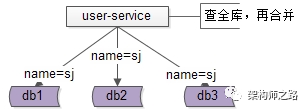
如上图:
-
user-service通过login_name先查全库
-
结果集在user-service再合并,最终返回一条记录
解决方案2:base-service先查mapping库,再通过patition key路由
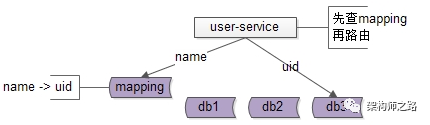
如上图:
-
新建mapping库,记录login_name到uid的映射关系
-
当有非 patition key的查询时,先通过login_name查询uid
-
再通过patition key进行路由,最终返回一条记录
解决方案3:基因法
关于“基因法”解决非patition key上的查询需求详见《分库后,非patition key上访问的多种解决办法》。
三、patition key上的批量查询
典型场景:用户列表uid上的IN查询
场景特点:
-
通过patition key查询
-
每次返回多行记录
解决方案1:base-service层访问所有库,结果集到base-service合并
解决方案2:base-service分析路由规则,按需访问
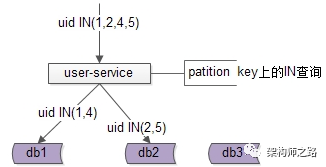
如上图:
-
base-service根据路由规则分析,判断出有些数据落在库1,有些数据落在库2
-
base-service按需访问相关库,而不是访问全库
-
base-service合并结果集,返回列表数据
四、非patition key上的夸库分页需求
关于分库后,夸库分页的查询需求,详见《业界难题,夸库分页的四种方案》。
五、其他需求…
本文写到这里,上述一、二、三、四、五其实都不是重点,base-service层通过各种各样的奇技淫巧,能够解决db水平切分后的数据访问问题,只不过:
-
base-service层的复杂度提高了
-
数据的获取效率降低了
当需要进行db水平切分的base-service越来越多以后,此时分层架构会变成下面这个样子:
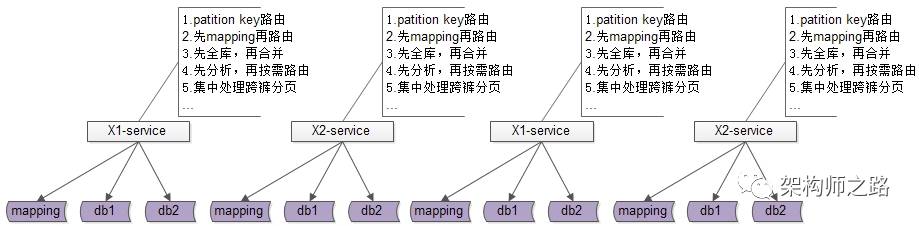
底层的复杂性会扩散到各个base-service,所有的base-service都要关注:
-
patition key路由
-
非patition key查询,先mapping,再路由
-
先全库,再合并
-
先分析,再按需路由
-
夸库分页处理
-
…
这个架构图是不是看上去很别扭?如何让数据的获取更加高效快捷呢?
数据库中间件的引入,势在必行。
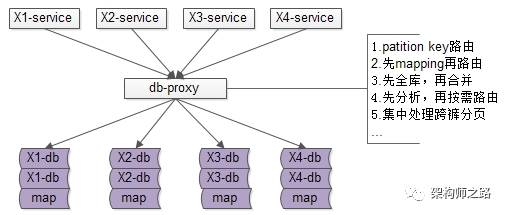
这是“基于服务端”的数据库中间件架构图:
-
base-service层,就像访问db一样,访问db-proxy,高效获取数据
-
所有底层的复杂性,都屏蔽在db-proxy这一层
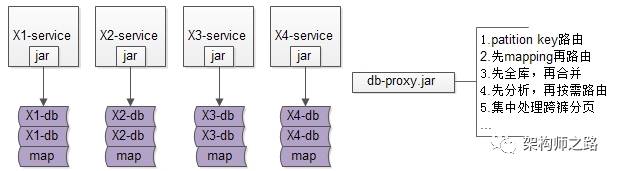
这是“基于客户端”的数据库中间件架构图:
-
base-service层,通过db-proxy.jar,高效获取数据
-
所有底层的复杂性,都屏蔽在db-proxy.jar这一层
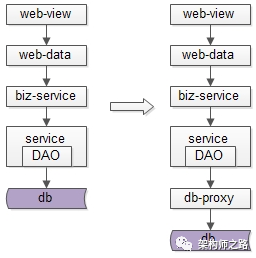
结论:
当数据库水平切分,base-service层获取db数据过于复杂,成为通用痛点的时候,就应该抽象出数据库中间件,简化数据获取过程,提高数据获取效率,向上游屏蔽底层的复杂性。
任何脱离业务的架构设计,都是耍流氓。
“为什么”比“怎么样”更重要。
阅读前序文章,“分层架构设计”的背景与来龙去脉更加清晰:
若有收获,随手帮转哟。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









