






互联网分层架构的本质,是数据的移动。
互联网分层架构演进的核心原则:
-
让上游更高效的获取与处理数据,复用
-
让下游能屏蔽数据的获取细节,封装
这些在上一篇《互联网分层架构的本质》中有详尽的描述,在实际系统架构演进过程中,如何利用这两个原则,对系统逐步进行分层抽象呢?咱们先从后端系统开始讲解。
本文主要解答两个问题:
-
后端架构,什么时候进行DAO层的抽象
-
后端架构,什么时候进行数据服务层的抽象
核心问题一:什么时候进行DAO层的抽象

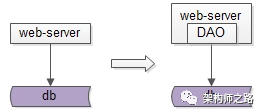
一个业务系统最初的后端结构如上:
-
web-server层从db层获取数据并进行加工处理
-
db层存储数据
此时,web-server层如何获取底层的数据呢?

web-server层获取数据的一段伪代码如上,不用纠结代码的细节,也不用纠结不同编程语言与不同数据库驱动的差异,其获取数据的过程大致为:
-
创建一个与数据库的连接,初始化资源
-
根据业务拼装一个SQL语句
-
通过连接执行SQL语句,并获得结果集
-
通过游标遍历结果集,取出每行数据,亦可从每行数据中取出属性数据
-
关闭数据库连接,回收资源
如果业务不复杂,这段代码写1次2次还可以,但如果业务越来越复杂,每次都这么获取数据,就略显低效了,有大量冗余、重复、每次必写的代码。
如何让数据的获取更加高效快捷呢?

通过技术手段实现:
-
表与类的映射
-
属性与成员的映射
-
SQL与函数的映射
绝大部分公司正在用的ORM,DAO等技术,就是一种分层抽象,可以提高数据获取的效率,屏蔽连接,游标,结果集这些复杂性。
结论
当手写代码从DB中获取数据,成为通用痛点的时候,就应该抽象出DAO层,简化数据获取过程,提高数据获取效率,向上游屏蔽底层的复杂性。
核心问题二:什么时候要进行数据服务层的抽象
抽象出DAO层之后,系统架构并不会一成不变:
-
随着业务越来越复杂,业务系统会不断进行垂直拆分
-
随着数据量越来越大,数据库会进行水平切分
-
随着读并发的越来越大,会增加缓存降低数据库的压力
于是系统架构变成了这个样子:
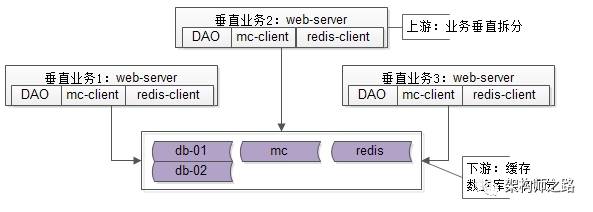
业务系统垂直拆分,数据库水平切分,缓存这些都是常见的架构优化手段。
此时,web-server层如何获取底层的数据呢?
根据楼主的经验,以用户数据为例,流程一般是这样的:
-
先查缓存:先用uid尝试从缓存获取数据,如果cache hit,数据获取成功,返回User实体,流程结束
-
确定路由:如果cache miss,先查询路由配置,确定uid落在哪个数据库实例的哪个库上
-
查询DB:通过DAO从对应库获取uid对应的数据实体User
-
插入缓存:将kv(uid, User)放入缓存,以便下次缓存查询数据能够命中缓存
如果业务不复杂,这段代码写1次2次还可以,但如果业务越来越复杂,每次都这么获取数据,就略显低效了,有大量冗余、重复、每次必写的代码。
特别的,业务垂直拆分成非常多的子系统之后:
-
一旦底层有稍许变化,所有上游的系统都需要升级修改
-
子系统之间很可能出现代码拷贝
-
一旦拷贝代码,出现一个bug,多个子系统都需要升级修改
不相信业务会垂直拆分成多个子系统?举两个例子:
-
58同城有招聘、房产、二手、二手车、黄页等5大头部业务,都需要访问用户数据
-
58到家有月嫂、保姆、丽人、速运、平台等多个业务,也都需要访问用户数据
如果每个子系统都需要关注缓存,分库,读写分离的复杂性,调用层会疯掉的。
如何让数据的获取更加高效快捷呢?
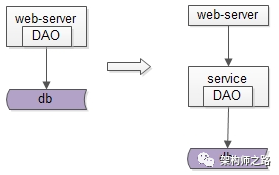
服务化,数据服务层的抽象势在必行。

通过抽象数据服务层:
-
web-server层可以通过RPC接口,像调用本地函数一样调用远端的数据
-
数据服务层,只有这一处需要关注缓存,分库,读写分离这些复杂性
服务化这里就不展开,更详细的可参考《互联网架构为什么要做服务化?》。
结论
当业务越来越复杂,垂直拆分的系统越来越多,数据库实施了水平切分,数据层实施了缓存加速之后,底层数据获取复杂性成为通用痛点的时候,就应该抽象出数据服务层,简化数据获取过程,提高数据获取效率,向上游屏蔽底层的复杂性。
互联网分层架构是一个很有意思的问题,服务化的引入,并不是越早越好:
-
请求处理时间可能会增加
-
运维可能会更加复杂
-
定位问题可能会更加麻烦
千万别鲁莽的在“微服务”大流之下,草率的进行微服务改造,看似“高大上架构”的背后,隐藏着更多并未接触过的“大坑”。还是那句话,架构和业务的特点和阶段有关:一切脱离业务的架构设计,都是耍流氓。
这一篇先到这里,分层架构,还有很多内容要和大家聊:
-
后端架构,是否需要抽取中台业务,什么时机抽取
-
后端架构,是否需要前后端分离,什么时机分离
-
前端架构,如何进行分层实践
末了,再次强调下,互联网分层架构的本质,是数据的移动。
互联网分层架构演进的核心原则,是让上游更高效的获取与处理数据,让下游能屏蔽掉数据的复杂性获取细节。














 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









