







先了解几个基本概率知识,不急着看蒙特卡洛方法的定义,具体的MC方法参考网上各种资料。
两个比较好的学习MC方法的文章:蒙特卡洛方法入门 (结合了实例)和 蒙特卡洛方法 (推荐,非常详细)
更新日志:2016-11-19,补充三个网站
从随机过程到马尔科夫链蒙特卡洛方法:http://www.cnblogs.com/daniel-D/p/3388724.html
MCMC: The Metropolis Sampler译文:http://www.cnblogs.com/yinxiangnan-charles/p/5018876.html
MCMC: The Metropolis Sampler原文:https://theclevermachine.wordpress.com/2012/11/19/a-gentle-introduction-to-markov-chain-monte-carlo-mcmc/
数学期望(期望,均值)的计算:
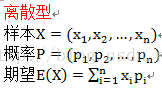

大数定律:
主要描述大数量随机试验平均结果的稳定性。解释了随机现象的一种统计规律。
具体定义参考书本。它主要是利用大量的随机试验,用观察值的平均值去预测整个样本的数学期望值。

当实验可重复,且次数n充分大时,伯努利大数定律表明用频率估计概率的误差可任意小,可靠性可任意大。辛钦大数定律表明用样本均值估计理论均值的误差可任意小,可靠性可任意大。
中心极限定律:
主要研究大数量独立随机变量和分布函数的极限,揭示了大量独立随机因素综合影响的一种统计规律。大量的相互独立的随机变量的线性组合在一定条件下近似服从正态分布的一系列定理称为中心极限定理。

蒙特卡洛方法:
先看一个式子

然后对比上面介绍的连续性数据的数学期望计算方法,是不是感觉特别像。蒙特卡洛方法又称为统计模拟法或者随机抽样技术,使用随机数(伪随机数)来解决很多计算问题的方法,将所求解的问题同一定的概率模型相联系,用计算机实现统计模拟或抽样,以获得问题的近似解。
依据:
大数定律:均匀分布的算术平均收敛于真值。
中心极限定理:置信水平下的统计误差。
基本原理:
某些事件的概率,可以用大量实验中该事件发生的频率估算,当样本的容量足够大时,可以认为该事件的发生频率即为其概率。
就拿计算圆周率π来说:主要过程就是给定一个圆和它的外接正方形,通过数学方法可以计算得到圆和正方形的面积比为π/4。然后用概率的方法,在正方形内(包括圆内)撒很多点,比如有N个点,数出撒到圆内的点数S,然后便可得到π/4=S/N,这样便可用概率的方法计算得到π的近似值,可以看出,这个近似值与N有关,N越大则越准确。回头看那个积分的式子,f(x)就代表这个圆,积分就代表面积,g(x)就代表这些点,p(x)就代表点在圆内的点数,即点落在圆里面的概率密度。















 9265
9265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











