









介绍
Vertica(属于HP公司),是一个基于DBMS架构的数据库系统,适合读密集的分析型数据库应用,比如数据仓库,白皮书中全名称为VerticaAnalytic Database。从命名中也可以看到,Vertica代表它数据存储是列式的,Analytic代表适合分析型需求,DB代表本身是数据库,支持SQL。
优势
和传统关系型数据库系统以及其他列式数据(仓)库相比,Vertica存在下面三点最关键的优势。
列存储
Vertica对磁盘上的数据采用列式存储,显而易见,列存储可以在数据读取的时候避免不需要的列,减少IO带宽,而且列存储配合压缩算法可以节省磁盘存储量。Vertica的列存储在压缩方面还有其优化之处,见下文。
AggressiveCompression
这个姑且理解为侵略性压缩好了。其实在压缩方面,Vertica针对不同的数据类型,采用了多种不同的压缩方式,让原本磁盘上大量IO开销与CPU的压缩工作达到比较好的tradeoff。压缩率大致是高达90%。此外,Vertica 的写数据和读数据是分开进行的,读的数据以压缩的状态存在磁盘上,写的数据先缓存在内存里,异步合并到磁盘上,这个下文还会提到。
多备份
由于压缩比率很高(90%),所以能够腾出足够的磁盘空间来做备份。这点很关键。首先,备份让Vertica具备容错性,且多机器上的备份还能提升ad-hoc查询性能。其次,能够通过备份来容错这点,区别了Vertica与传统数据库通过logging和二阶段提交这种方式来做容错的做法。而能做多备份的原因是由于其列存储压缩做的优化比较好,这点又是比其他列式存储的数据仓库有优势的地方。
table被拆分后存储的每个单元叫projection,每个projection按某个或某些attribute进行排序,而且不同的副本排序方式还会不同,所以这对查询又是有帮助的,这点下文也会提到。
当然,Vertica的压缩,面向列的存储以及table拆解后的存储对用户来说是透明的。Vertica对前端用户提供的是标准的SQL接口,而且兼容现有的ETL,reporting,BI工具,所以这点使得其他业务系统可以更方便迁移到Vertica上。
Vertica对硬件也没有特殊要求,可以跑在廉价的集群上,或是任何现成的linux机器上,使用本地磁盘做存储。
除了上面说的几点优势之外,Vertica还在性能,可扩展性,可用性以及使用便利性方面有以下优势。
shared-nothing,grid-based 数据库架构
Vertica可以高效的在普通的机器上扩容。事实上,在数据备份这块,Vertica提供k-safety的方式,k+1是备份数,可调,且每一份是完全的数据,后面会提到。
混合数据存储
这里的混合指的是内存和磁盘。一方面,新插入的数据是写入针对写做了优化的内存结构里,所以支持持续的,高性能的并发写入操作;另一方面,不影响实时的查询性能,因为读的数据来自于磁盘。事实上,写数据在内存里是乱序的,所以写吞吐会比较高,而读数据在磁盘上是有序的。
物理数据库设计工具
这说的是在使用Vertica的时候,提供了比较方便的工具,能帮助用户设计物理表,下文会提到。而且提供k-safety的机制保证容错。
高性能兼容ACID数据库
有轻量级的事务和并发控制scheme,针对查询和数据载入。并且具备基于k-safety的失败恢复模型,而不是传统的基于日志的。
方便的部署、监控、管理
略
架构
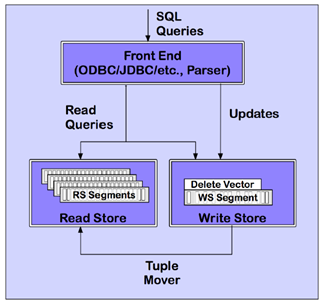
上图为Vertica单个节点的架构,我们看到查询和更新是走的所谓的混合存储,即write-optimizedstore(以下简称WOS)和read-optimized store(以下简称ROS)。WOS在内存里,对应数据写入,里面的数据不排序也不压缩。ROS是被排序和压缩过了的数据,存在磁盘上,提供了支持高效查询的格式。Tuple Mover负责把WOS的数据迁移到ROS上,以批的形式把WOS内存里的数据排序和压缩后移到ROS,即磁盘上,也是保证高效的。在WOS和ROS内部,数据都是面向列存的。
下面这张图展示了table存入到Vertica后,是怎么转变到物理存储的column形态的,即被切成了Projections。
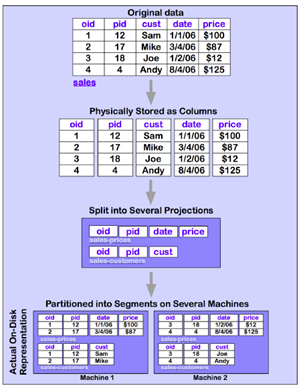
在切分成物理存储这点上,Vertica的Database Designer会帮助选择一个合理的切分方式,这是上面提到的使用上的便利性的优势,下文还会简单提到如何做到。
看上去,对每个projection在多机上冗余备份存储是种浪费磁盘的做法,但是Vertica的侵略性压缩提供了90%的压缩率,所以不用担心。
下面展示的是从WOS到ROS,Tuple Mover如何做数据合并的大致流程。

具体不详细解读,大致是异步和批量的做merge,而且projection是被纵向切成segments,会方便高效的归并。
性能
这一节稍微深入分析和对比下Vertica的性能优势。
列存储方面
对于普通的查询来说,主要是磁盘访问和cpu cycles占据的时间,哪个时间长就是查询时间,或者说是瓶颈。那列式存储的话,通过压缩来充分使用cpu资源,减少io开销,在cpu和io上做到比较合理的tradeoff,这点是Vertica一个很重要的优势。
其他数据库系统会通过支持物化views或data cubes,来减少某些查询场景下的时间,类似于做一些预计算和预处理来优化查询速度。但是这点对查询的场景支持有限,并且仍然不及Vertica提供的查询性能。
压缩方面
Vertica除了提供RLE(run-length encoding),还对连续的数据提供delta encoding和一个高效的LempelZiv实现,该实现很适合排过序的大多数值不相同的列数据,或未排序的数据。为浮点和时间数据提供特殊的压缩方式。
ROS方面
ROS本身的压缩和排序处理,使得磁盘上的数据查询比较高效。此外,ROS是dense packed不浪费disk pages。而传统数据库往往会让page留很多空,以便在不重新整理的前提下继续插入数据,磁盘空间利用率不是最高。ROS这部分工作是Tuple Mover异步做的,在归并阶段控制应该比较容易控制。在查询的时候,也会预读取查询量比较大的大块ROS。
排序方面
如前面提到,Vertica通过多备份来做HA和失败恢复,有别于传统数据库基于日志的失败恢复方式,写入过程相比Vertica的话代价更大些。此外,额外不同的排序方式加快了查询速度,Vertica也会选择最优的方式来做排序。
parallelshared-nothing on off-the-shelf hardware设计
不多说了,方便线性扩容,对硬件没特殊要求。
Vertica的一个benckmark,如下图。

管理
之前说的DB Designer会帮助使用者切分表,做比较好的物理存储选择,原理如下,
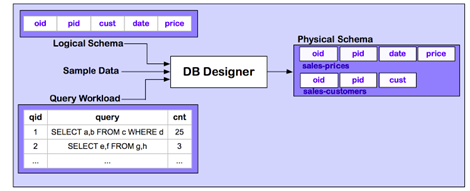
它参考逻辑schema,样本数据和query语句三个东西来做决策的。而且DB Designer能够增量地为数据库进行重新设计物理schema。
关于失败恢复和k-safety的HA保障再提几点。商业和传统数据库通过日志记录和二阶段提交保证事务性的方式来做失败恢复,回滚之类的事情,Vertica通过备份k+1份实现,只要有一台没有挂掉,就可以从它那全份拷贝恢复,容错性是高的,而且基于压缩率高,我们也不担心磁盘因此吃紧。这一点还让Vertica能够提供hot-swapping(热替换)节点,即比较方便地移除节点和新增节点。
传统数据库是record-at-a-time或bulk loading的方式来插入新数据,Vertica与此不同的是能够提供持续载入功能,查询的节点往往是以snapshot isolation的模式进行的,所以某种意义上是read-only的,因此在写入的时候也不用上锁。而且WOS里的数据不需要排序也不压缩,批量写入吞吐是比较高的。
总结
Vertica与传统数据库系统和其他列式数据仓库系统相比的话,在性能上有比较明显的优势,在设计上有一些异同,比较适合ad-hoc查询,OLAP类型的作业。总的来说,Vertica通过列存储减少了io开销,再加上高效的压缩手段,极大节省了磁盘空间,基于此Vertica采用多备份来保证高可用性,并且多备份又能够增强查询性能。在使用和运维角度了,Vertica自带工具帮助用户做物理表的存储,能提供标准SQL接口,也兼容现有的BI、ETL工具方便作业往Vertica上迁移,而且Vertica部署对硬件没有特殊要求,能够线性扩展。
全文完 :)














 886
886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









