







CTC(Connectionist temporal classification),可以理解为基于神经网络的时序类分类。
比如语音识别的一帧数据,很难给出一个label,但是几十帧数据就容易判断出对应的发音label。
语音识别声学模型的训练属于监督学习,需要知道每一帧对应的label才能进行有效的训练,在训练的数据准备阶段必须要对语音进行强制对齐。
CTC的引入可以放宽了这种一一对应的限制要求,只需要一个输入序列和一个输出序列即可以训练。
有两点好处:
1)、不需要对数据对齐和一一标注;
2)、CTC直接输出序列预测的概率,不需要外部的后处理。
CTC解决这一问题的方法是,在标注符号集中加一个空白符号blank,然后利用RNN进行标注,最后把blank符号和预测出的重复符号消除。比如有可能预测除了一个"--a-bb",就对应序列"ab"。这样就让RNN可以对长度小于输入序列的标注序列进行预测了。
RNN的训练需要用到前向后向算法(Forward-backward algorithm),对于给定预测序列,比如“ab”,在各个字符间插入空白符号,建立起篱笆网络(Trellis),然后对将所有可能映射到给定预测的序列都穷举出来求和。
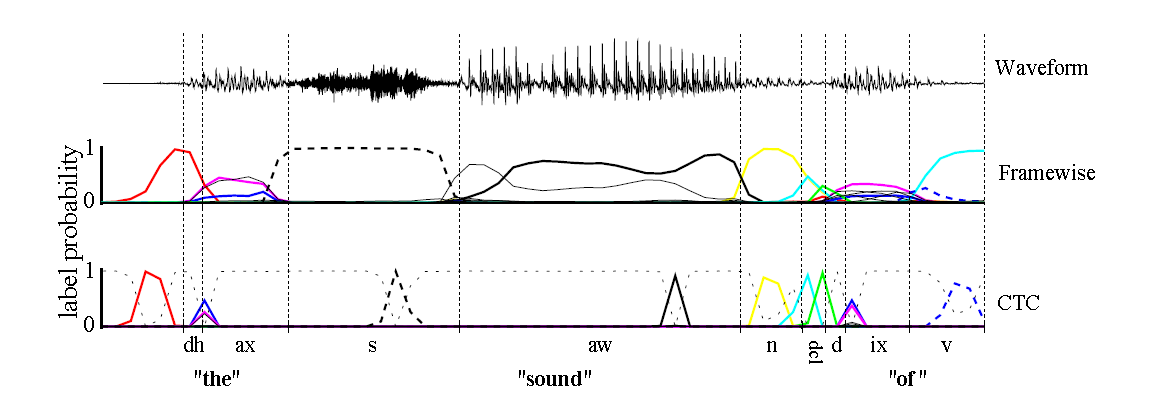
如上图,传统的Framewise训练需要进行语音和音素发音的对齐,比如“s”对应的一整段语音的标注都是s;而CTC引入了blank(该帧没有预测值),“s”对应的一整段语音中只有一个spike(尖峰)被认为是s,其他的认为是blank。对于一段语音,CTC最后的输出是spike的序列,不关心每一个音素对应的时间长度。














 3957
3957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









