







检索模型
搜索结果排序是搜索引擎的核心,排序时最重要的两个因素就是:用户查询和网页的内容相关性及网页链接情况。
检索模型就是用来计算内容相关度的理论基础及核心组件。
一个典型的检索模型通常由三部分组成:查询的表示、文档的表示、以及一个检索函数(基于查询和文档各自的表示,显式或隐式的估计两者相关的可能性)。
注意:检索模型理论研究存在理想化的隐形假设,即假设用户需求已经通过查询非常清晰的被表达出来,这与事实不符。是搜索引擎目前重点转向填补用户真实需求和发出的查询词之间的鸿沟的原因。
布尔模型(Boolean)
布尔模型的数学基础是集合论。
I. 文档及查询表示
布尔模型中,文档与用户查询由其包含的单词集合来表示;
II. 相似性计算
两者的相似性通过布尔代数运算(与或非)进行判定。
简单直观,但无法根据相关性程度进行排序,搜索结果过于粗糙。
向量空间模型(Vector Space Model)
I. 文档表示
向量空间模型把每个文档表示成一个t维的向量,这t维特征可以是单词、词组、N-gram片段等,最常用的是单词。每个特征会计算相应的权重,这t维带有权重的特征共同构成了一个文档,用于表示文档的主题内容。
实际系统中的维度非常高,成千上万。
II. 特征权重计算
文档和查询转换为特征向量时,每个特征(即单词)会赋予权值,一般采用TF-IDF框架计算权值。
词频因子(TF)–局部(一个文档)
代表词频:即一个单词在一个文档中出现的次数。一般在文档中反复出现的单词往往反映主题,故一个单词的出现频率越高,相应权值越高。
计算公式有多种变体,最简单的就是直接利用词频数作为TF值。一种词频的变体公式是:Wtf=1+log(tf)。数字1用于平滑,log机制用于抑制过大差异。
另一种:Wtf=a+(1-a)*[ tf / Max( tf ) ]。a为调节因子;这被称为增强型规范化Tf。
逆文档频率因子(IDF)–全局(文档集合)
衡量不同单词对文档的区分能力。反映了一个特征词在整个文档集合中的分布情况,特征词出现过的文档数目越多,IDF值越低,这个词区分不同文档的能力越差。
计算公式:IDF=log(N/n)。N代表文档集合中的文档总数,n代表特征词在其中多少文档中出现过。
TF*IDF框架
Weight(word)=TF*IDF
III. 相似性计算
向量空间模型以查询和文档之间的内容相关性来作为相关性的替代,按照文档和查询的相似性得分从高到低排序作为搜索结果,但是两者实际并不等同。
Cosine相似性计算定义如下:
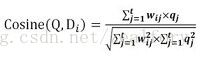
这个公式计算用户查询Q和Di文档的相似性,分子部分,将文档的每个特征权值和查询的每个特征权值相乘取和,这个过程也叫做求两个向量的点积;分母部分是两个特征向量在欧氏空间中长度的乘积,作为对点积计算结果的规范化(对长文档的惩罚机制)。
概率检索模型(probability model)
概率检索模型基于概率排序原理,是目前效果最好的模型之一,okapi BM25这一经典概率模型计算公式已经在商业搜索引擎的网页排序中广泛应用。
I. 概率排序原理
基本思想:给定一个用户查询,若搜索系统能在搜索结果排序时按照文档和用户查询的相关性由高到低排序,那么这个搜索系统的准确性是最优的。
II. 实际实现
- 根据用户的查询将文档集合划分为两个集合:相关文档子集和不相关文档子集。
- 将相关性衡量转换为分类问题,对某个文档D来说,若其属于相关文档子集的概率大于属于不相关文档的概率,就认为它与查询相关。
另P(R|D)代表给定一个文档D对应的相关性概率,而P(NR|D)代表该文档的不相关概率,若P(R|D)>P(NR|D)我们就认为此文档与查询相关。
根据贝叶斯定理(详见贝叶斯公式推导及意义),最终等价于计算:
P(R|D)/P(NR|D)
搜索系统无需分类,只需将文档按照上式大小降序排列即可。
III. 估值公式
基于二元独立模型(BIM)的二元假设和词汇独立性假设,得到最终的相关性估算公式:
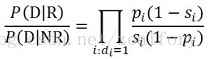
其中pi代表第i个单词在相关文档集合中出现的概率,si代表第i个单词在不相关文档集合中出现的概率。
取log便于计算:
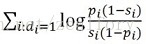
IV. BM25模型
BIM模型只考虑了单词是否在文档中出现过,而未考虑单词的权值。BM25模型在其基础上考虑了单词在查询中的权值及单词在文档中的权值,拟合出综合公式, 并通过实验引入了一些经验参数。
计算公式:
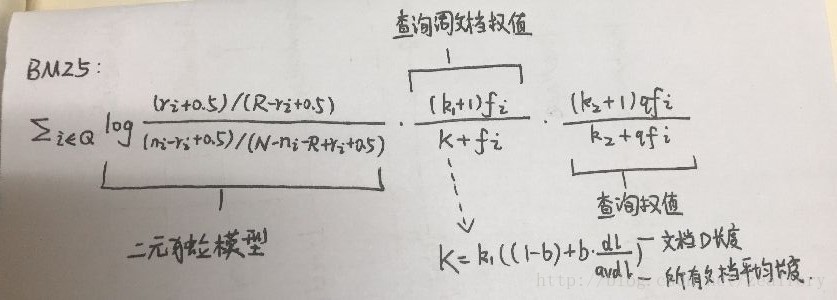
上式考虑了:IDF因子、文档长度因子、文档词频和查询词频,并利用3个自由调节因子(k1、k2和b)对各种因子的权值进行调整组合。
语言模型(Language Model)
基于统计语言模型的检索模型于1998年首次提出,借鉴了语音识别领域采用的语言模型技术。
一类最简单的语言模型与一个概率有穷自动机等价。
在一元语言模型中,词出现的先后次序无关紧要,因此,这类模型也往往称为词袋模型
I. 基本思想
区别于其他大多数检索模型从查询到文档(即给定用户查询,如何找出相关的文档),语言模型由文档到查询,即为每个文档建立不同的语言模型,判断由文档生成用户查询的可能性有多大,然后按照这种生成概率由高到低排序,作为搜索结果。
II. 生成查询概率
为每个文档建立一个语言模型,语言模型代表了单词(或单词序列)在文档中的分布情况。针对查询中的单词,每个单词都有一个抽取概率,将这些单词的抽取概率相乘就是文档生成查询的概率。
III. 存在问题
由于一个文档文字内容有限,所以很多查询词都未在文中出现过,生成概率为0,会导致查询整体的生成概率为0,这被称为语言模型的数据稀疏问题,是语言模型方法重点需要解决的问题。
IV. 解决方案
一般采用数据平滑方式解决数据稀疏问题。语言模型检索方法则是为所有单词引入一个背景概率做数据平滑。
文档生成查询概率的计算:
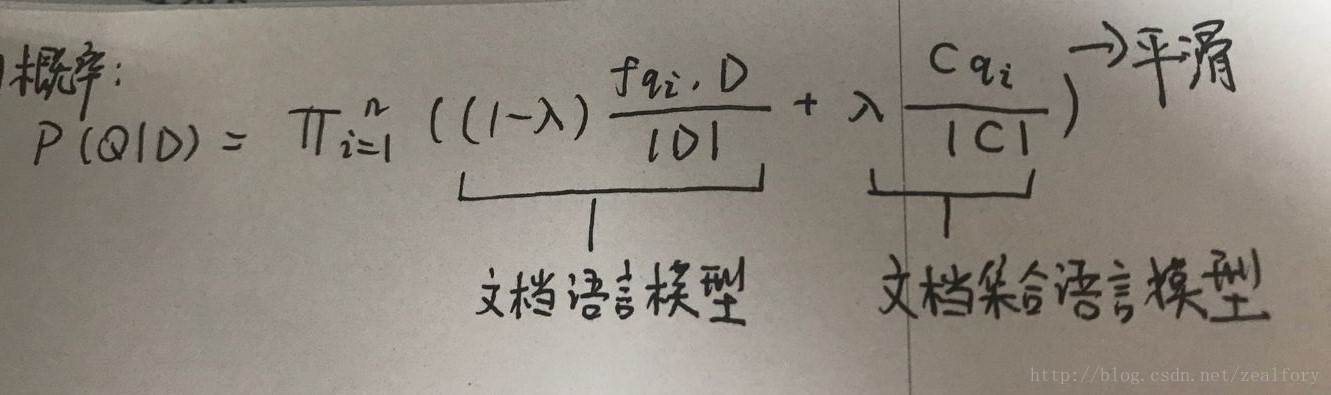
上式是加入数据平滑后的文档生成查询概率计算公式,每个查询词的生成概率由两部分构成,一部分是文档语言模型,另一部分是用做平滑的文档集合语言模型,两者间通过参数调节权重。
V. 查询似然模型(query likelihood model)
对文档集中的每篇文档d 构建其对应的语言模型Md。目标是将文档按照其与查询相关的似然P(d|q)排序。
最普遍的计算P(d|q)的方法是使用多项式一元语言模型,该模型等价于多项式朴素贝叶斯模型,其中这里的文档相当于后者中的类别,每篇文档在估计中都是一门独立的“ 语言” 。
在基于语言模型(简记为LM)的检索中,可以将查询的生成看成一个随机过程。具体的方法是:
(1) 对每篇文档推导出其LM;
(2) 估计查询在每个文档di 的LM 下的生成概率P(q|Md)
(3) 按照上述概率对文档进行排序。
机器学习排序(Learning to Rank)
利用机器学习技术对搜索结果进行排序近年来很热门,机器学习更适合采用很多特征来进行公式拟合,例如Google目前的网页排序公式考虑了200多种因子。而且大量的用户点击数据可用来训练机器学习系统。
I. 基本思想
与传统的人工拟合排序公式不同,机器学习排序中,最合理的排序公式是由机器自动学习获得的,而人只需给机器学习提供训练数据。
II. 实现步骤
1. 人工标注训练数据
2. 文档特征抽取
3. 学习分类函数
4. 在实际搜索系统中采用机器学习模型
III. 方法分类
1. 单文档方法(PointWise Approach)
2. 文档对方法(PairWise Approach)
3. 文档列表方法(ListWise Approach)














 5918
5918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









