







四、更新策略
互联网是实时变化的,具有很强的动态性。网页更新策略主要是决定何时更新之前已经下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面以往的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件能够返回数量巨大的结果,但是用户往往只关注前几页结果。因此,抓取系统可以优先更新那些现实在查询结果前几页中的网页,而后再更新那些后面的网页。这种更新策略也是需要用到历史信息的。用户体验策略保留网页的多个历史版本,并且根据过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的依据。
3.聚类抽样策略
尽管搜索引擎针对于某个查询条件能够返回数量巨大的结果,但是用户往往只关注前几页结果。因此,抓取系统可以优先更新那些现实在查询结果前几页中的网页,而后再更新那些后面的网页。这种更新策略也是需要用到历史信息的。用户体验策略保留网页的多个历史版本,并且根据过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的依据。
3.聚类抽样策略
前面提到的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一,系统要是为每个系统保存多个版本的历史信息,无疑增加了很多的系统负担;第二,要是新的网页完全没有历史信息,就无法确定更新策略。
这种策略认为,网页具有很多属性,类似属性的网页,可以认为其更新频率也是类似的。要计算某一个类别网页的更新频率,只需要对这一类网页抽样,以他们的更新周期作为整个类别的更新周期。基本思路如图:
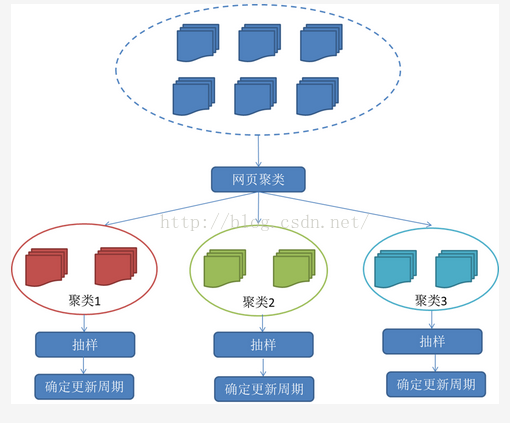
五、分布式抓取系统结构
一般来说,抓取系统需要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往需要多个抓取程序一起来处理。一般来说抓取系统往往是一个分布式的三层结构。如图所示::
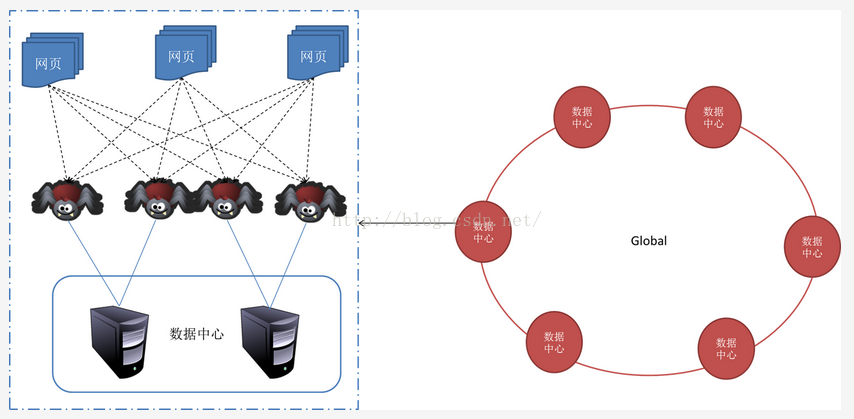
最下一层是分布在不同地理位置的数据中心,在每个数据中心里有若干台抓取服务器,而每台抓取服务器上可能部署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方式有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
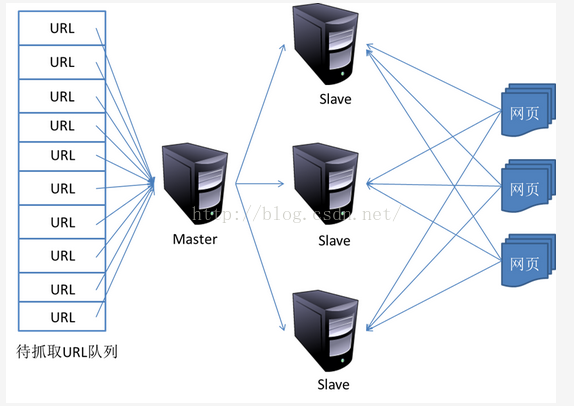
在这种模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后计算H mod m(其中m是服务器的数量,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL www.baidu.com,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器拿到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器死机或者添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方式的扩展性不佳。针对这种情况,又有一种改进方案被提出来。这种改进的方案是一致性哈希法来确定服务器分工。其基本结构如图所示:
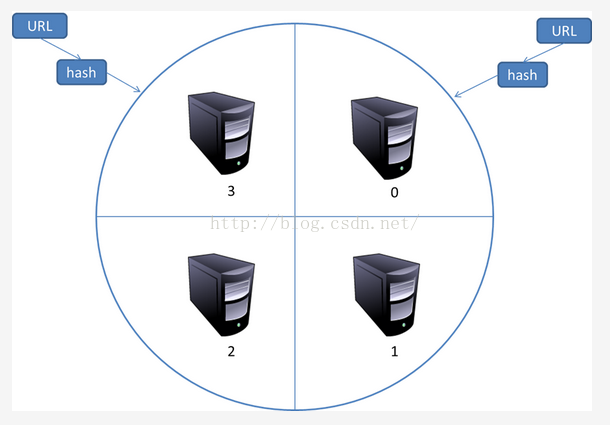
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-2
32之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判断是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则按照顺时针顺延,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。
参考书目:
1.《这就是搜索引擎——核心技术详解》 张俊林 电子工业出版社
2.《搜索引擎技术基础》 刘奕群等 清华大学出版社














 1316
1316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









