







阅读论文选自CVPR2014的一篇文章《Binarized Normed Gradients for Objectness Estimation at 300fps》,作者程明明。本文对该论文进行整理分析,主要基于原论文的结构,首先概括该小节的主要内容,再阐述个人的理解和分析。
摘要:使用objectness的方法生成小型的候选窗口(candidate object windows)集,可以加快经典的滑动窗口(sliding window)物体检测问题。有良好定义封闭边界的物体可以通过赋范梯度(the norm of gradients)进行区分。赋范梯度即将其图像窗口调整到较小的固定尺寸时每个像素的梯度。根据以上观察和计算方面的原因,本文将窗口调整到8×8并使用该尺寸下的像素梯度作为一个简单的64维的特征描述该窗口,来训练objectness方法。
本文进一步提出了以上特征的二进制版本,即二值化的赋范梯度(BING),可以用于高效的一般物体估计,并只需要很少的像素级的操作(如加、按位与、转换等)。实验在PASCAL VOC 2007数据集上进行,结果表明本文提出的方法可以高效地(在单核计算机上的速度是300fps)生成小型的类别独立的高质量的物体窗口,在1000个proposal的情况下物体检测的速率(DR)是96.2%。当增加proposal的数量和颜色空间时,物体检测的速率可以进一步提高到99.5%。
【理解分析】由摘要可以看出论文主要贡献是提出了一种加速方法,即可以加快经典的滑动窗口物体检测速率的方法。 该方法需要用到赋范梯度(NG)特征,之后作者又对NG进行加速优化,提出了二值化的赋范梯度(BING)特征。为了验证该加速方法的结果,在PASCAL VOC 2007数据集上进行实验,实验结果表明该方法的检测速率很高,加速优化效果明显。
1 引言
目前最先进的检测器仍需要使用特定类别的分类器,用滑动窗口的方法估计图像窗口。为了减少每个分类器的窗口数量,通用类别的objectness方法最近开始流行。Objectness是一个数值,它可以反映一个图像窗口包含所有类物体中的某一个物体的可能性。在预滤波的处理中,一般物体检测方法可以通过减少搜索空间显著地提高计算效率,通过在测试中使用强壮的分类器显著地提高检测的精确性。设计一个好的一般物体检测方法需要具备以下条件:
- 高的物体检测速率(DR)
- 少量的proposal
- 高的计算效率
- 好的通用特性
根据认知心理学和神经学的研究表明人类在识别物体之前可以先获取物体。人类视觉系统可以只在细节上处理一幅图片的小部分而几乎不处理余下的部分。这进一步表明了人类视觉系统有一个简单的机制可以选择可能存在的物体的位置。
本文提出的“BING”特征可以通过使用objectness得分检索物体。所有的工作都是基于物体是独立的具有良好定义的封闭边界和中心的且将物体所在的图片调整到较小的固定尺寸(如8×8)时通过赋范梯度观察时具有强大的相关性的事实。因此,为了高效地确定一个图像窗口的objectness,需要将该图像调整到8×8的尺寸。为了在级联的SVM框架中学习一般物体检测方法将赋范梯度(NG)作为一个简单的64维的特征。本文进一步提出了可以被用于高效地估计图像窗口的objectness的赋范梯度(NG)的二进制版本,即二值化赋范梯度(BING)特征,并只需要很少的像素级的操作(如加、按位与、转换等)。
实验在PASCAL VOC 2007数据集上进行,结果表明本文提出的方法可以高效地(在单核计算机上的速度是300fps)生成小型的类别独立的高质量的物体窗口,在1000个proposal的情况下物体检测的速率(DR)是96.2%。当增加proposal的数量和颜色空间时,物体检测的速率可以进一步提高到99.5%。BING特征比其他方法更简单而且快1000多倍,可以使用更小的proposal集合得到更好的检测速率(DR)。
【理解分析】目前,大部分的物体检测方法都是先学习大量的样本,获得学习结果,然后用不同的框遍历需要测试的图片,将遍历的框中内容依次与学习结果比对,然后确定框中是否存在此物体。然而,对于一幅N×N图像而言,要遍历所有可能的框,则其需要遍历的次数大约为N的4次方数量级。因此框的筛选是限制速度的主要因素。于是作者就提出了一种快速挑出候选框的方法。作者由好的一般物体检测方法需要具备的条件入手,受人体视觉系统的工作原理启发,提出了BING特征并说明了学习方法。实验结果表明作者提出的方法可以快速挑出候选框,加快物体检测速率。
2 相关工作
根据显著性的定义,本文将相关研究大致分为三个部分:定位预测、显著物体检测和objectness proposal 生成。
定位预测模型是为了预测人眼运动的显著点,但结果更倾向于强调边界和角点而不是整个物体。因此,这个模型并不适合用于物体检测生成proposal。
显著物体检测模型是为了检测场景中最能吸引注意力的物体,然而在有许多物体且没有物体占主导地位的复杂图像上不适用。
Objectness proposal生成是通过提出少量的(如1000个)独立分类的可能包含一幅图片中所有物体的proposal的方法。将粗略的分割作为物体proposal的方法是特定类别分类器减少检索空间的有效的方法。同时可以使用强分类器提高其精确性。但以上两种方法的计算成本都相当高,每幅图片需要耗时2至7分钟。本文提出的方法既简单又直观,通常情况下检测性能比其他方法好,而且比最流行的方法快1000多倍。
【理解分析】论文将相关工作分为三个部分,分别论述了三个部分的主要目的、相关方法和理论局限。经过比较后提出自己的方法,说明自己的方法的计算复杂度低、检测速率快。此外,论文还总结了其他可以降低计算成本的高效的滑动窗口物体检测方法,如Branch-and-bound、Approximate kernels和Efficient classifiers等。
3 方法
为了在一幅图片中找到一般物体,可以扫描一个预先定义的量化的窗口尺寸(尺度和横纵比)。每个窗口使用线性模型计分。使用非极大值抑制的方法从每个尺寸(36个)中挑选少量的proposal集合。因为某些尺寸(如10×500)比其他尺寸包括一个物体(如100×100)的可能性小,所以需要定义objectness分数。
【理解分析】由尺度的编号和窗口的坐标定位一个窗口的位置。线性模型和NG特征的内积即为该窗口的得分。因为不同尺度下的窗口的objectness标准应该是不同的,如10×500的窗口包含100×100的物体的可能性(objectness)小。于是加入校准项,即objectness分数。根据这个分数进行排序得到前k个proposal。
3.1 赋范梯度(NG)和objectness

图1中,尽管游轮和人在颜色、形状、纹理和光照方面有很大的不同,它们在赋范梯度空间有明显的相关性。为了利用以上观察结果来有效地预测物体的存在,本文中首先将输入图片调整到不同的量化尺寸并计算每幅重新调整尺寸后的图片的赋范梯度。在这些重新调整大小后的赋范梯度图中将8×8下的64维赋范梯度定义为其原窗口的赋范梯度(NG)特征。
赋范梯度特征对平移、尺度变换和横纵比变化不敏感,因此对于任意类别的物体检测都适用。而且赋范梯度可以被高效地计算和验证,很可能被用于实时应用。
【理解分析】本文的一大亮点就是发现了在固定窗口的大小下,物体与背景的梯度模式有所不同。如图1所示。图1(a)中绿框代表背景,红框代表物体。把这些框都调整成不同尺寸的固定大小,如图1(b)所示。本文选择8X8,然后求出8X8这些块中每个点的梯度,可以明显看到物体与背景的梯度模式的差别,物体的梯度分布呈现出较为杂乱的模式,而背景的较为单一和清楚,如图1(c)所示。其实这个道理很浅显,就是图像中背景区域往往呈现出相似的特性。个人认为这里不一定要用梯度,用其他一些统计特征甚至是图像特征都有可能得到类似的结果。
3.2 使用NG学习objectness检测
使用传统的两级级联SVM方法学习图像窗口的一般物体检测方法。
第一步,使用线性SVM学习一个单独模式w。分别使用肯定的和否定的训练样本训练绝对正确的物体窗口的赋范梯度特征和任意采样的背景窗口的赋范梯度特征。
第二步,通过使用线性SVM学习偏差项和学习系数可以估计训练图片的尺度,并将通过非极大值抑制挑选出来的proposal作为训练样本,它们的滤波器分数作为一维特征,使用训练图片的注释检查它们的标签。
【理解分析】这里使用两级级联的SVM方法学习,级联的SVM中第一级SVM对所有的候选窗口进行粗过滤,第二级SVM,则是对每一个size的窗口分别设计(也就是设计了36个不同的SVM),因为不同的size会是物体的概率是不一样的,正方形的窗口就更可能是物体,而8*256这种长条形的窗口就不太可能是。个人认为可以通过寻找更高速度的学习方法进行改进。
3.3 二值化赋范梯度(BING)
为了加快特征提取和测试处理,本文提出了赋范梯度(NG)的加快版本,即二值化的赋范梯度(BING)。线性模型w可以近似地用一组基表示,这组基一种有Nw个,基中的每个向量的64维都由0和1来表达。以1byte存储的赋范梯度(NG)可以近似地由这个字节的前Ng位表示。因此,一个64维的赋范梯度(NG)特征就可以由二值化的赋范梯度(BING)特征来表示。
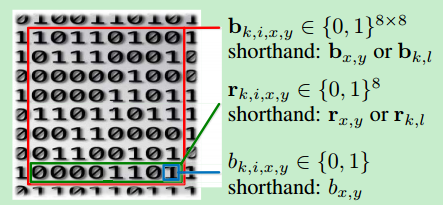
于是本文提出的方法可以在遍历固定的8×8区域时内使用少量的位操作做滑动而不是计算整个矩形区域中的所有值。
【理解分析】本文的另一大亮点是对NG特征进行二值化,即将数据进一步简化。梯度图的好处是能够完整的表征物体的形状,且数据量较小,因为其是单通道的图像,每位也是一个8位的unsigned char的数,舍去8位数据的后四位,选取数据的前四位代替其本身。这里,我分析里一下的这个舍去方法所可能产生的误差影响。假设某位像素的值为0001 1111(31),而舍去后四位后变成0001 0000(16),这种情况将是相对误差和绝对误差均为最大的情况。这里的相对误差为(31-16)/31=48.4%,绝对误差为15,。这些都是误差最大时的情况,而误差最小则为0。因此这些都是可以接受的,且在图像中也看不到很明显的特征, 这个数据减少的过过程为后面的位操作减少了一般的位移运算量。
4 实验评估
本文使用在VOC2007数据集上使用DR-#WIN作为评估标准与其他三种最好的方法:OBN、SEL和CSVM进行比较。
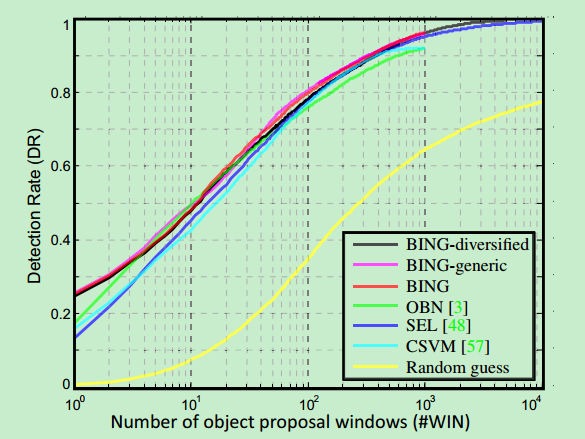
统计结果表明本文提出的方法在使用1000个proposal时可以获得96.2%的检测速率,使用5000个proposal时可以获得99.5%的检测速率。可以看出本文提出的方法比其他方法快3个数量级(1000多倍)。
本文使用6种类别的物体训练提出的方法,使用余下的14种物体进行测试。使用相同或不同类别的物体进行训练和测试分别用曲线BING和曲线BING-generic代表。实验结果表明这两种曲线的走向几乎完全相同,可以说明本文提出方法生成的proposal具有概括能力。
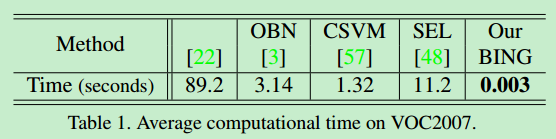
由表1可以看出,本文提出的方法可以在300fps以内提出几千个高质量的物体窗口。而其他的方法每幅图片就需要几秒钟的时间。

表2给出了在不同的时期(计算赋范梯度、提取BING特征和获取objectness分数)计算每个图像窗口的objectness时所需要操作的像素的个数。

表3说明了不同的近似值如何影响结果的质量。根据表3的结果在其他实验中设置Nw=2,Ng=4。
【理解分析】实验比较了生成的proposal的质量、生成的proposal的概括性、计算时间和每个图像窗口的objectness时所需要操作的像素的个数,并通过实验得出了DR最大时Nw和Ng的取值。
5 总结与展望
本文提出了一种简单快速高质量的一般物体检测方法,使用8×8的二值化赋范梯度(BING)特征在所有的尺度和横纵比下使用位操作计算每幅图片的objectness。使用VOC2007和DR-#WIN进行实验,结果表明本文提出的方法比其他广泛应用的方法性能更好,且运算速度比最流行的方法快3个数量级。
本文提出的方法可以预测少量的物体边框,但是物体边框无法精确的定位分段的区域,如蛇、绳子等。
未来工作可以进一步研究使用本文提出的方法在单一机器上实现实时数千物体类别的检测。还可以探索进步减少proposal数量而保持高的检测速率的方法。
【理解分析】本文提出的方法对于候选框的筛选方法很快,且其基于物体的闭合性这一性质,能够对几乎所有的物体进行预判,因此若想识别某一特定物体,则在获取候选窗口的时候,可以先用此法剔除大部分的窗口,得到少数的候选窗口,然后在将候选窗口的内容,送入分类器,进行区分,这样可以很大的提高效率。另外,因为此种方法中没有很多复杂图片操作,故可移植性比较强。且速度较快,则可以针对很多实时的场景进行实践。对于基于嵌入式的图像处理,运用此种方法可以加快处理速度,完成针对实时性的要求。并且,其关于位的操作,能够将嵌入式的硬件特性充分运用,即减少不必要的冗杂运算,使用尽可能最直接最有效的操作。然而,作者的准确的度量是用了VOC的检测的准则:intersection/union超过50%就算是正确。其实这个条件还算比较宽松的—–对VOC的检测问题来说,这个指标达到50%确实可以肯定检测的准确性,但是objectness只是用于检测的第一步,只有50%的 intersection/union还是较低,这对后面的recognition还是有些影响。所以,虽然本文的准确性达到了96.2%,其实光从准确性的方面来说,但还有很大的改进空间。而且因为只用了最弱的特征(梯度:相邻像素颜色相减的绝对值)和学习方法(LinearSVM),进一步对初步结果做分析,将1000个proposal降低到几百个,甚至几十个,并同时保持较高的recall,将会有很多工作可做。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









